- The paper provides a comprehensive framework combining a systematic literature review and experiments to evaluate ML energy consumption.
- It compares hardware sensor readings, analytical models, and data-driven estimation techniques across various ML tasks.
- Results highlight discrepancies among tools and emphasize the need for process-level energy attribution to enhance sustainability.
Evaluating the Energy Consumption of Machine Learning: Systematic Literature Review and Experiments
Introduction and Motivation
The proliferation of ML and AI workloads presents escalating challenges related to energy consumption and carbon footprint, necessitating rigorous methodologies to evaluate, monitor, and ultimately reduce energy usage. The reviewed paper conducts a comprehensive systematic literature review (SLR), mapping the methodologies and tools available for quantifying energy consumption in ML, spanning both training and inference phases. This inquiry is informed by the increasing scale of ML models, their deployment across diverse hardware (from data centers to edge devices), and the absence of universally reliable energy measurement instrumentation for heterogeneous platforms.
Systematic Literature Review Protocol and Execution
The core methodological contribution is the structured SLR protocol, leveraging queries across ACM Digital Library, IEEE Xplore, and Google Scholar, followed by a two-stage filtering/selection (semi-automatic then manual) to eliminate off-domain records (e.g., papers focused on non-ICT application domains or unrelated physical processes). Rigorous inclusion criteria ensure that selected studies either propose, validate, or empirically test energy measurement and estimation approaches specific to computational tasks, particularly ML.
Figures detailing this selection process (see below) depict the execution flow and progressive refinement of the candidate pool.
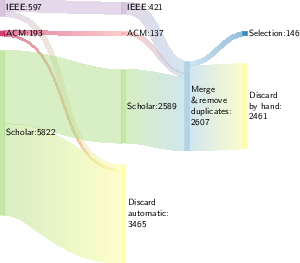
Figure 1: Execution of the protocol – part I, showing the sequential filtering from initial candidate papers to the first accepted pool.
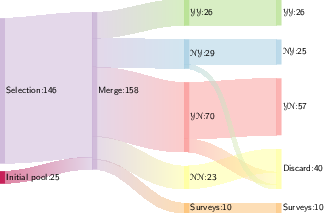
Figure 2: Execution of the protocol – part II, visualizing the subsequent manual selection leading to the final set for review.
Taxonomy of Energy Evaluation Techniques
The paper advances a clear taxonomy encapsulating the landscape of energy evaluation for computing:
- Measurement Approaches: Direct readings from external power meters (EPMs) or integrated hardware sensors; considered the baseline reference but often lacking granularity and scalability.
- Data-driven Estimation Models: Supervised learning (incl. regression, tree-based, neural) over performance counters, hardware specs, or application characteristics; require calibrated benchmarks and may struggle with portability across hardware architectures.
- Analytical Estimation Models: Formulas leveraging hardware specifications (e.g., TDP), counts of operations (MACs, FLOPs), or static code features; provide simplified but coarse estimates.
- On-chip Sensor Interfaces: Vendor-specific APIs (e.g., RAPL for Intel CPUs, NVML for Nvidia GPUs) exposing fine-grained, real-time metrics; widespread but constrained by hardware support and privileged access.
This ontology is illustrated in Figure 3.
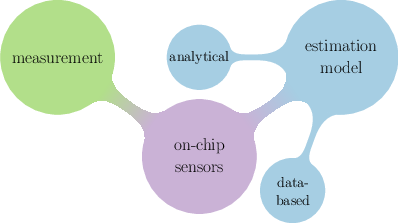
Figure 3: Taxonomy of energy evaluation techniques for computing tasks, showing distinctions among measurement, estimation, and sensor-based approaches.
Comparative Experimental Study
The paper supplements its literature review with a quantitative comparison of selected tools and methods across standardized ML tasks: training models on MNIST, CIFAR10, ImageNet (ResNet18), and fine-tuning BERT-base on SQuAD.
Tools operationalized include:
- CarbonTracker (CT): Both measurement and prediction modes, leveraging RAPL/NVML.
- CodeCarbon (CC): Process-level, on-chip sensor-driven.
- Eco2AI: Mixed analytical/sensor, relies on utilization rates and NVML.
- GreenAlgorithms (GA): Purely analytical, TDP and user-declared utilization rates.
- FLOPs-based Analytical Model: Estimates based on theoretical operation count and hardware throughput.
- External Power Meter (EPM): Provides both total and dynamic (i.e., subtracting idle) power draw reference.
Energy consumption per epoch, stability across training runs, and process isolation capabilities are benchmarked. Notable findings include:
- On-chip sensor-based tools (CT/CC) align closely with external EPM dynamic readings for compute-intensive workloads (ImageNet, BERT), validating their utility except in heterogeneous/virtualized environments.
- Analytical models (GA default/auto, FLOPs) can over- or underestimate—GA def frequently overshoots due to assuming max hardware utilization; FLOPs method underestimates in vision contexts due to omission of non-compute power sinks.
- Methods relying on user or tool-reported utilization (GA auto, Eco2AI) are sensitive to sampling strategies and hardware activity outside the target process.
- Process-level isolation markedly improves attribution fidelity; e.g., CT and Eco2AI when compared to host-level measurements.
These experimental results are visualized in Figure 10.
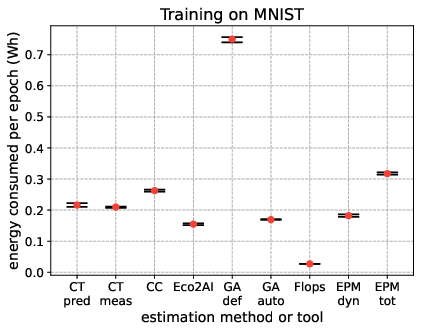
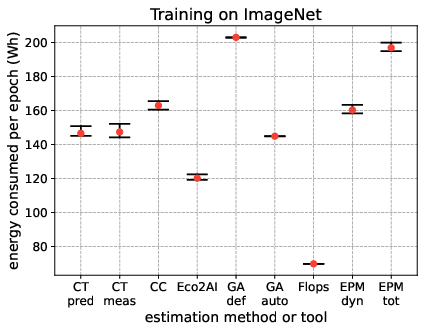
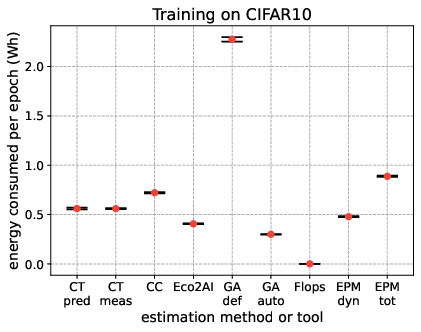
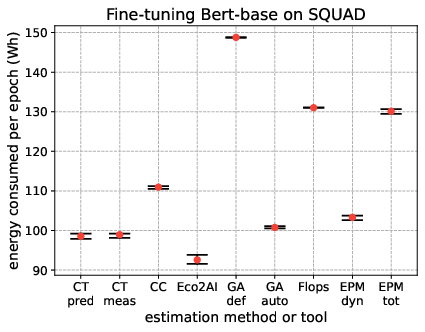
Figure 4: Energy consumed during 4 ML training tasks of different nature (vision and NLP) and computational complexity, showing differences among nine approaches.
Additionally, the study quantifies idle energy consumption (background power draw of hardware absent active computation), critical for distinguishing dynamic energy used by ML workloads, as illustrated in Figure 5.
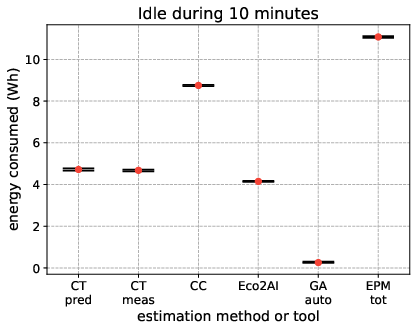
Figure 5: Idle energy consumed during 10 minutes, capturing baseline power unrelated to active ML computation.
Limitations, Contradictions, and Implications
Key contradictions emerge from the surveyed literature and experiments: some prior works report substantial divergence between on-chip sensor estimates and EPM ground truths, particularly for dynamic energy events, while others claim alignment subject to process isolation and recent sensor improvements. The paper itself finds significant differences between analytical approaches relying on default hardware utilization (e.g., GreenAlgorithms' default mode) and sensor-driven or reference measurements, reinforcing the necessity for context-appropriate tool selection.
Theoretical implications point toward a need for unified, hardware-agnostic methods capable of fine-grained, process-level energy attribution. On the practical side, open-source repositories and extensible protocols established in this work facilitate reproducibility and benchmarking across evolving ML/AI algorithms and hardware stacks.
Furthermore, the lack of consensus on the underlying accuracy and operation of proprietary on-chip interfaces (especially RAPL and NVML) remains an obstacle, motivating calls for transparent documentation and standardized reporting in ML evaluations.
Speculation and Outlook
As the deployment of large scale and edge ML accelerators continues, energy-aware benchmarking will become integral to both research and commercial operations, with some conferences already mandating reporting of computational resource usage. The development of hardware-abstracted, process-isolated, and dynamically adaptive measurement frameworks is anticipated, potentially integrating hybrid strategies (learning-based, analytical, and measurement) to address coverage gaps.
The reviewed experimental protocols and repositories foreshadow future community-driven comparative studies, extending beyond image and text domains to more heterogeneous applications (reinforcement learning, federated learning, multi-modal inference), and across increasingly disaggregated hardware—cloud VMs, ASICs, disaggregated accelerators.
The environmental and economic imperatives of ML computation suggest that progress in energy transparency will impact algorithmic design, hyperparameter optimization, and even resource scheduling, echoing nascent notions of "Green AI" counterbalancing the dominant "Red AI" paradigm.
Conclusion
This work provides an exhaustive mapping and empirical benchmarking of energy consumption evaluation practices for ML workloads, integrating taxonomic synthesis with open, extensible protocols and rigorous experimental validation. The findings signal the importance of selecting measurement and estimation tools grounded on deployment context, workload characteristics, and target granularity, and highlight open problems in accuracy and process attribution. The resources and methodologies disseminated here will support ongoing improvements in the energy efficiency of ML research and industry practice, contributing to a more sustainable computational paradigm (2408.15128).