- The paper introduces a novel MoE framework that upcycles dense models to integrate domain-specific experts with minimal computational cost.
- It employs an adaptive router using an MLP with SwiGLU activation to align domain and expert embeddings, improving specialization.
- Experimental results show up to 18.8% performance improvement when adding new experts, highlighting the framework's scalability and efficiency.
Nexus: Specialization meets Adaptability for Efficiently Training Mixture of Experts
This essay provides a technical summary of the paper "Nexus: Specialization meets Adaptability for Efficiently Training Mixture of Experts" (2408.15901). It discusses the methodologies, experimental results, and implications of the proposed Nexus framework for training Mixture of Experts (MoE) models with a focus on adaptability and efficiency.
Introduction
Nexus introduces an innovative approach combining specialization and adaptability in MoE architectures. The framework focuses on upcycling dense models into MoEs, allowing the integration of new experts with minimal computational costs. The core innovation lies in the adaptive router mechanism that leverages domain-specific embeddings to effectively manage expert specialization and extend capabilities to new domains, providing a significant advantage over traditional MoE models.
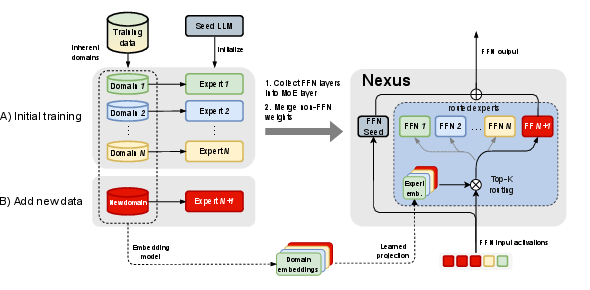
Figure 1: Depiction of Nexus for a single Transformer block highlighting the separate training of experts and adaptive routing mechanism.
Methodology
Adaptive Router
Nexus employs a novel adaptive router that projects domain embeddings into expert embeddings using a multi-layer perceptron (MLP) with SwiGLU activation. This mechanism ensures robust specialization by aligning input data with corresponding domain experts, effectively maintaining domain-specific knowledge.
1
2
3
4
5
6
7
|
def router(self, inputs, domain_embeddings):
expert_embeddings = self.domain_to_expert_ffn(self.domain_embeddings)
router_probs = nn.softmax(inputs @ expert_embeddings)
index, gate = nn.topk(1, router_probs)
routed_expert_out = self.routed_expert_ffns[index](input)
shared_expert_out = self.shared_expert_ffn(input)
return shared_expert_out + gate * routed_expert_out |
Figure: PyTorch-like pseudocode illustrating the router layer.
Upcycling Dense Experts
The framework initializes Nexus by upcycling specialized dense models into a unified MoE. Each expert in the MoE is derived from a dense model trained on a specific domain. The dense model's parameters are leveraged, facilitating efficient MoE initialization and retaining pre-trained capabilities.
Efficient Domain Adaptation
Nexus supports adding new domain experts post-initial training by computing the new expert's embedding using the learned projection. This adaptability is crucial for efficiently integrating new domains and improving performance without extensive retraining.
Experiments
Nexus demonstrates superior performance over traditional MoE models on various downstream tasks including knowledge retrieval, reasoning, and general understanding benchmarks. Specifically, it shows up to 2.1% performance gain in initial upcycling and an 18.8% improvement when extending with new experts.
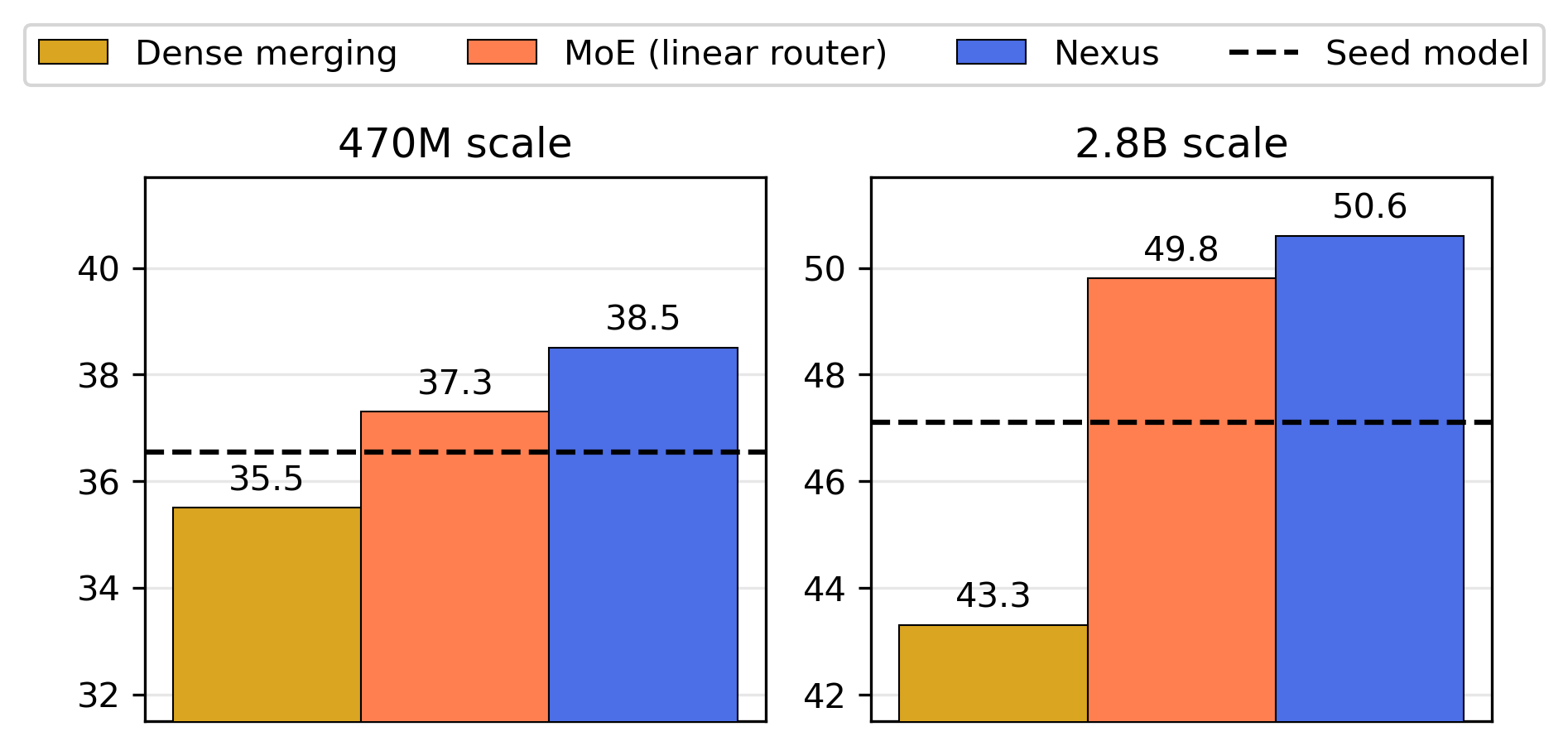
Figure 2: Downstream performance at different scales demonstrates Nexus's robust performance across multiple evaluation categories.
Expert Specialization
The adaptation mechanism effectively routes domain-specific inputs to the appropriate expert, as evidenced by the high specialization in routing probabilities. This specialization extends to newly added experts, ensuring that newly gained capabilities align with domain-specific inputs.
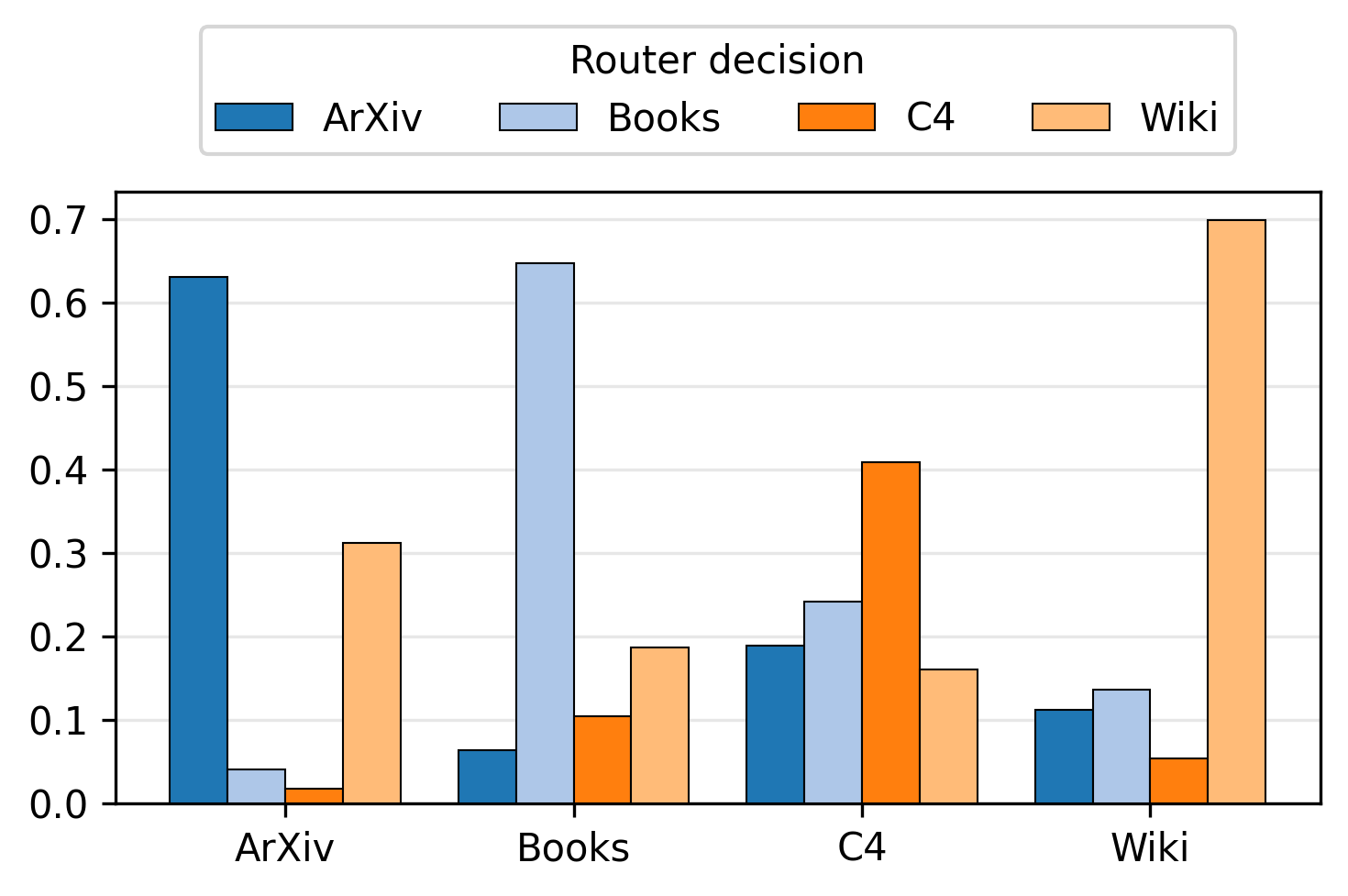
Figure 3: Average routing probabilities for each expert per domain in Nexus, indicating the model's ability to specialize efficiently.
Implications and Future Work
Nexus's framework offers significant improvements in adaptability and computational efficiency, setting a new standard for MoE model utilization. The approach enables dynamic expert integration, paving the way for bespoke LLM configurations tailored to specific application domains or newly emerging datasets.
In the future, advancements may include the development of automated methods to discover and incorporate new domain experts dynamically, further enhancing the adaptive capacity of Nexus. Additionally, exploring more effective router training strategies could enhance the scalability and precision of expert activation.
Conclusion
Nexus presents a compelling solution for specialized and adaptable LLMs, capitalizing on the unique strengths of MoE architectures while addressing previous limitations in expert integration and domain adaptability. The framework's robust performance, efficient resource use, and capacity for seamless integration of new domains make it a promising tool for future LLM development and deployment.