ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
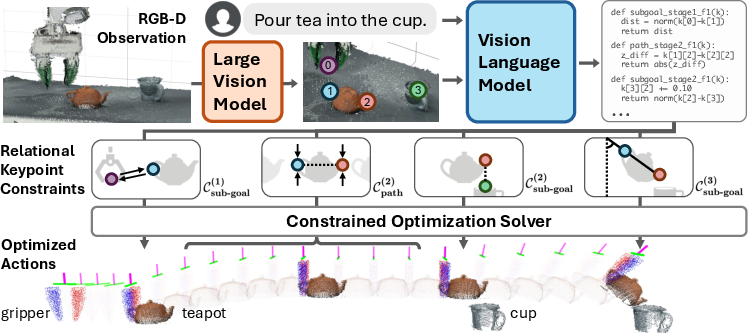
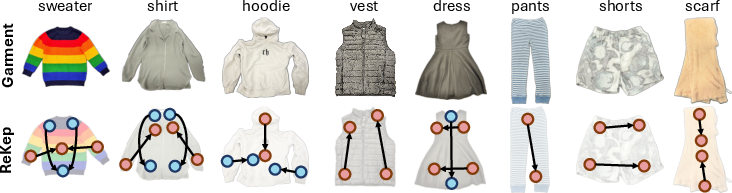
Abstract: Representing robotic manipulation tasks as constraints that associate the robot and the environment is a promising way to encode desired robot behaviors. However, it remains unclear how to formulate the constraints such that they are 1) versatile to diverse tasks, 2) free of manual labeling, and 3) optimizable by off-the-shelf solvers to produce robot actions in real-time. In this work, we introduce Relational Keypoint Constraints (ReKep), a visually-grounded representation for constraints in robotic manipulation. Specifically, ReKep is expressed as Python functions mapping a set of 3D keypoints in the environment to a numerical cost. We demonstrate that by representing a manipulation task as a sequence of Relational Keypoint Constraints, we can employ a hierarchical optimization procedure to solve for robot actions (represented by a sequence of end-effector poses in SE(3)) with a perception-action loop at a real-time frequency. Furthermore, in order to circumvent the need for manual specification of ReKep for each new task, we devise an automated procedure that leverages large vision models and vision-LLMs to produce ReKep from free-form language instructions and RGB-D observations. We present system implementations on a wheeled single-arm platform and a stationary dual-arm platform that can perform a large variety of manipulation tasks, featuring multi-stage, in-the-wild, bimanual, and reactive behaviors, all without task-specific data or environment models. Website at https://rekep-robot.github.io/.
- L. P. Kaelbling and T. Lozano-Pérez. Hierarchical planning in the now. In Workshops at the Twenty-Fourth AAAI Conference on Artificial Intelligence, 2010.
- Learning models as functionals of signed-distance fields for manipulation planning. In Conference on robot learning, pages 245–255. PMLR, 2022.
- Neural descriptor fields: Se (3)-equivariant object representations for manipulation. In 2022 International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2022.
- kpam: Keypoint affordances for category-level robotic manipulation. In The International Symposium of Robotics Research, pages 132–157. Springer, 2019.
- Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- OpenAI. Gpt-4 technical report. arXiv, 2023.
- Sequence-of-constraints mpc: Reactive timing-optimal control of sequential manipulation. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13753–13760. IEEE, 2022.
- L. P. Kaelbling and T. Lozano-Pérez. Integrated task and motion planning in belief space. The International Journal of Robotics Research, 32(9-10):1194–1227, 2013.
- Combined task and motion planning through an extensible planner-independent interface layer. In 2014 IEEE international conference on robotics and automation (ICRA), 2014.
- A. Byravan and D. Fox. Se3-nets: Learning rigid body motion using deep neural networks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 173–180. IEEE, 2017.
- An incremental constraint-based framework for task and motion planning. The International Journal of Robotics Research, 37(10):1134–1151, 2018.
- T. Migimatsu and J. Bohg. Object-centric task and motion planning in dynamic environments. IEEE Robotics and Automation Letters, 5(2):844–851, 2020.
- Integrated task and motion planning. Annual review of control, robotics, and autonomous systems, 4:265–293, 2021.
- Long-horizon manipulation of unknown objects via task and motion planning with estimated affordances. In 2022 International Conference on Robotics and Automation (ICRA), pages 1940–1946. IEEE, 2022.
- Megapose: 6d pose estimation of novel objects via render & compare. In Proceedings of the 6th Conference on Robot Learning (CoRL), 2022.
- 6-dof pose estimation of household objects for robotic manipulation: An accessible dataset and benchmark. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13081–13088. IEEE, 2022.
- Tax-pose: Task-specific cross-pose estimation for robot manipulation. In Conference on Robot Learning, pages 1783–1792. PMLR, 2023.
- Foundationpose: Unified 6d pose estimation and tracking of novel objects. arXiv preprint arXiv:2312.08344, 2023.
- Deepmpc: Learning deep latent features for model predictive control. In Robotics: Science and Systems, volume 10. Rome, Italy, 2015.
- A compositional object-based approach to learning physical dynamics. arXiv preprint arXiv:1612.00341, 2016.
- Interaction networks for learning about objects, relations and physics. Advances in neural information processing systems, 29, 2016.
- Graph networks as learnable physics engines for inference and control. In International Conference on Machine Learning, pages 4470–4479. PMLR, 2018.
- Grasp2vec: Learning object representations from self-supervised grasping. arXiv preprint arXiv:1811.06964, 2018.
- Deep object pose estimation for semantic robotic grasping of household objects. arXiv preprint arXiv:1809.10790, 2018.
- Densephysnet: Learning dense physical object representations via multi-step dynamic interactions. arXiv preprint arXiv:1906.03853, 2019.
- The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision. arXiv preprint arXiv:1904.12584, 2019.
- Monet: Unsupervised scene decomposition and representation. arXiv preprint arXiv:1901.11390, 2019.
- Learning-based model predictive control: Toward safe learning in control. Annual Review of Control, Robotics, and Autonomous Systems, 3:269–296, 2020.
- Object-centric learning with slot attention. Advances in neural information processing systems, 33:11525–11538, 2020.
- Visuomotor control in multi-object scenes using object-aware representations. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9515–9522. IEEE, 2023.
- Learning generalizable manipulation policies with object-centric 3d representations. arXiv preprint arXiv:2310.14386, 2023.
- Sornet: Spatial object-centric representations for sequential manipulation. In Conference on Robot Learning, pages 148–157. PMLR, 2022.
- Nod-tamp: Multi-step manipulation planning with neural object descriptors. arXiv preprint arXiv:2311.01530, 2023.
- What’s left? concept grounding with logic-enhanced foundation models. Advances in Neural Information Processing Systems, 36, 2024.
- Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. arXiv preprint arXiv:1810.01566, 2018.
- Planning with spatial-temporal abstraction from point clouds for deformable object manipulation. arXiv preprint arXiv:2210.15751, 2022.
- Dynamic-resolution model learning for object pile manipulation. arXiv preprint arXiv:2306.16700, 2023.
- Robocook: Long-horizon elasto-plastic object manipulation with diverse tools. arXiv preprint arXiv:2306.14447, 2023.
- Learning visible connectivity dynamics for cloth smoothing. In Conference on Robot Learning, pages 256–266. PMLR, 2022.
- Physically embodied gaussian splatting: A realtime correctable world model for robotics. arXiv preprint arXiv:2406.10788, 2024.
- Doughnet: A visual predictive model for topological manipulation of deformable objects. arXiv preprint arXiv:2404.12524, 2024.
- Self-supervised visual descriptor learning for dense correspondence. IEEE Robotics and Automation Letters, 2(2):420–427, 2016.
- Dense object nets: Learning dense visual object descriptors by and for robotic manipulation. arXiv preprint arXiv:1806.08756, 2018.
- Unsupervised learning of object keypoints for perception and control. Advances in neural information processing systems, 32, 2019.
- Keto: Learning keypoint representations for tool manipulation. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 7278–7285. IEEE, 2020.
- Learning rope manipulation policies using dense object descriptors trained on synthetic depth data. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9411–9418. IEEE, 2020.
- Keypoints into the future: Self-supervised correspondence in model-based reinforcement learning. arXiv preprint arXiv:2009.05085, 2020.
- Unsupervised learning of visual 3d keypoints for control. In International Conference on Machine Learning, pages 1539–1549. PMLR, 2021.
- Se (3)-equivariant relational rearrangement with neural descriptor fields. In Conference on Robot Learning, pages 835–846. PMLR, 2023.
- Robotap: Tracking arbitrary points for few-shot visual imitation. arXiv preprint arXiv:2308.15975, 2023.
- Local neural descriptor fields: Locally conditioned object representations for manipulation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 1830–1836. IEEE, 2023.
- Affordances from human videos as a versatile representation for robotics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023.
- Any-point trajectory modeling for policy learning. arXiv preprint arXiv:2401.00025, 2023.
- Track2act: Predicting point tracks from internet videos enables diverse zero-shot robot manipulation, 2024.
- Sampling-based methods for motion planning with constraints. Annual review of control, robotics, and autonomous systems, 1:159–185, 2018.
- Chomp: Gradient optimization techniques for efficient motion planning. In 2009 IEEE international conference on robotics and automation, pages 489–494. IEEE, 2009.
- Motion planning with sequential convex optimization and convex collision checking. The International Journal of Robotics Research, 33(9):1251–1270, 2014.
- Curobo: Parallelized collision-free robot motion generation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8112–8119. IEEE, 2023.
- Shortest paths in graphs of convex sets. SIAM Journal on Optimization, 34(1):507–532, 2024.
- Riemannian motion policies. arXiv preprint arXiv:1801.02854, 2018.
- Optimization and stabilization of trajectories for constrained dynamical systems. In 2016 IEEE International Conference on Robotics and Automation (ICRA), pages 1366–1373. IEEE, 2016.
- Discovery of complex behaviors through contact-invariant optimization. ACM Transactions on Graphics (ToG), 31(4):1–8, 2012a.
- Contact-invariant optimization for hand manipulation. In Proceedings of the ACM SIGGRAPH/Eurographics symposium on computer animation, pages 137–144, 2012b.
- A direct method for trajectory optimization of rigid bodies through contact. The International Journal of Robotics Research, 33(1):69–81, 2014.
- Predictive sampling: Real-time behaviour synthesis with mujoco. arXiv preprint arXiv:2212.00541, 2022.
- Model-based control with sparse neural dynamics. Advances in Neural Information Processing Systems, 36, 2024.
- Stable pushing: Mechanics, controllability, and planning. The international journal of robotics research, 15(6):533–556, 1996.
- Fast planning for 3d any-pose-reorienting using pivoting. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1631–1638. IEEE, 2018.
- Versatile multicontact planning and control for legged loco-manipulation. Science Robotics, 8(81):eadg5014, 2023.
- W. Yang and M. Posa. Dynamic on-palm manipulation via controlled sliding. arXiv preprint arXiv:2405.08731, 2024.
- Towards tight convex relaxations for contact-rich manipulation. arXiv preprint arXiv:2402.10312, 2024.
- Constraint propagation on interval bounds for dealing with geometric backtracking. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 957–964. IEEE, 2012.
- Efficiently combining task and motion planning using geometric constraints. The International Journal of Robotics Research, 33(14):1726–1747, 2014.
- T. Lozano-Pérez and L. P. Kaelbling. A constraint-based method for solving sequential manipulation planning problems. In 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3684–3691. IEEE, 2014.
- Compositional diffusion-based continuous constraint solvers. arXiv preprint arXiv:2309.00966, 2023.
- Learning symbolic operators for task and motion planning. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3182–3189. IEEE, 2021.
- Coast: Constraints and streams for task and motion planning. arXiv preprint arXiv:2405.08572, 2024.
- M. Toussaint. Logic-geometric programming: An optimization-based approach to combined task and motion planning. In Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015.
- M. Toussaint and M. Lopes. Multi-bound tree search for logic-geometric programming in cooperative manipulation domains. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 4044–4051. IEEE, 2017.
- Differentiable physics and stable modes for tool-use and manipulation planning. Robotics: Science and Systems Foundation, 2018.
- A probabilistic framework for constrained manipulations and task and motion planning under uncertainty. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 6745–6751. IEEE, 2020.
- D-lgp: Dynamic logicgeometric program for reactive task and motion planning. arXiv preprint arXiv:2312.02731, 2023.
- Deep visual heuristics: Learning feasibility of mixed-integer programs for manipulation planning. In 2020 IEEE international conference on robotics and automation (ICRA), pages 9563–9569. IEEE, 2020.
- Learning equality constraints for motion planning on manifolds. In Conference on Robot Learning, pages 2292–2305. PMLR, 2021.
- Sequence-based plan feasibility prediction for efficient task and motion planning. arXiv preprint arXiv:2211.01576, 2022.
- Learning deep sdf maps online for robot navigation and exploration. arXiv preprint arXiv:2207.10782, 2022.
- Toward general-purpose robots via foundation models: A survey and meta-analysis. arXiv preprint arXiv:2312.08782, 2023.
- Foundation models in robotics: Applications, challenges, and the future. arXiv preprint arXiv:2312.07843, 2023.
- Real-world robot applications of foundation models: A review. arXiv preprint arXiv:2402.05741, 2024.
- Foundation models for decision making: Problems, methods, and opportunities. arXiv preprint arXiv:2303.04129, 2023.
- Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- Zero-shot text-to-image generation. In International conference on machine learning, pages 8821–8831. Pmlr, 2021.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International conference on machine learning, pages 12888–12900. PMLR, 2022.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Copa: General robotic manipulation through spatial constraints of parts with foundation models. arXiv preprint arXiv:2403.08248, 2024.
- Moka: Open-vocabulary robotic manipulation through mark-based visual prompting. arXiv preprint arXiv:2403.03174, 2024.
- Pivot: Iterative visual prompting elicits actionable knowledge for vlms. arXiv preprint arXiv:2402.07872, 2024.
- Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning. arXiv preprint arXiv:2311.17842, 2023.
- Video language planning. arXiv preprint arXiv:2310.10625, 2023.
- 3d-llm: Injecting the 3d world into large language models. Advances in Neural Information Processing Systems, 36:20482–20494, 2023.
- Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024.
- Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973, 2023.
- Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
- Physically grounded vision-language models for robotic manipulation. arXiv preprint arXiv:2309.02561, 2023.
- Grounding language plans in demonstrations through counterfactual perturbations. arXiv preprint arXiv:2403.17124, 2024.
- Ns3d: Neuro-symbolic grounding of 3d objects and relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2614–2623, 2023.
- Physically grounded vision-language models for robotic manipulation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 12462–12469. IEEE, 2024.
- Robopoint: A vision-language model for spatial affordance prediction for robotics. arXiv preprint arXiv:2406.10721, 2024.
- Manipulate-anything: Automating real-world robots using vision-language models. arXiv preprint arXiv:2406.18915, 2024.
- Eyes wide shut? exploring the visual shortcomings of multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024.
- Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022.
- When and why vision-language models behave like bags-of-words, and what to do about it? In The Eleventh International Conference on Learning Representations, 2023.
- Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. Advances in neural information processing systems, 36, 2024.
- Emerging properties in self-supervised vision transformers. In Proceedings of the International Conference on Computer Vision (ICCV), 2021.
- Deep vit features as dense visual descriptors. arXiv preprint arXiv:2112.05814, 2(3):4, 2021.
- Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8364–8375, 2022.
- D3fields: Dynamic 3d descriptor fields for zero-shot generalizable robotic manipulation. arXiv preprint arXiv:2309.16118, 2023.
- Spawnnet: Learning generalizable visuomotor skills from pre-trained networks. arXiv preprint arXiv:2307.03567, 2023.
- N. Di Palo and E. Johns. Keypoint action tokens enable in-context imitation learning in robotics. arXiv preprint arXiv:2403.19578, 2024a.
- N. Di Palo and E. Johns. Dinobot: Robot manipulation via retrieval and alignment with vision foundation models. arXiv preprint arXiv:2402.13181, 2024b.
- Affordance-guided reinforcement learning via visual prompting. arXiv preprint arXiv:2407.10341, 2024.
- Array programming with NumPy. Nature, 585(7825):357–362, Sept. 2020. doi:10.1038/s41586-020-2649-2. URL https://doi.org/10.1038/s41586-020-2649-2.
- R. Tedrake. Underactuated Robotics. 2023. URL https://underactuated.csail.mit.edu.
- Scipy 1.0: fundamental algorithms for scientific computing in python. Nature methods, 17(3):261–272, 2020.
- Generalized simulated annealing algorithm and its application to the thomson model. Physics Letters A, 233(3):216–220, 1997.
- D. Kraft. A software package for sequential quadratic programming. Forschungsbericht- Deutsche Forschungs- und Versuchsanstalt fur Luft- und Raumfahrt, 1988.
- Automatic differentiation in pytorch. 2017.
- JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax.
- TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/. Software available from tensorflow.org.
- Anygrasp: Robust and efficient grasp perception in spatial and temporal domains. IEEE Transactions on Robotics, 2023.
- Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- E. Coumans and Y. Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning. 2016.
- Viola: Imitation learning for vision-based manipulation with object proposal priors. 6th Annual Conference on Robot Learning, 2022.
- Simple open-vocabulary object detection with vision transformers. arXiv preprint arXiv:2205.06230, 2022.
- Putting the object back into video object segmentation. In arXiv, 2023.
- Vision transformers need registers. arXiv preprint arXiv:2309.16588, 2023.
- D. Comaniciu and P. Meer. Mean shift: A robust approach toward feature space analysis. IEEE Transactions on pattern analysis and machine intelligence, 24(5):603–619, 2002.
- Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023.
- Particle video revisited: Tracking through occlusions using point trajectories. In European Conference on Computer Vision, pages 59–75. Springer, 2022.
- Tracking everything everywhere all at once. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19795–19806, 2023.
- Pointodyssey: A large-scale synthetic dataset for long-term point tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19855–19865, 2023.
- Cotracker: It is better to track together. arXiv preprint arXiv:2307.07635, 2023.
- Tapir: Tracking any point with per-frame initialization and temporal refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023.
- Bootstap: Bootstrapped training for tracking-any-point. arXiv preprint arXiv:2402.00847, 2024.
- Spatialtracker: Tracking any 2d pixels in 3d space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20406–20417, 2024.
- Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. arXiv preprint arXiv:2308.09713, 2023.
- nvblox: Gpu-accelerated incremental signed distance field mapping. arXiv preprint arXiv:2311.00626, 2023.
- Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024.
- Kinematic-aware prompting for generalizable articulated object manipulation with llms. arXiv preprint arXiv:2311.02847, 2023.
- A3vlm: Actionable articulation-aware vision language model. arXiv preprint arXiv:2406.07549, 2024.
- Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. In Conference on Robot Learning, pages 80–93. PMLR, 2023.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Rvt: Robotic view transformer for 3d object manipulation. In Conference on Robot Learning, pages 694–710. PMLR, 2023.
- Rvt-2: Learning precise manipulation from few demonstrations. arXiv preprint arXiv:2406.08545, 2024.
- An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.