- The paper demonstrates distinct internal representation patterns between few-shot learning and fine-tuning using a novel density-based analysis.
- It systematically measures intrinsic dimensions and semantic clustering in early layers versus fine-tuning effects in later layers across models.
- The findings highlight strategic layer-specific adaptations and the effectiveness of adaptive tuning techniques for enhanced LLM performance.
The Representation Landscape of Few-Shot Learning and Fine-Tuning in LLMs
Introduction to the Study
The analysis presented in "The Representation Landscape of Few-Shot Learning and Fine-Tuning in LLMs" examines the internal workings of LLMs under two prevalent training paradigms: in-context learning (ICL) and supervised fine-tuning (SFT). Despite achieving similar performance boosts, these two methods generate markedly different architectures within the models, particularly evident in how they solve the same question-answering tasks under varying conditions.
Distinct Representation Structures
In exploring the representation structures formed during ICL and SFT, the authors take a density-based approach without explicit dimensional reduction, allowing for a direct examination of the intrinsic probability modes of the data manifold. This contrasts with conventional methods utilizing low-dimensional projections. The sharp transitions observed mid-network are significant, highlighting a divergence in computational strategies employed by LLMs.
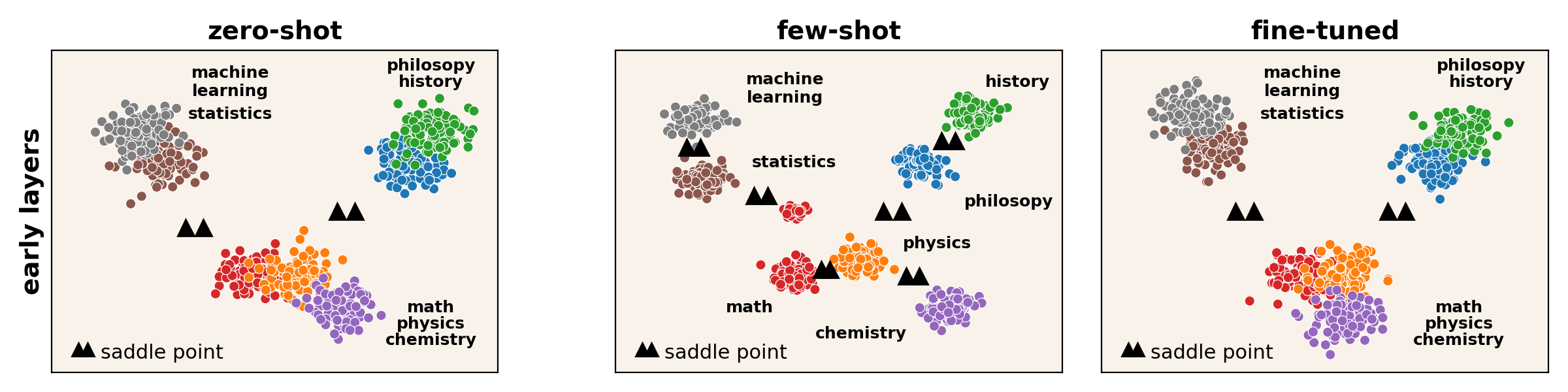
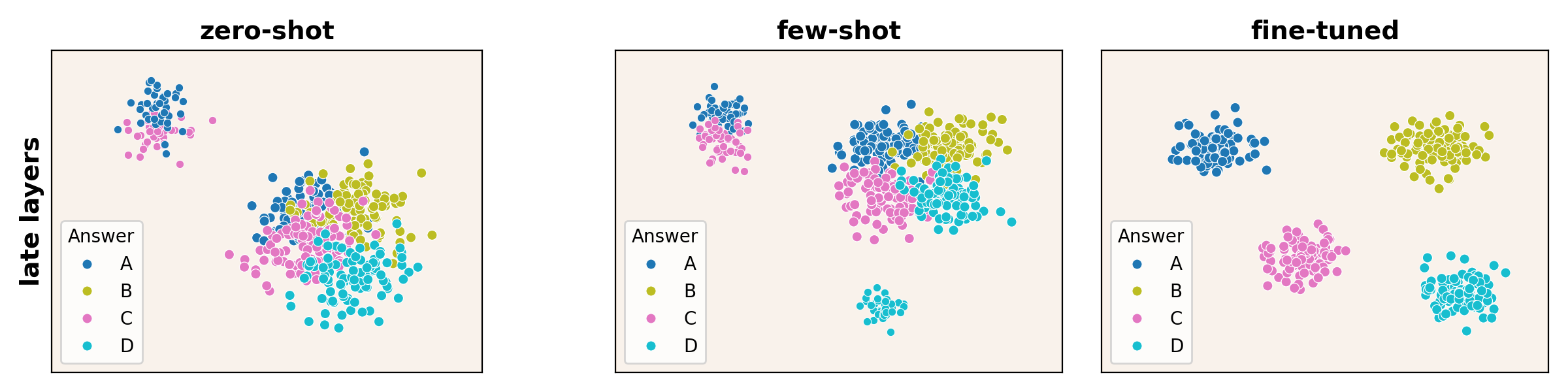
Figure 1: Consistency between the peak composition and the MMLU subjects. A schematic view of the density peaks in the early layers. The coloring reflects the presence of the subjects.
Geometrical Analysis of Data Representation
The research systematically measures intrinsic dimension (ID), number of probability modes, and density distributions across layers in Llama3 and Mistral models. These metrics consistently exhibit a two-phased behavior, with a pronounced peak in ID around the network's midpoint. This phase change suggests a fundamental restructuring in the approach models take toward semantic content processing and answer prediction.
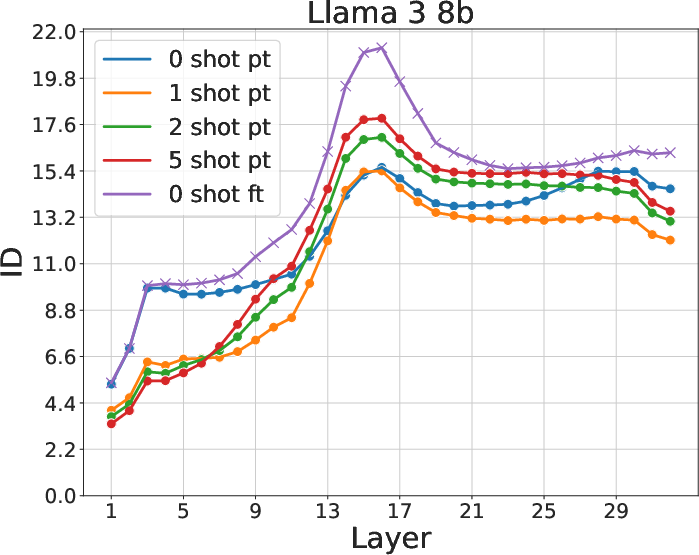
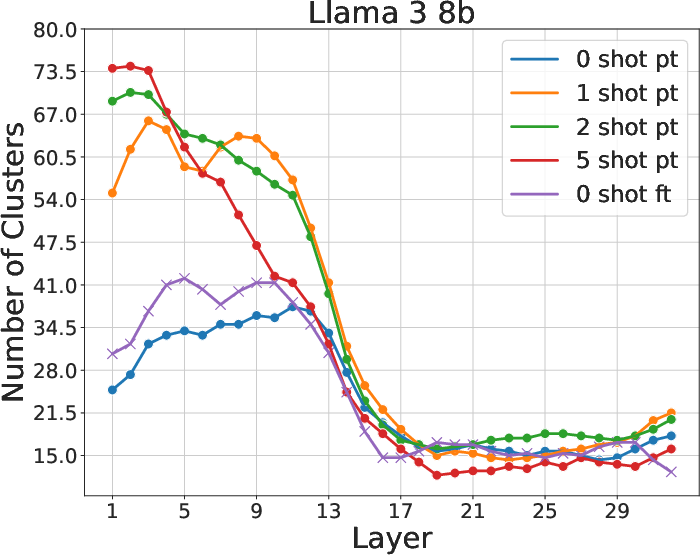
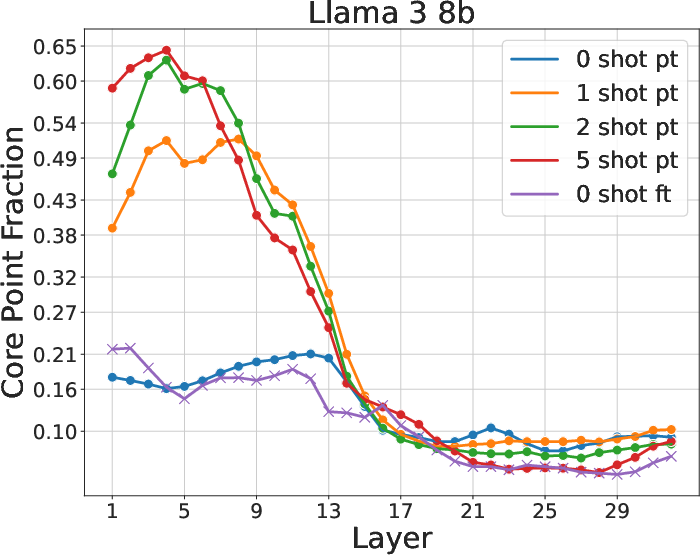
Figure 2: Intrinsic dimension, number of density peaks, and fraction of core points. Change in these quantities at layer 17 indicates a two-phased behavior.
Semantic Organization in Early Layers
The application of the Adjusted Rand Index (ARI) reveals that few-shot models form semantically consistent clusters at early layers, aligning with MMLU subjects. The presence of hierarchically coherent probability peaks confirms that early layers under ICL capture significant semantic relationships, a capability diminished in 0-shot and fine-tuned contexts.
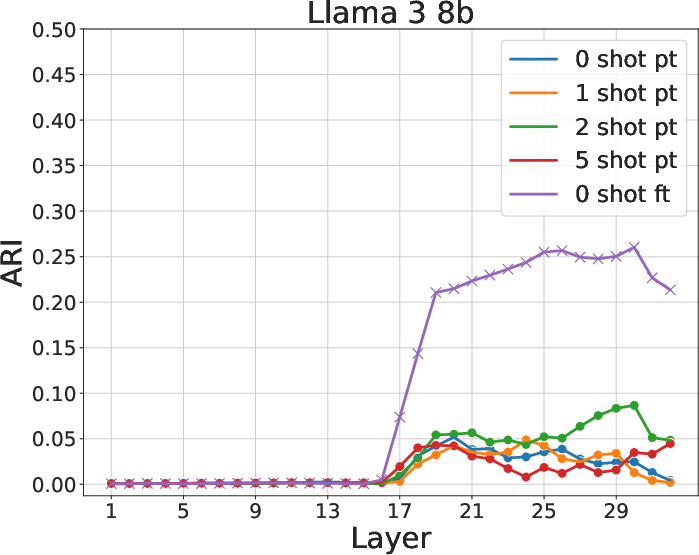
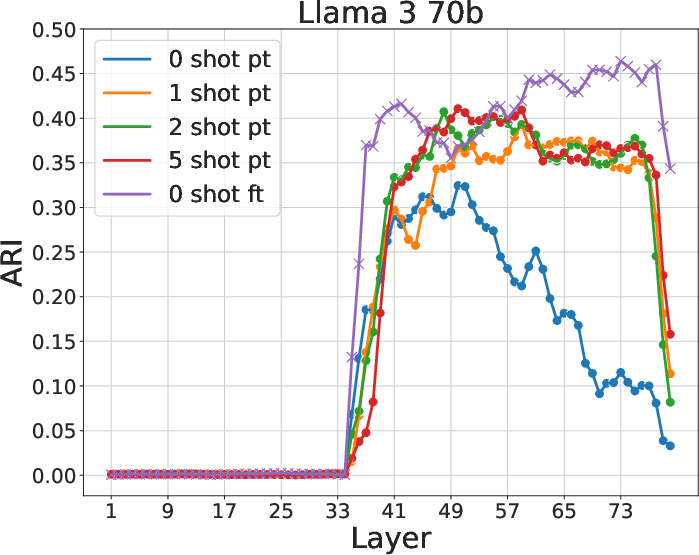
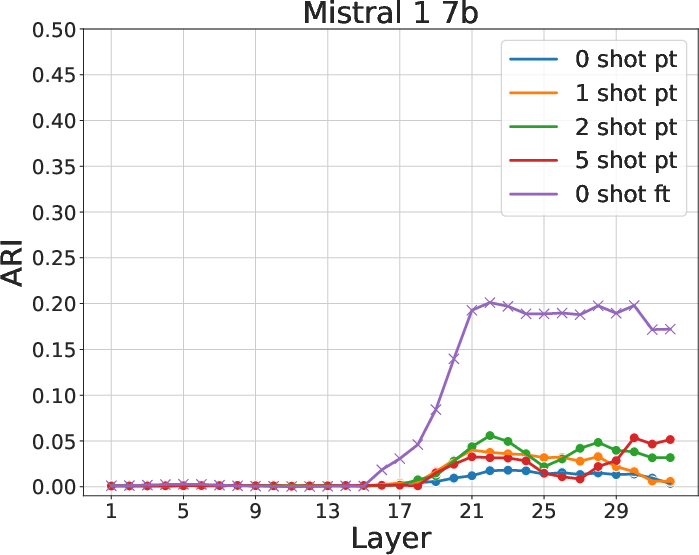
Figure 3: ARI between clusters and subjects for various models and contexts. Few-shot learning yields higher ARI, indicating better semantic clustering.
Influence of Fine-Tuning on Late Layers
In contrast, SFT effectively sharpens density peaks in later layers, aligning them more closely with correct answers. This structural modification is not as pronounced in ICL, except in models of larger scale and higher accuracy. The regional specificity of these changes suggests strategic layer-wise adaptability to task demands during SFT.
Figure 4: ARI between clusters and MMLU answers. Fine-tuned models, particularly in the latter layers, closely align clusters with expected answer partitions.
Transition Dynamics and Model Adaptation
Further dynamics are investigated through representation similarity metrics, outlining significant alteration in representations post-transition. Fine-tuning predominantly influences layers tasked with answer-generating processes, reinforcing the necessity for adaptive methods that balance early semantic abstraction with late-stage specificity.
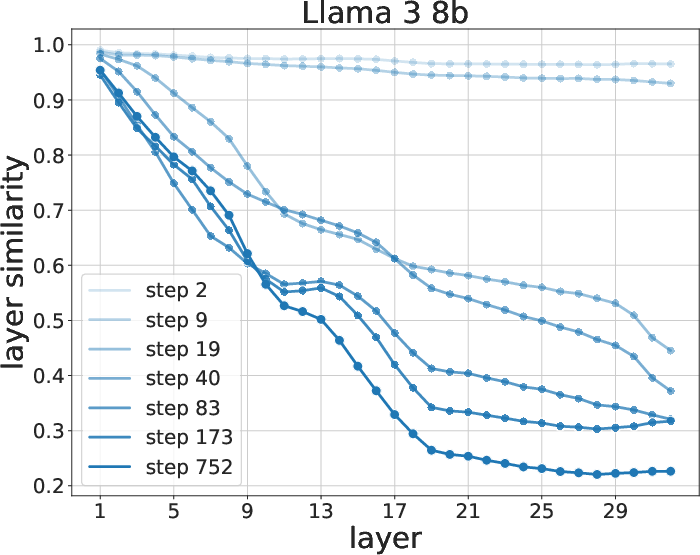
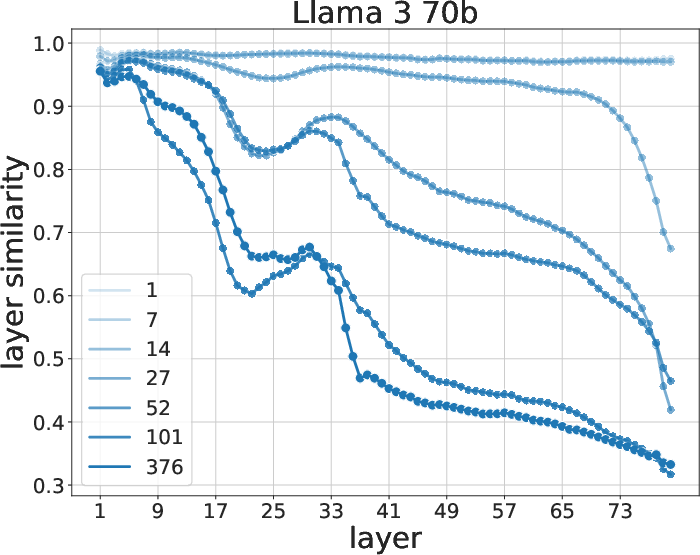
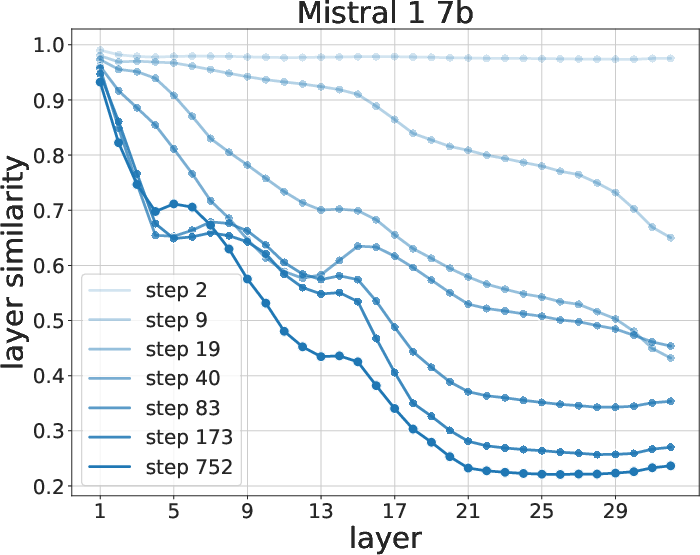
Figure 5: Similarity evolution between 0-shot and fine-tuned models during training. Late representations exhibit the most change.
Conclusion
The study delineates distinct operational pathways within LLMs leveraging ICL and SFT, spotlighting the potential to refine adaptive tuning strategies such as LoRA within these paradigms. By emphasizing the role of density-based clustering in revealing intrinsic geometric properties, this work provides a robust framework for understanding and manipulating the internal mechanics of LLMs in various training conditions. The insights gleaned not only enhance model design aimed at optimal performance across learning tasks but also inform future developments in adaptive AI systems.