- The paper presents FlowSep’s key contribution by leveraging Rectified Flow Matching to accurately isolate audio sources based on natural language queries.
- It introduces a novel architecture combining FLAN-T5, VAE, and BigVGAN to convert textual commands into high-fidelity audio waveforms.
- Evaluations demonstrate that FlowSep achieves superior performance with reduced artifacts and improved metrics such as FAD and CLAPScore.
Language-Queried Sound Separation and FlowSep Architecture
This paper explores the development and application of FlowSep, a novel generative model for Language-Queried Audio Source Separation (LASS) using Rectified Flow Matching (RFM). The FlowSep model uniquely leverages RFM to improve the separation of audio sources queried through natural language, demonstrating significant improvements over conventional methods.
Introduction to Language-Queried Audio Source Separation
LASS extends traditional audio source separation by allowing users to specify audio sources to isolate through textual descriptions. However, current techniques face challenges when dealing with overlapping soundtracks, often resulting in artifacts such as spectral holes and incomplete separation. FlowSep adopts a generative approach using RFM to address these limitations, establishing linear trajectories between noise and target source features within a Variational Autoencoder (VAE) latent space. FlowSep's architecture is illustrated in Figure 1.
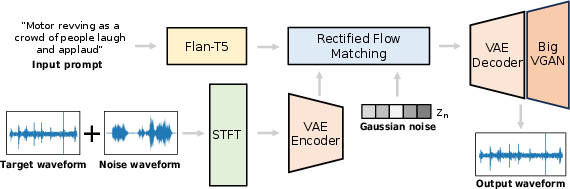
Figure 1: The architecture of FlowSep. FlowSep consists of four main components: (1) a FLAN-T5 encoder for text embedding; (2) a VAE for encoding and decoding mel-spectrograms; (3) an RFM module for generating audio features within the VAE latent space; (4) a BigVGAN vocoder to generate the waveform.
Methodology and Components of FlowSep
FLAN-T5 Encoder and VAE
FlowSep employs a FLAN-T5 encoder to process text queries, offering improvements over existing models such as AudioSep that use CLAP. The VAE encodes and decodes audio features, translating generated latent features into mel-spectrograms before a BigVGAN vocoder synthesizes the final waveform.
Rectified Flow Matching (RFM)
RFM predicts vector fields mapping pathways from noise to target features, optimizing linear trajectories that enhance separation quality and inference speed. Training loss functions, such as the Flow Matching Loss, facilitate learning these pathways with greater efficiency, notably outperforming diffusion-based methods.
Channel-Conditioned Generation
The separation process involves generating target audio features based on audio mixtures and textual input. As depicted in Figure 2, the channel-concatenation mechanism integrates conditions into the input channels, optimizing the generation of target latent vectors.
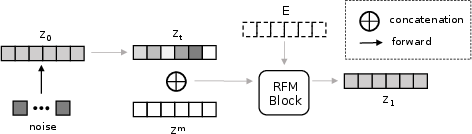
Figure 2: The channel-concatenation conditioning mechanism.
FlowSep was rigorously evaluated using objective metrics such as Frechet Audio Distance (FAD) and CLAPScore, along with subjective measures including relevance and overall sound quality. Table 1 illustrates FlowSep's superior performance across these metrics.
(Table 1)
Table 1: Objective evaluation metrics demonstrating FlowSep’s improvements over baseline models.
Case Studies and Results
Detailed case studies, such as those visualized in Figure 3, demonstrate FlowSep’s capability to closely replicate ground truth spectrograms. These illustrate the generative model’s effectiveness in achieving artifact-free separation, outperforming discriminative techniques such as those employed by AudioSep.

Figure 3: A case study of separation results on DE-S test set, as compared with the ground truth.
Conclusion
FlowSep represents a significant advance in audio separation technology, leveraging RFM to overcome the limitations of prior methods. The enhanced efficiency, quality, and applicability of FlowSep across diverse datasets underscore its potential for practical implementations in real-world scenarios. Future developments may focus on further optimizing inference processes and expanding the model's versatility in more varied acoustic environments.