- The paper redefines foundation models by juxtaposing their advanced reasoning capabilities with analogies from early neuroscience.
- It highlights that novel training phenomena like grokking drive near-perfect performance after extensive iterations.
- The study compares FMs with human brain architecture, emphasizing scalability, energy efficiency, and the need for robust benchmarking.
Understanding Foundation Models: Are We Back in 1924?
Introduction
The paper "Understanding Foundation Models: Are We Back in 1924?" explores the transformative developments in Foundation Models (FMs) within the field of AI, highlighting their influence on intelligence and reasoning capabilities. Specifically, the study contrasts the growth of FMs with early neuroscience, drawing parallels yet emphasizing fundamental differences in understanding and evaluating these models.
Evolution and Characteristics of Foundation Models
Foundation Models represent a significant leap in AI, characterized by training on vast datasets and leveraging embedding spaces to capture semantic relationships. Such models are statistical representations developed using extensive unannotated data streams, acquiring parametric memory through their sets of weights or parameters. The architecture primarily relies on Transformers, which compute vast amounts of data to produce sophisticated embeddings. For instance, GPT-4 is estimated to have a training set of 13 trillion tokens requiring 2.15×1025 FLOPs for computation—indicative of its enormous intelligence and reasoning potential.
Challenges in Benchmarking and Intelligence Assessment
The paper identifies critical challenges in benchmarking these models, often inadequately assessing reasoning and high-level knowledge representation. Unlike previous models, newer FMs demonstrate enhanced reasoning abilities not due to their size but because of novel training phenomena like grokking. This unexpected phenomenon indicates a transition from standard training to near-perfect performance after extensive iterations.
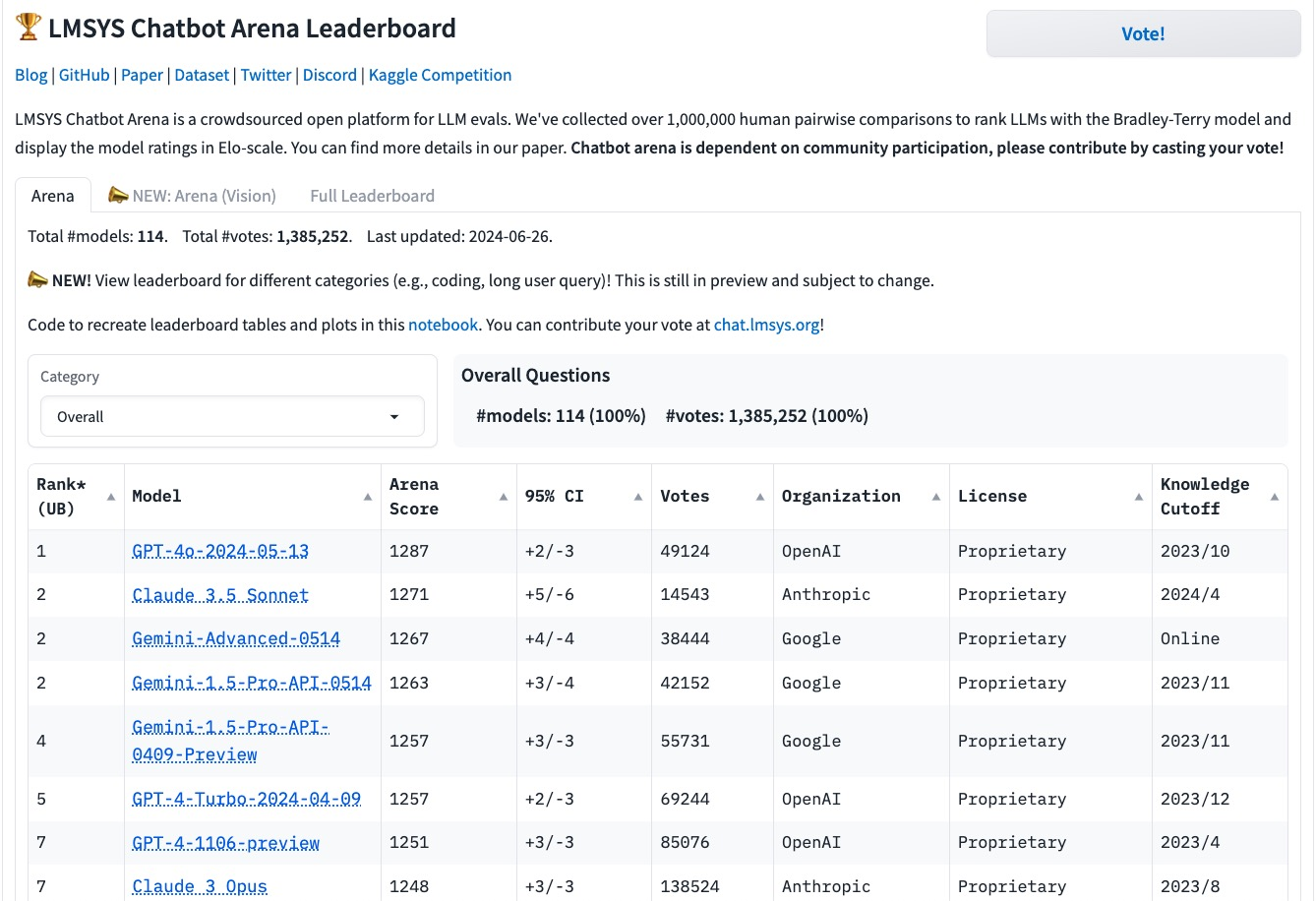
Figure 1: Screengrab from the Chatbot Arena crowd sourced evaluation platform, demonstrating human-in-the-loop evaluation.
Leet Speak and Reasoning Abilities
The paper uses "Leet Speak" as a metaphor to illustrate the evolving reasoning capabilities within FMs. Experiments showed that early models like GPT-3 required contextual cues to decode leet speak, while newer models like GPT-4 and Claude can decipher these forms independently, showcasing advanced reasoning not constrained by direct input-output mapping.

Figure 2: First fragment of text in Leet Speak.

Figure 3: Second fragment of text in Leet Speak.
Comparison to Human Brain Function
Analogies between FMs and human brain function present intriguing insights. While both systems exhibit complex network structures, significant differences exist. Human brains encompass approximately 86 billion neurons and 100 trillion synapses, while even the largest FMs possess only a fraction of these connections. Unlike FMs, the human brain adapts through neural plasticity and evolves synapses over time, continuously maintaining a homeostatic balance.
Implications and Future Developments
The paper suggests that while FMs are advancing towards more sophisticated forms of intelligence, understanding their inner workings remains an immense challenge comparable to early neuroscience efforts in understanding the human brain. Nonetheless, recent advancements indicate trends towards smaller models achieving impactful reasoning, suggesting a potential shift towards more energy- and space-efficient models.
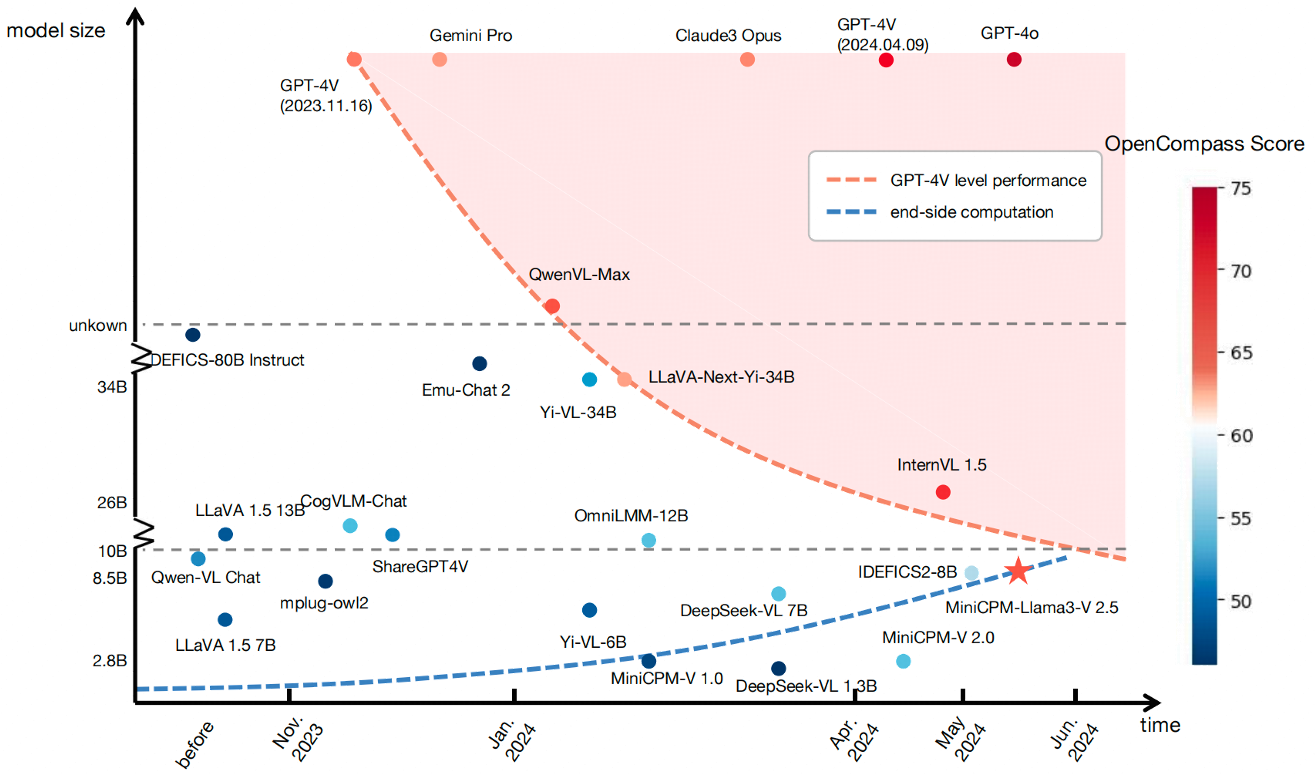
Figure 4: OpenCompass performance of a range of recently released LLMs measured against GPT-4V.
Conclusion
The research underscores the limited interpretability of FMs, with parallels drawn to historical neuroscience challenges. Despite the significant advancements in reasoning capabilities, much like the enigma of the human brain, the paper concludes that ongoing interdisciplinary exploration is crucial for unraveling the complexities of Foundation Models. These efforts will undoubtedly propel AI towards more efficient, adaptable, and potentially "intelligent" systems, albeit with a need for rigorous ethical oversight and responsible development practices in the field.