- The paper demonstrates how SSL-generated discrete tokens reduce WER, achieving up to a 1.76% improvement on test sets across multiple languages.
- The paper introduces an optimized Zipformer-Transducer model with advanced activation and normalization techniques to enhance multilingual ASR efficiency.
- The paper highlights significant training efficiency gains with discrete tokens, markedly decreasing per-epoch training time compared to traditional Fbank features.
Exploring SSL Discrete Tokens for Multilingual ASR
Introduction
The paper "Exploring SSL Discrete Tokens for Multilingual ASR" (2409.08805) explores the application of Self-supervised Learning (SSL) in generating discrete tokens for Automatic Speech Recognition (ASR), specifically targeting multilingual scenarios. Traditionally, ASR systems have relied heavily on Fbank features, but this approach explores discrete tokens for their processing speed and adaptability across languages. The study highlights numerical improvements in Word Error Rate (WER) using discrete tokens compared to traditional methods, demonstrating their efficacy in multilingual contexts. The central objective of this work is to explore the performance and efficiency of discrete tokens generated by SSL models in ASR tasks across various languages.
Discrete Speech Tokenization Pipeline
Discrete speech tokenization can be realized by transforming a waveform into discrete tokens using methods such as k-means clustering on Transformer encoder layers' representations or directly through quantization techniques like EnCodec-24kHz. This approach allows for compact and efficient encoding of speech data.
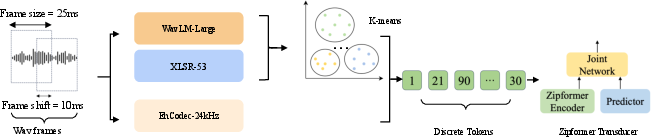
Figure 1: Illustration of the pipeline for discrete speech tokenization, showcasing how a waveform is transformed into discrete tokens. This is achieved either through k-means clustering of XLSR-53/WavLM-Large representations or directly via EnCodec-24kHz quantization.
Architectural Considerations
The paper expands on the implementation of a neural Transducer model, specifically leveraging the Zipformer-Transducer architecture for E2E ASR, which supports discrete token input. This architecture includes an audio encoder, text predictor, and joint network, which together enable effective ASR modeling. The encoder component uses a stack of transformed blocks capable of handling sequences at various frame rates, akin to U-Net architectures, which allows for efficiency and scalability in handling multilingual datasets. Modifications such as using SwooshR and SwooshL activation functions and BiasNorm for normalization further optimize the model's performance.
Experimental Results and Efficacy
The performance evaluation presented in the paper demonstrates that discrete tokens can outperform traditional Fbank-based systems across several language domains, achieving an average WER reduction of 0.31% on development sets and 1.76% on test sets, with significant reductions observed in specific languages such as Polish. This underlines the versatility of discrete tokens in capturing linguistic nuances across a variety of languages, providing a robust basis for efficient multilingual ASR systems.
Training Efficiency
A key finding of the study is the increased training efficiency when using discrete tokens. As shown in Figure 2, training with discrete tokens considerably reduces the time required per epoch compared to traditional methods. This highlights the potential benefits of discrete tokens, particularly in environments where computational resources are limited, or rapid model iteration is required.
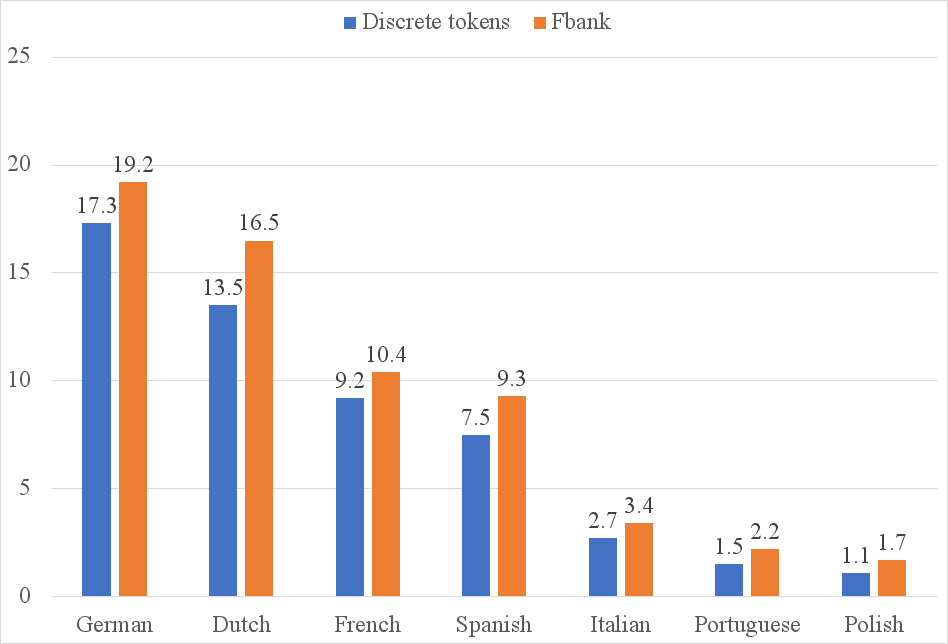
Figure 2: Illustration of training time (minutes) per epoch using Discrete tokens / Fbank features.
Ablation Study: Monolingual vs Multilingual Training
The paper also conducts an ablation study to compare monolingual against multilingual training. The results indicate that monolingual training generally yields better performance, suggesting that language-specific nuances are better captured in isolation rather than attempting to generalize across multiple language domains with a shared model. The exploration of shared k-means models further emphasizes the challenge of adequately capturing the phonetic diversity present in multilingual datasets.
Conclusion
This investigation offers valuable insights into the deployment of SSL-generated discrete tokens for ASR tasks, especially in multilingual scenarios. The demonstrated improvements in WER and training efficiency signify the potential for discrete tokens to supplant traditional feature extraction methods, paving the way for more flexible and resource-efficient ASR systems. Future research is encouraged to build on these findings, exploring further optimization of discrete token approaches and their application in an even broader array of languages.