- The paper presents a comparative analysis of diffusion-based SGMSE and Schrödinger Bridge frameworks, revealing distinct training behaviors.
- It proposes a novel perceptual loss based on PESQ that significantly improves performance metrics such as SI-SDR and POLQA.
- Experimental results show that the SB framework outperforms baselines, enhancing both perceptual quality and robustness in noisy environments.
Investigating Training Objectives for Generative Speech Enhancement
This paper explores the exploration of training objectives for generative speech enhancement, focusing primarily on score-based generative models (SGMSE) and Schrödinger Bridge (SB). It aims to elucidate the differences in training behaviors and performance of diffusion-based frameworks, proposing a novel perceptual loss function for the SB framework that improves perceptual quality and performance metrics of enhanced speech.
Introduction and Background
Generative speech enhancement methods have shown promising advancements in restoring quality in noisy speech environments. Unlike traditional methods, generative approaches use diffusion-based models to estimate and sample from a clean speech distribution conditioned on noisy input. These models facilitate the generation of multiple valid outputs, addressing various noise types and corruptions.
The paper compares two primary frameworks: SGMSE, a continuous-time diffusion model leveraging stochastic differential equations (SDEs), and the recently applied Schrödinger Bridge (SB) method, known for optimal probability distribution transformation. Each of these frameworks presents unique learning techniques and objectives, impacting their application in speech enhancement tasks.
Methodology
Score-Based Generative Models
SGMSE utilizes a forward diffusion process described by an Ornstein-Uhlenbeck SDE with variance-exploding properties (OUVE-SDE). The approach involves training a neural network to approximate an intractable score function using denoising score matching objectives. This method is known for modeling the interpolation between clean and noisy speech with exponentially increasing variance.
The training involves learning a score function that correlates with the transformation from the noisy to a clean distribution. Preprocessing inputs as complex spectrograms, SGMSE emphasizes noise prediction to enhance the underlying speech quality.
Schrödinger Bridge
The SB method aims to find an optimal transport plan between two probability distributions, treating the problem as a constrained minimization of Kullback-Leibler divergence. This approach facilitates generative modeling that begins directly with noisy input, effectively interpolating through probability distributions.
The SB framework incorporates a novel perceptual loss based on the PESQ metric, aiming to closely align enhanced outputs with perceptual quality standards. Utilizing a symmetric SDE approach, it provides robustness and flexibility, catering to both denoising and dereverberation.
Experimental Setup and Results
The paper's experimental setup involved testing various models, including baseline methods like Conv-TasNet and MetricGAN+, using the VB-DMD benchmark dataset. Several models manipulating both SGMSE and SB frameworks were evaluated based on standard metrics like POLQA, PESQ, SI-SDR, ESTOI, and DNSMOS.

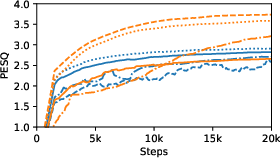
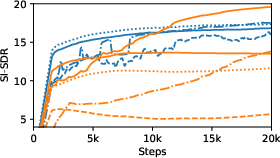
Figure 1: Performance in PESQ and SI-SDR over the training steps.
The experiments showcased that the SB approach, with its novel loss function, surpassed overlapping baselines and showed competitive results with state-of-the-art systems. This performance was particularly evident in tasks involving SI-SDR and PESQ, accentuating the perceptual gain from the SB's novel training objectives.
Conclusion
The development of varying training objectives within the field of generative speech enhancement showcases significant implications in practical applications, allowing for robust and versatile generative models. The introduction of novel loss functions tailored for the SB framework demonstrates marked improvements in speech quality and perceptual metrics. Future research may involve enhancing bandwidth capacities, leveraging high-fidelity datasets, and refining exponential moving average strategies to further advance generative modeling potentials in speech enhancement.