- The paper introduces RAGProbe, which automates the evaluation of RAG pipelines by generating QA pairs based on predefined scenarios.
- It employs six evaluation scenarios and a three-component architecture (QA generator, evaluation runner, semantic evaluator) to systematically test RAG systems.
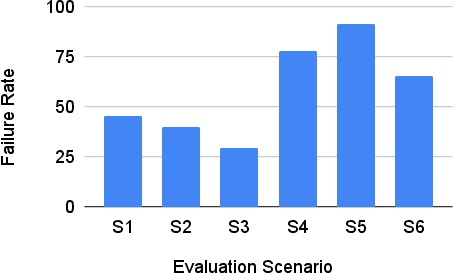
- Empirical results reveal high failure rates in combined query scenarios, highlighting areas for improvement and paving the way for more robust generative AI applications.
RAGProbe: An Automated Approach for Evaluating RAG Applications
This essay discusses the paper "RAGProbe: An Automated Approach for Evaluating RAG Applications" (2409.19019), which presents an automated approach for evaluating Retrieval Augmented Generation (RAG) pipelines. The primary aim is to address the challenges in the evaluation of generative AI applications by using pre-defined evaluation scenarios to automatically generate and assess question-answer pairs.
Introduction
Retrieval Augmented Generation (RAG) pipelines enhance generative AI applications by utilizing both retrieval systems and generative models to produce responses that are more accurate and contextually relevant. Despite their utility, the evaluation of these pipelines is often manual and lacks a systematic approach. The paper introduces RAGProbe, a tool that automates this evaluation process by generating question-answer pairs using evaluation scenarios, thereby identifying limitations within RAG pipelines.
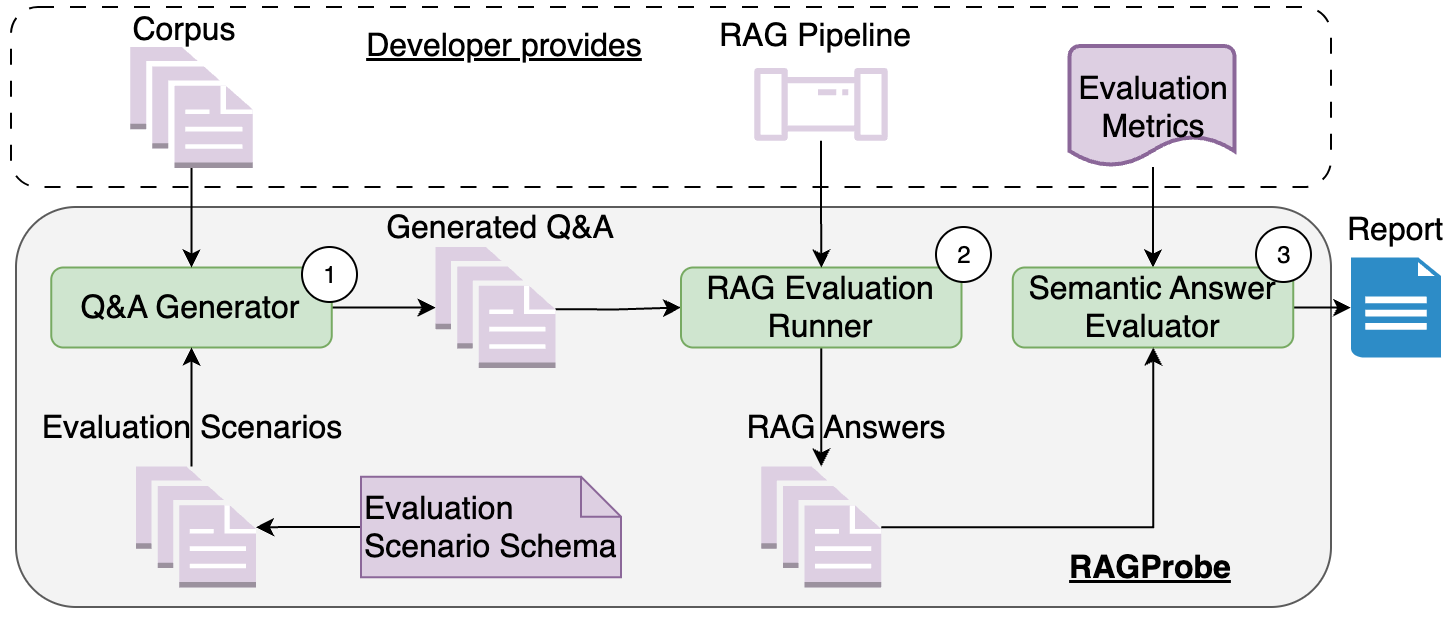
Figure 1: RAGProbe: Our automated approach to generate question-answer pairs. Our approach is extensible by adding different evaluation scenarios and different evaluation metrics.
Evaluation Scenarios
The study defines six evaluation scenarios designed to test various aspects of RAG pipelines:
- Single-Document Number Retrieval: Extracting numbers from a single document.
- Single-Document Date/Time Retrieval: Retrieving date or time information.
- Multiple-Choice Questions: Generating answers to multiple-choice questions found in a single document.
- Single-Document Combined Questions: Handling multiple questions that span different parts of a single document.
- Multi-Document Combined Questions: Addressing multiple questions whose answers span multiple documents.
- Out-of-Corpus Questions: Determining whether the system properly acknowledges when the answer is absent in the given corpus.
Each scenario involves a defined document sampling strategy, chunking and chunk sampling methods, prompting strategies, and specific evaluation metrics.
RAGProbe Architecture
RAGProbe's architecture comprises three components:
- Q&A Generator: Utilizes LLMs to generate domain-specific question-answer pairs from a document corpus.
- RAG Evaluation Runner: Interfaces with existing RAG pipelines to run generated questions through them.
- Semantic Answer Evaluator: Compares the generated answer against expected answers using established evaluation metrics. This ensures that the evaluation accounts for the nuances of natural language responses.
Empirical Evaluation
The RAGProbe effectiveness was validated across five open-source RAG pipelines and three diverse datasets: Qasper (academic domain), Google NQ, and MS Marco (open-domain). The tool's capacity to trigger failures, particularly in scenarios involving combined queries and unanswerable questions, was substantial.
Implications and Future Directions
The study offers valuable insights into improving RAG pipeline evaluations. Developers can leverage RAGProbe to continuously monitor pipeline health, integrate evaluations into CI/CD processes, and focus development efforts on failure-prone areas. Future research could enhance RAGProbe by incorporating additional LLMs, exploring more diverse evaluation scenarios, and integrating improved evaluation metrics.
Conclusion
RAGProbe presents a significant advancement in the automated evaluation of RAG pipelines. By systematically generating domain-specific question-answer pairs and evaluating pipeline responses, it provides an effective means to uncover and address limitations in RAG systems, thus supporting the development of more robust and reliable generative AI applications. Future work will likely expand on its current capabilities, further solidifying its role in the evaluation landscape.