- The paper introduces MALR, a multi-agent framework that decomposes legal reasoning tasks to enhance LLM performance.
- It employs an auto-planner with role assignment and adaptive rule-insights training to mimic human experiential learning.
- Results on confusing charge prediction tasks demonstrate MALR’s superior accuracy and potential to advance legal AI applications.
Can LLMs Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Introduction
The paper explores the challenge of adapting LLMs to perform legal reasoning tasks, specifically through a proposed framework, Multi-Agent framework for improving complex Legal Reasoning capability (MALR). This framework aims to enhance LLMs' ability to apply legal rules by employing non-parametric learning to decompose tasks into manageable sub-tasks and mimicking human-learning processes to derive insights from legal rules. The focus is on evaluating LLMs against the Confusing Charge Prediction task, highlighting LLMs’ deficiencies in distinguishing closely related legal charges, thus testing their grasp of legal theories.
Analysis of LLM Performance in Legal Contexts
The paper acknowledges the inherent complexities in legal reasoning, a domain characterized by multi-step compositional logic processes. Current LLMs exhibit limitations in consistently applying judicial rules, often defaulting to affirmative answers irrespective of accuracy (Figure 1). Prior work has revealed LLMs' propensities to overlook critical distinctions in legal rules, potentially due to hallucinations or common-sense knowledge gaps. The Confusing Charge Prediction task assesses LLMs' capacity to navigate such nuanced reasoning challenges, drawing attention to traditional models' struggles to differentiate between charges that differ on subtle, yet crucial elements like the defendant's role as a state functionary (Figure 2).
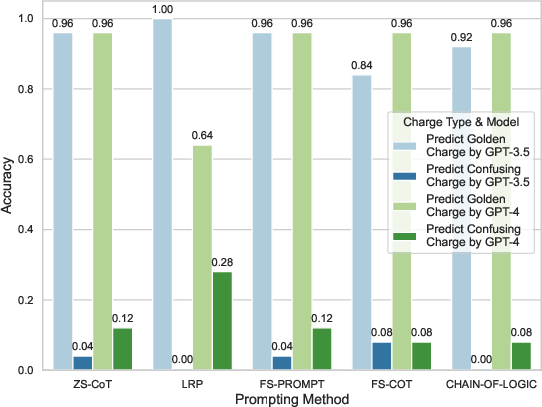
Figure 1: The performance of LLMs on predicting the golden (Misappropriation of Public Fund) or confusing charge (Fund Misappropriation) for the cases from CAIL-2018 datasets.
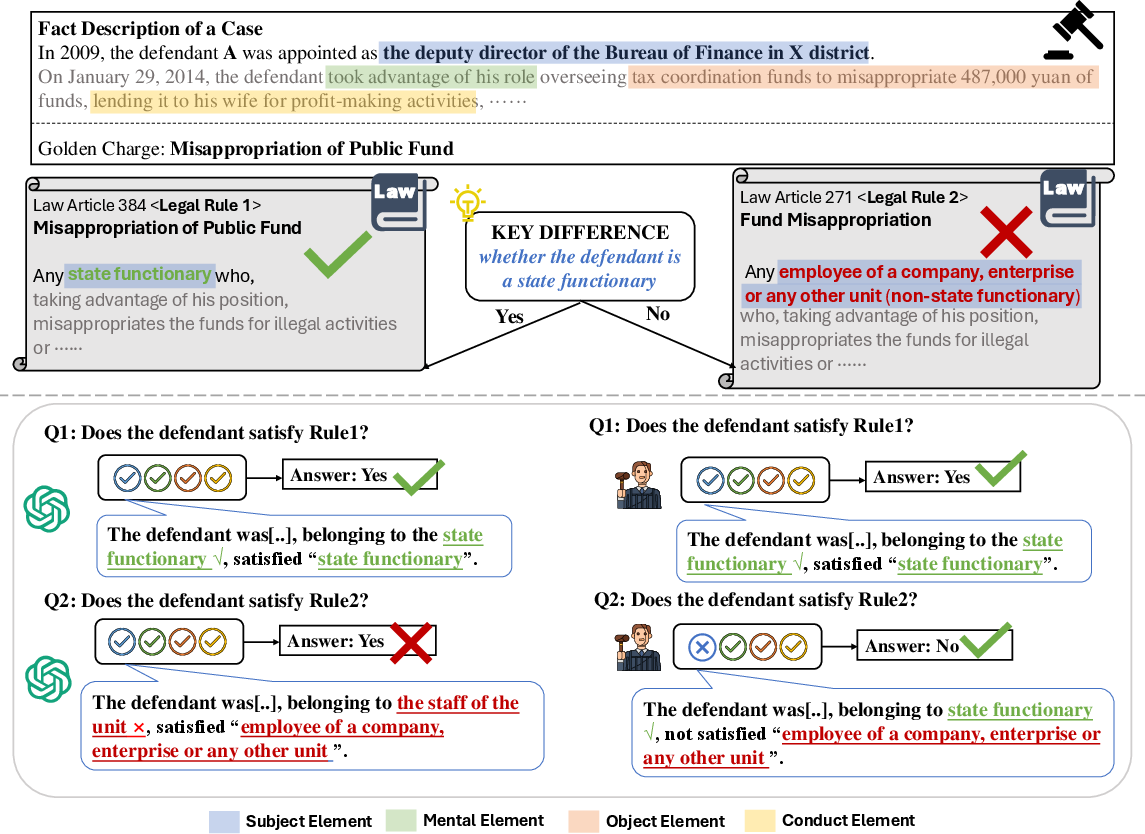
Figure 2: An example demonstrating how a judge and an LLM apply legal rules to determine if a case satisfies a specific charge.
The MALR Framework
The MALR framework introduced in the paper comprises several integral components: automatic task decomposition through an Auto-Planner, role assignments to sub-task agents, an Adaptive Rule-Insights training process, and a reasoning mechanism enriched by derived insights (Figure 3).
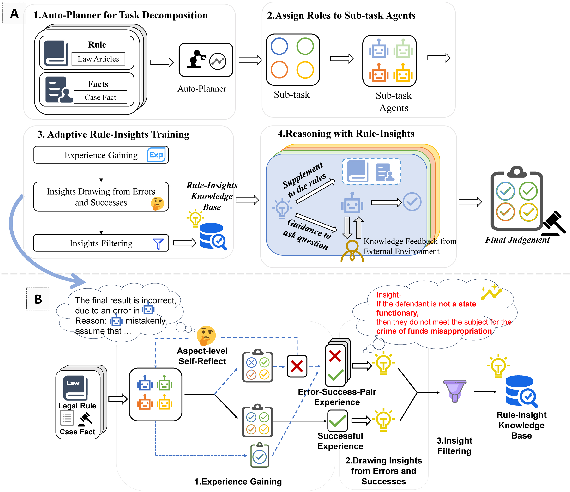
Figure 3: Our research framework in (A) and Adaptive Rule-Insights training process in (B).
Auto-Planner and Role Assignment
The Auto-Planner reduces task complexity by breaking down legal rules into discrete sub-tasks, which are then allocated to LLM-based agents. This distribution is informed by semantic similarity and relevance, effectively minimizing reasoning inconsistencies by aligning tasks with agents' capabilities.
Adaptive Rule-Insights Training
This training module employs a cycle of experience gain, insights drawing from errors and successes, and insights filtering. It follows Kolb's Experiential Learning Model to simulate an enhancement process wherein LLMs derive insights directly from legal rules through trial and error (Figure 3). By integrating these insights, the LLMs develop the ability to focus on critical legal elements and apply learned intricacies to new cases.
Experiments and Results
The experimental setup includes datasets CAIL2018, CJO, and CAIL-I, emphasizing the challenge of accurately identifying and differentiating confusing legal charges. Compared to baseline methods such as ZS-CoT and Chain-of-Logic, MALR exhibits superior accuracy in predicting the correct legal outcomes. The paper highlights MALR's success in improving performance metrics, especially in scenarios where base LLMs struggled, establishing its efficacy in augmenting the legal reasoning capabilities of these models (Figure 4).
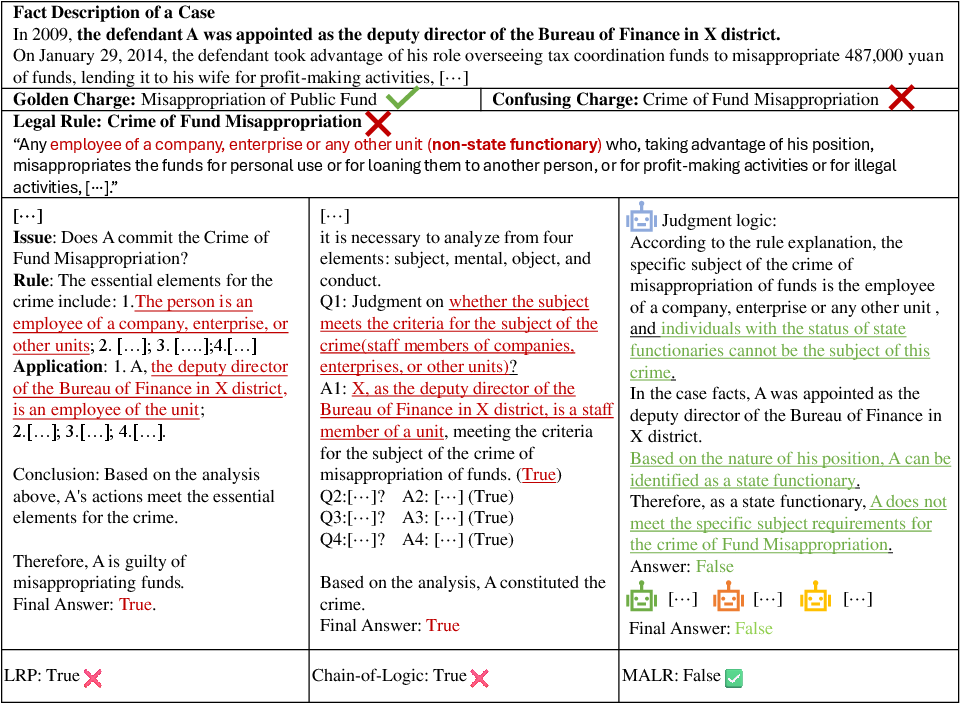
Figure 4: Case study for a given case illustrating the critical information for distinguishing confusing charges.
Implications and Conclusions
The research underscores the potential of MALR to significantly advance the application of LLMs in legal domains by systematically enhancing their reasoning and critical-thinking skills. The framework could be extended beyond legal reasoning to other knowledge-intensive domains, suggesting future research directions to improve AI's application in complex problem-solving environments, including medicine and finance. Although limitations like the need for more extensive rule augmentation and broader domain application remain, MALR presents a robust strategy for enhancing LLM performance in legally grounded tasks. The implementation of retrieval-augmented generation methods is posed as a future enhancement to further LLMs' reasoning capabilities.