- The paper introduces a novel SNR-based span-level uncertainty mechanism to enhance retrieval-augmented generation in long-context tasks.
- It employs efficient unsupervised sampling and KNN clustering to reduce labeled data dependency by up to 96%, improving model robustness.
- It achieves a 2.03% performance improvement on LLaMA-2-7B under distribution shift settings, validating enhanced model calibration.
UncertaintyRAG: Span-Level Uncertainty Enhanced Long-Context Modeling for Retrieval-Augmented Generation
The paper "UncertaintyRAG: Span-Level Uncertainty Enhanced Long-Context Modeling for Retrieval-Augmented Generation" (2410.02719) introduces UncertaintyRAG, a novel approach to improve retrieval-augmented generation (RAG) in long-context language modeling tasks. It leverages a span-based uncertainty measurement using the signal-to-noise ratio (SNR) to enhance model calibration and performance.
Introduction
Recent advancements in LLMs have amplified their capabilities in handling diverse NLP tasks like long-context QA, where large passages are processed to generate responses. This model, UncertaintyRAG, addresses the prevalent challenge of long-context processing, particularly within resource-constrained environments that restrict full context adaptation. Traditional methods are often limited by computational resource constraints and a lack of effective generalization in distribution shift settings. This work proposes a cost-effective, unsupervised learning methodology that utilizes estimates of signal-to-noise ratio-based uncertainty between text chunks, instead of relying on extensive labeled data.
Method: Span-Level Uncertainty
The core method introduced in the paper is a span-level uncertainty estimation using the SNR as a metric to maintain robust retrieval models under the RAG framework. By computing the model's self-information and employing the sample gradient SNR, the method effectively measures span uncertainty and translates it into a similarity metric for text chunks. This process not only enhances model calibration but also reduces biases introduced by random chunking.
The determination of chunk similarity involves calculating the SNR of consecutive text chunks after concatenation and input into the LLM. By observing the SNR's behavior within a specific sliding window, the model determines a stable interval, which more accurately reflects semantic alignment.
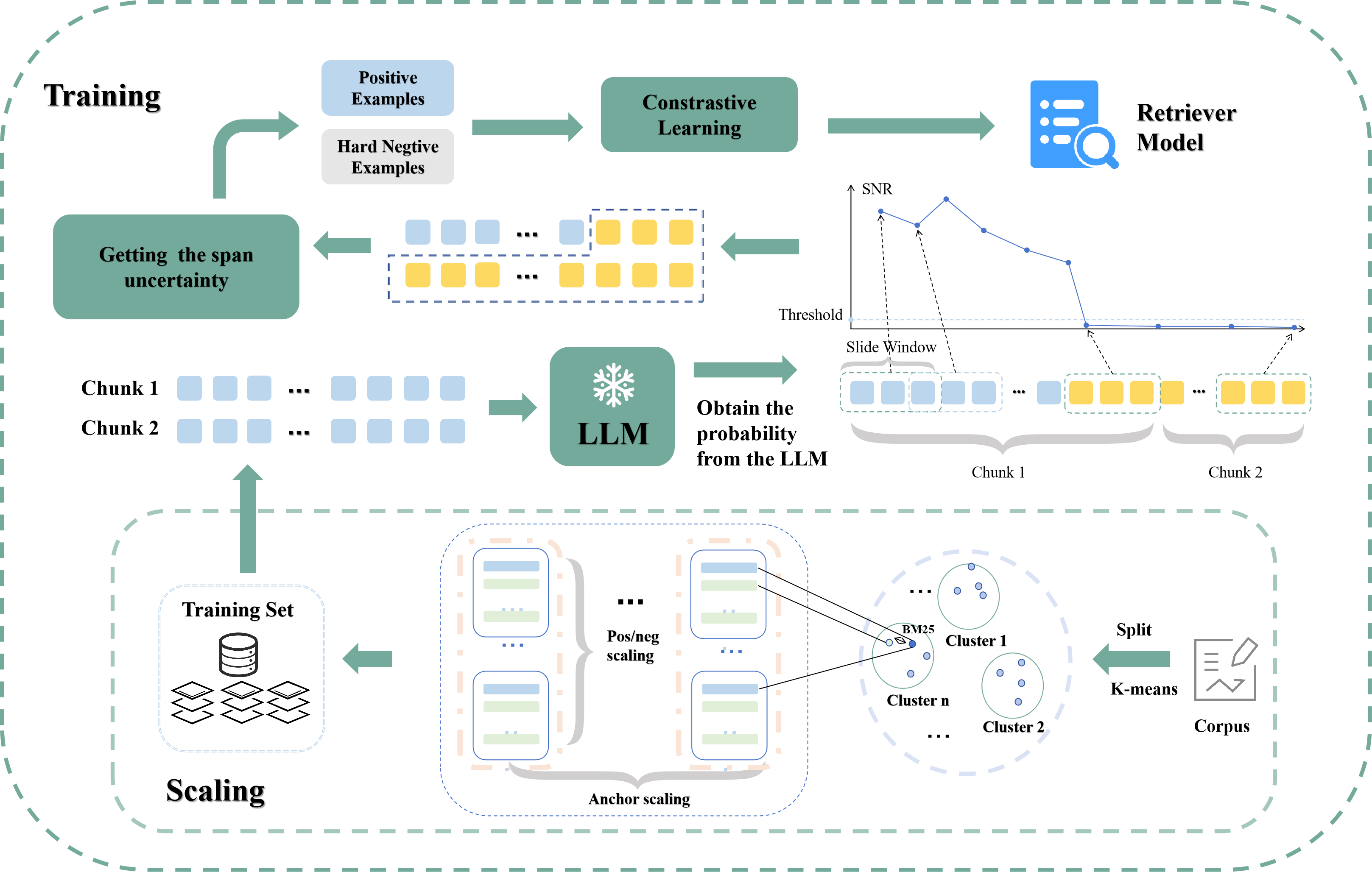
Figure 1: Scaling and training. The figure presents the details of scaling and training.
Data and Training Strategies
The proposed method utilizes span uncertainty to construct positive and negative samples from the training data without relying on query data. Instead, the authors employ efficient data sampling and scaling strategies to improve distributional robustness.
To construct training samples, chunks of fixed length (300 words) are derived from merged datasets, including HotpotQA, MultiFieldQA, among others. The paper circumvents complex chunking strategies to maintain inference efficiency by employing a straightforward chunking method and using BM25 to shortlist candidates before applying SNR-based uncertainty scoring. K-nearest neighbors (KNN) clustering partitions the training datasets into clusters to select chunks, facilitating scalable and robust training.
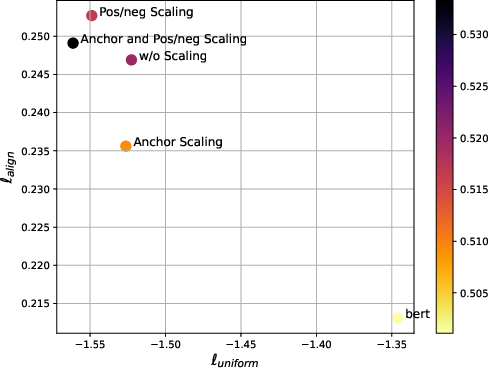
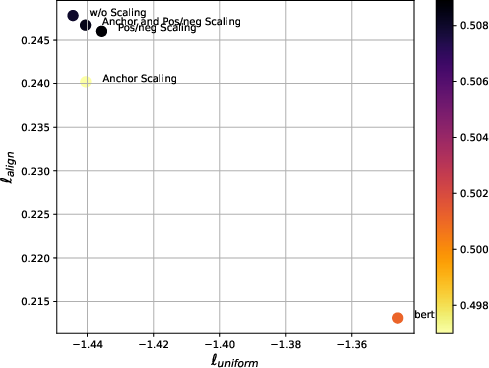
Figure 2: Uniformity and alignment of different chunk embedding along with their averaged semantic textual similarity.
Results
UncertaintyRAG achieves a performance improvement of 2.03% on LLaMA-2-7B compared to BGE-M3 under distribution shift settings, demonstrating its robust calibration and enhanced generalization capabilities. Furthermore, by adopting efficient data sampling and scaling strategies, UncertaintyRAG minimizes the demand for labeled data by up to 96% less than comparable models, while maintaining state-of-the-art performance in various long-context RAG tasks.
The paper also provides in-depth analysis using representation similarity analysis (RSA) and properties like alignment and uniformity to validate the robustness of the retrieval model.
Figure 2: Align and Uniform. This figure shows uniformity and alignment of different chunk embedding.
Implications and Future Directions
The implications of UncertaintyRAG are significant for the advancement of RAG frameworks. The use of span-level SNR-based uncertainty measurement offers a versatile approach to long-context modeling without the computational expense associated with extending the LLM context window or large-scale labeled training data. Practically, the lightweight nature allows it to integrate with existing LLMs seamlessly, presenting a scalable solution to improve LLM performance, especially under distributional shift settings.
Future research directions may explore extending uncertainty quantification methods to other modalities and applying similar principles to different retrieval-augmented paradigms like unsupervised cross-modal retrieval. Furthermore, the efficacy of SNR-based calibration in varied real-world applications presents exciting avenues for further exploration.
Conclusion
UncertaintyRAG presents a sophisticated approach to enhancing long-context RAG tasks by utilizing SNR-based span-level uncertainty. The approach not only efficiently improves the model's calibration and robustness but also minimizes the dependency on large labeled datasets, making it a highly adaptable solution for diverse LLMs without necessitating extensive fine-tuning. The implications of this research offer pathways for future work in enhancing retrieval models and further improving the robustness and versatility of AI systems in handling long-context scenarios.