- The paper demonstrates that random transformers achieve 100% accuracy in modular arithmetic tasks via embedding-only training, highlighting innate algorithmic encoding.
- Random transformers effectively perform associative recall, decimal addition, and parenthesis balancing by leveraging low-dimensional subspace manipulation.
- Language modeling experiments reveal that while fully trained models excel, random transformers generate coherent outputs with appropriately large hidden sizes.
Introduction
The paper explores the innate capabilities of randomly initialized transformer models, analyzing their potential to encode specific algorithmic tasks without training the complete network. By focusing primarily on the embedding layers and assessing their algorithmic performance, the work investigates an alternative approach to understanding how transformers learn and generalize specific functions present even before training starts.
Model Setup and Initialization
The transformer models under consideration are decoder-only architectures truncated to manipulate only their embedding and unembedding layers. The model parameters are randomly initialized primarily based on Gaussian distributions with standard deviations conditioned by the number of layers and dimensions. The training methodology contrasts full training of all parameters against optimizing solely the embedding layers, a process termed as "embedding-only training."
Algorithmic Tasks Assessment
- Modular Addition: Random transformers manage modular arithmetic, provable by attaining 100% accuracy in tests, hence indicating successful internalization of addition within a constrained modulus.
- Needle-in-a-Haystack: These transformers accurately performed associative recall tasks, reaffirming their ability to recognize and map inputs.
- Decimal Addition and Parenthesis Balancing: Both tasks observed close-to-perfect accuracy when random transformers were employed, elucidating their capacity to manage sequence-oriented operations and context-free grammars necessary for tasks like arithmetic and syntax validation.
Figure 1: Illustration of the setup and performances.
In each scenario, the experiment demonstrated a significant capacity for random transformers to internalize operations through low-dimensional subspace manipulation, evident even in preliminary post-initialization states.
Language Modeling and Memorization
Language modeling reveals a stark contrast between fully trained models and random transformers. While fully trained transformers manage a loss lower than embedding-optimized counterparts, the random models still deliver coherent, grammatically correct outputs if large hidden sizes are provided.
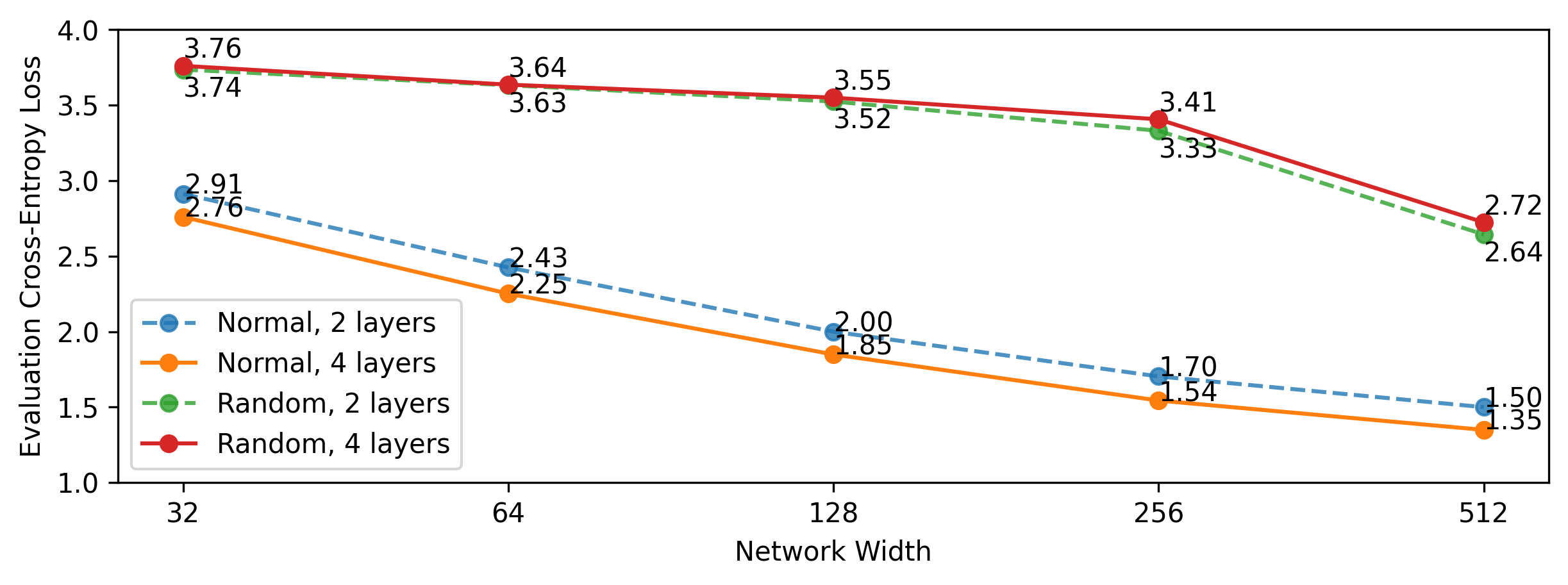
Figure 2: Language modeling performances (measured in cross-entropy loss or equivalently log perplexity, lower is better) for fully trained and random transformers. Comparatively large hidden sizes are needed for random models to match the performance of fully trained models.
Such experimental setups testify to the potential these models have in understanding syntax, although their efficiency and accuracy shrink compared to fully trained versions.
Dimensional Analysis
Across several experiments, random transformers consistently operated within constrained and notably lower-dimensional subspaces, efficiently embedding calculations necessary for algorithmic task resolution. This phenomenon, termed "subspace selection," witnesses low variance explained by the primary components of these models’ internal representations.
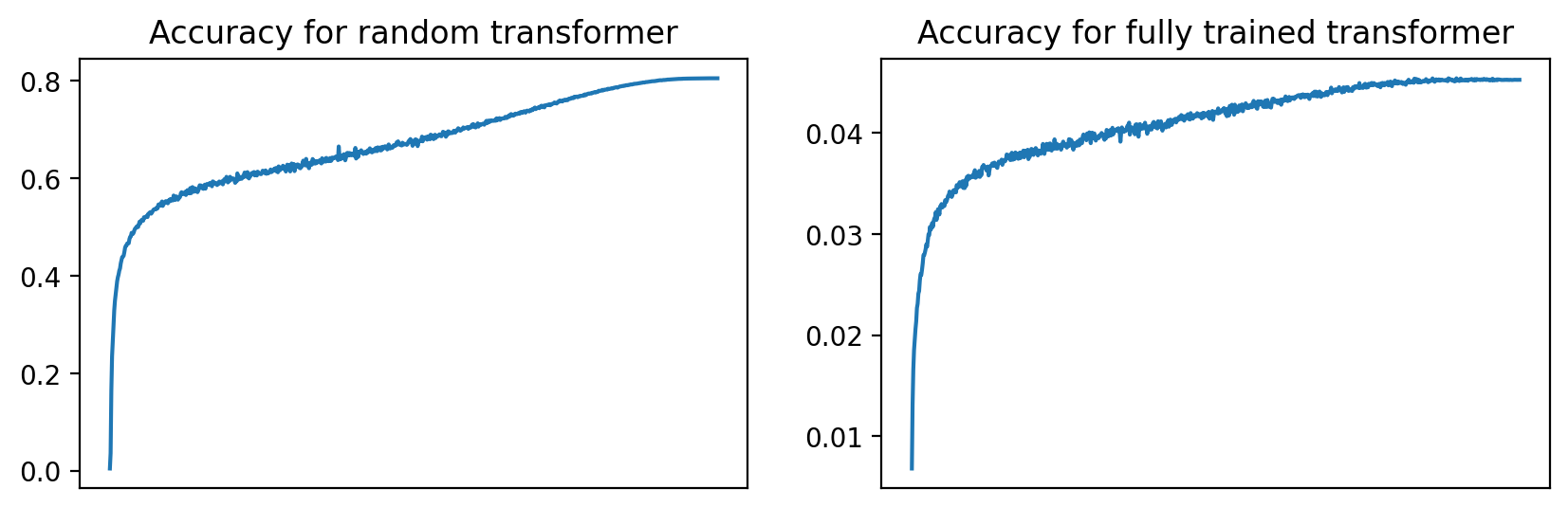
Figure 3: During training, the accuracy curve from fully trained and random transformers in the memorization task (\cref{sec:memorization}.
Conclusion
Random transformers exhibit a surprising proficiency in learning and solving complex tasks using minimal training through selective subspace manipulation. Their innate ability to encode features and contextual rules without comprehensive training suggests profound implications for understanding the capabilities of neural circuits in transformers. Future work should continue exploring this avenue to refine insights into how these models can be optimized for task-specific implementations with reduced computational resources. The study provides a rich landscape for further inquiry into how initialization impacts learning trajectories in AI systems.