- The paper demonstrates that LLM suggestions can boost topic assignment efficiency by approximately 133.5% while introducing anchoring bias.
- It employs a two-stage user study with expert annotators to compare LLM-generated topics against independently generated ones.
- The research highlights the need for balancing LLM efficiency with critical human oversight to mitigate risks of over-reliance and bias.
Summary of "The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?"
Introduction
The paper "The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?" explores the influence of LLMs on human analytical processes, specifically in specialized domains such as policy studies. The primary focus is on the efficiency and potential biases introduced when humans integrate LLM suggestions into their workflows. A structured two-stage user study was conducted involving expert annotators and LLMs, examining the impact on topic discovery and assignment tasks.
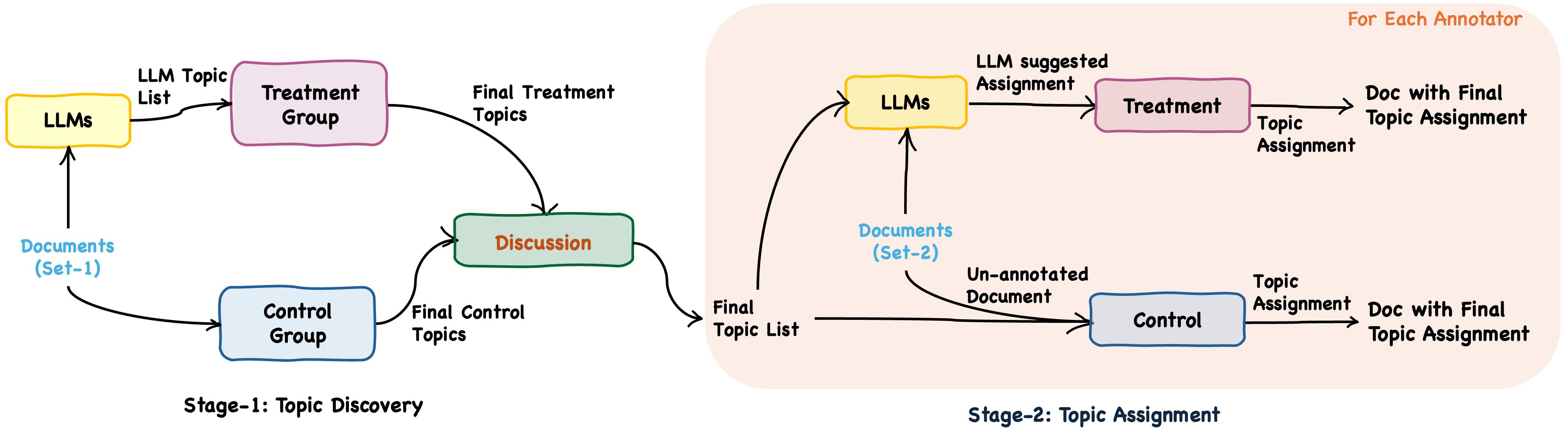
Figure 1: An overview of the two stages of our user study, illustrating the tasks conducted with and without LLM suggestions.
The study utilized transcripts from interviews about AI policies in India, transcribed for accuracy and anonymized for confidentiality. The task employed was Topic Modeling, a common strategy for analyzing large documents. Instead of traditional approaches like LDA, the study employed a modified version of TopicGPT, leveraging GPT models for topic generation and annotation. This allowed for handling longer context windows and generating interpretable topics suited for the study's needs.
Stage 1: Topic Discovery
In Stage 1, expert annotators were divided into treatment and control groups. The treatment group received LLM-generated topic suggestions, while the control group generated topics independently. Both groups subsequently reviewed and integrated their findings to develop a human-curated final topic list. The results showed significant overlap between human and LLM-generated topics, although LLMs missed certain document-specific nuances.
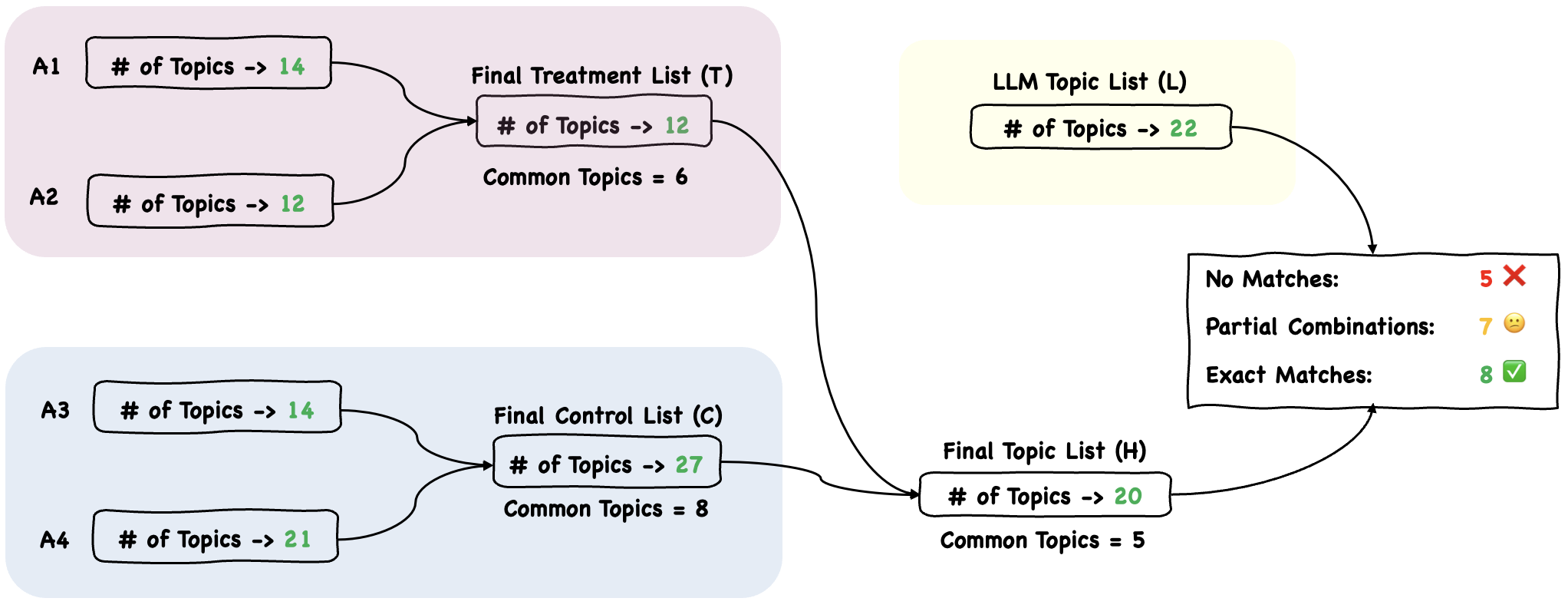
Figure 2: The integration process of the topic lists from annotators in different settings for Stage 1.
Stage 2: Topic Assignment
Stage 2 focused on assigning identified topics to new documents. Annotators used the final topic list from Stage 1 to independently label documents, with the treatment group again receiving LLM suggestions. LLM-assisted assignments resulted in significant efficiency gains—speeds increased by approximately 133.5%—but introduced anchoring bias, evidenced by higher agreement with LLM-suggested annotations compared to the control.
Discussion
While LLMs can significantly improve efficiency, their use introduces risks of cognitive biases such as anchoring. The study highlights the need for a balanced approach that leverages the speed and consistency of LLMs while maintaining critical human oversight. Annotators indicated a preference for LLM use due to efficiency gains but remained cautious of biases and over-reliance, underscoring a need for effective strategies to mitigate these risks.
Conclusion
This research underscores LLMs' dual role in enhancing task efficiency and the potential negative impact of influencing human judgement through biases. As LLMs continue to evolve, further exploration into mitigating their unintended effects on human decision-making processes is essential for their responsible adoption in domain-specific analytical tasks. Future research should focus on refining LLM outputs to enhance specificity and reduce biases while deriving maximum utility from these evolving technologies.