- The paper introduces DIMEE, a novel framework that applies early exit strategies to allocate DNN layers across mobile, edge, and cloud devices.
- It employs clustering based on sample complexity, processing easy cases on mobile and harder ones on cloud to reduce computation costs.
- Experimental results reveal a cost reduction of over 43% with less than 0.3% drop in accuracy compared to cloud-only inference.
Distributed Inference on Mobile Edge and Cloud: An Early Exit based Clustering Approach
The paper presents DIMEE, a novel method leveraging early exit strategies to optimize distributed inference across mobile, edge, and cloud platforms. It addresses the challenge of deploying large DNNs on resource-constrained devices through a scalable inference model that dynamically allocates computational resources based on sample complexity.
Overview of DIMEE
DIMEE utilizes distributed inference by deploying partial DNN layers on mobile and edge devices and the full DNN on the cloud. Each component processes samples based on their computational complexity determined by early exits. This strategic layer deployment allows easy samples to be processed on mobile devices, moderately complex samples on edge devices, and complex samples in the cloud, optimizing inference cost and latency.
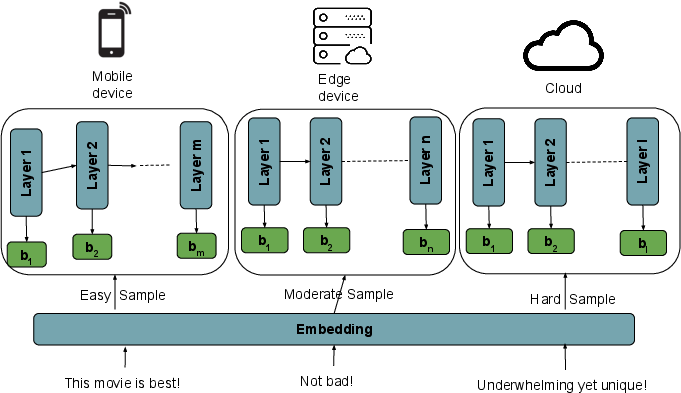
Figure 1: The DNN model is partitioned across devices, processing samples optimally based on complexity.
Experimental results on GLUE datasets demonstrate DIMEE's effectiveness in reducing inference costs significantly while maintaining high accuracy. The method achieves a cost reduction of over 43% while incurring less than 0.3% drop in accuracy compared to cloud-only inference.
Early Exit Strategy and Complexity Pools
Early exit strategies are integral to DIMEE, enabling adaptive processing by assessing sample complexity through intermediate classifiers. DIMEE clusters samples into easy, moderate, and hard pools using embedding distances calculated during training. These pools guide the assignment of computational resources during deployment.
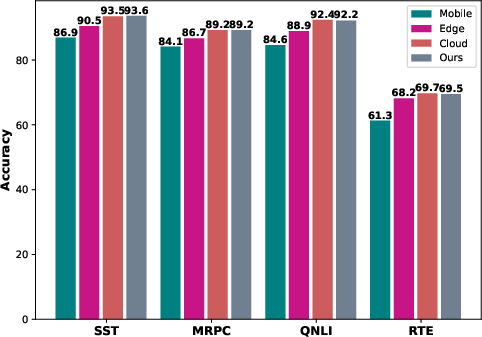
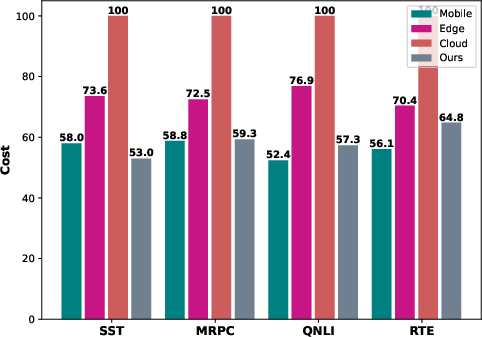
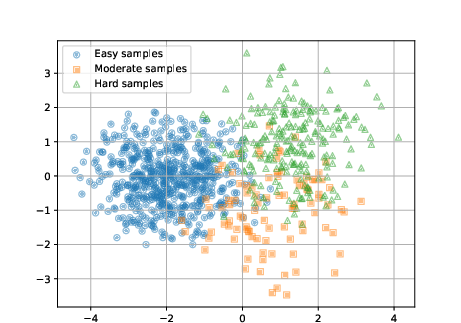
Figure 2: The accuracy profiles of inference across mobile, edge and cloud devices.
The clustering approach optimizes inference by dynamically assessing complexity, thereby minimizing resources for simpler tasks and utilizing cloud computing for complex samples. This method effectively balances processing efficiency and accuracy.
Implementation Details
Key parameters governing DIMEE's performance include the deployment of layers at mobile and edge devices, denoted as m and n layers, respectively. The choice of threshold α for early exits is optimized to maximize confidence while accounting for processing and offloading costs.
The layer configuration impacts the trade-off between device processing costs and cloud offloading costs. Higher values of m and n reduce offloading to the cloud, increasing processing requirements on local devices but lowering latency costs.
Cost Structure and Optimization
DIMEE's cost structure includes processing costs (λm, λe), offloading costs (oe, oc), and cloud charges (γ). The method defines a reward function, optimizing the threshold α to balance confidence and costs effectively.
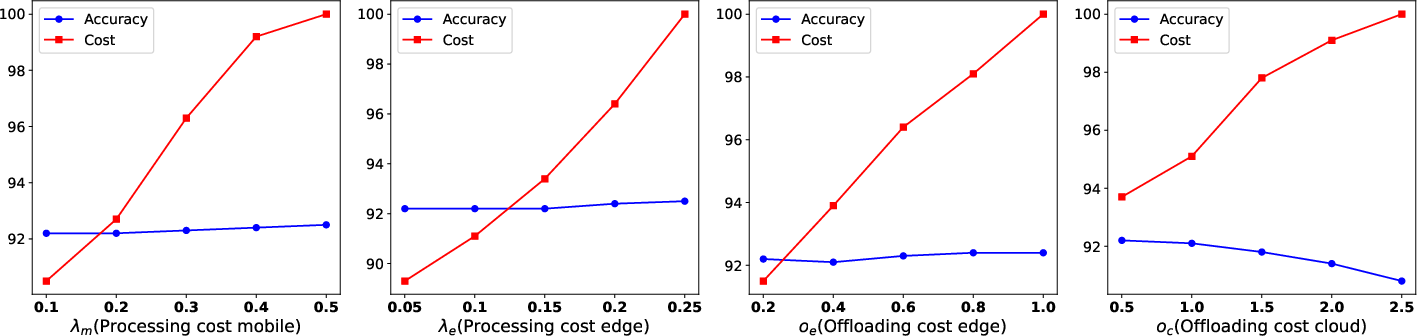
Figure 3: Cost analysis illustrating the impact of cost variations on accuracy and efficiency.
The adaptive summation of costs for mobile processing, edge processing, and cloud offloading underpins DIMEE's performance optimization, guiding resource allocation precisely based on sample complexity.
Conclusion
DIMEE introduces a robust framework for distributed inference across mobile, edge, and cloud platforms. By strategically deploying layers and utilizing early exits, the approach significantly reduces inference costs and maintains high accuracy, offering a practical solution for deploying DNNs on resource-constrained devices. Future work may extend this methodology to other domains and refine the clustering mechanism for enhanced performance across diverse tasks.