- The paper introduces Lastde, a framework that mines local token probability fluctuations using multiscale diversity entropy (MDE) to distinguish human and LLM texts.
- It integrates global log-likelihood with local time-series analysis, achieving AUROC gains of 5–11% over previous training-free methods.
- Lastde++ enhances detection speed and resilience, outperforming existing approaches in cross-model, cross-lingual, and adversarial scenarios.
Training-free Detection of LLM-generated Text via Token Probability Sequence Mining
Introduction
The paper "Training-free LLM-generated Text Detection by Mining Token Probability Sequences" (2410.06072) introduces Lastde, a training-free statistical framework for distinguishing human-written text from LLM-generated text. In contrast to earlier training-free methods—which predominantly rely on global sequence statistics (e.g., mean likelihoods)—Lastde leverages temporal dynamics of the token probability sequence (TPS), conceptualizing TPS as a time series and extracting local fluctuation patterns via multiscale diversity entropy (MDE). This approach is augmented with global log-likelihood statistics and implemented in two variants: Lastde and Lastde++, the latter introducing a fast-sampling enhancement. Extensive experiments on multiple datasets and LLMs show strong performance against prior training-free methods, especially in cross-model, cross-lingual, and paraphrasing-attack settings.
Motivation and Problem Characterization
Conventional approaches to LLM-generated text detection include training-based methods (e.g., fine-tuned RoBERTa, GPTZero, supervised classifiers) and training-free methods (e.g., likelihood, DetectGPT, DNA-GPT). Training-based detectors often suffer from limited generalization, overfitting, and high data/labor overheads, particularly in challenging cross-domain or cross-model contexts. Training-free methods generalize better but are typically bottlenecked by their reliance on global statistics, neglecting local, fine-grained sequence patterns that may be highly discriminative. Additionally, some training-free methods require prohibitively large numbers of samples for perturbation-based schemes, diminishing practical utility.
This work posits that TPS, interpreted as a time series, encodes distinctive local variation: human writing is characterized by higher fluctuation and entropy in the TPS, while LLM outputs exhibit smoother, lower-variance TPS due to log-probability optimization during generation. Quantifying these dynamics, especially at multiple temporal scales and under black-box access, is hypothesized to yield improved detection performance and robustness.
Methodological Framework
Lastde operates as a composite statistic integrating global and local TPS features:
- TPS Log-Likelihood (Global Feature): For a sequence of tokens, the standard average log-likelihood under a proxy model.
- Multiscale Diversity Entropy (MDE, Local Feature):
- The TPS is transformed using a multiscale mean over window sizes ("scales") to capture segmental fluctuation patterns.
- These are further subdivided via sliding windows; for each window, the cosine similarity between successive segments is computed to measure local trajectory alignment.
- Similarity values are histogrammed over discretized bins (state intervals) to produce empirical probability distributions.
- Shannon entropy is computed over these distributions at each scale; higher entropy signifies greater local diversity (i.e., less regularity).
- The vector of entropies across scales constitutes the MDE sequence for the text.
Lastde’s detection score is defined as:
Lastde(x,θ)=Agg-MDEmean log-likelihood
where Agg-MDE is the aggregate (default: std) of the MDE sequence.
- Lastde++ (Fast-Sampling Enhancement): To further amplify detection power and enable real-time applicability, Lastde++ incorporates a normalized discrepancy-based scoring by contrasting the text’s Lastde score with the mean and variance of Lastde scores over conditionally independent samples drawn from a proxy model ("fast sampling"). This standardization delivers greater separation between human and LLM distributions, with improved efficiency over perturbation-based approaches requiring thousands of samples.
Figure 1: The Lastde framework, showing TPS extraction, multiscale processing, local entropy computation, and the integration of global (likelihood) and local (entropy) features for scoring.
Analysis of Token Probability Sequence Statistics
Empirical analysis reveals that human-authored continuations, when extended from identical prompts as LLM generations, display significantly more variable TPS curves compared to LLMs, corroborated by both visual inspection and distributional statistics.
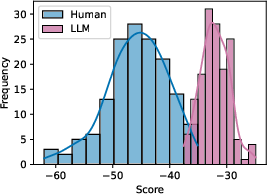
Figure 2: TPS fluctuations and Lastde score distributions for human versus LLM generations; human-written TPS has higher fluctuation and a distinct entropy profile.
Notably, the distributions of Lastde scores produced by the framework yield clear boundaries permitting effective threshold-based discrimination.
Empirical Results
Datasets and Models: Extensive evaluation is conducted on six datasets spanning news articles, QA, fiction, and cross-lingual settings, with 18 source models (open- and closed-source, 1.3B–13B parameters), using up to 150 human/LLM text pairs per condition.
Detection Scenarios: Tests were performed in both white-box and black-box settings. In black-box mode, a proxy model (e.g., GPT-J) is used for scoring.
Key Findings:
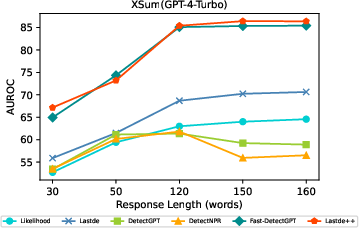
Figure 4: AUROC of various methods as a function of contrast sample count; Lastde++ gains rapidly and saturates with far fewer samples than competitors.
- Distributional Analysis: The normalized Lastde++ score yields compact, well-separated distributions for human and LLM texts, supporting reliable thresholding.
Robustness and Threat Model Considerations
Lastde and Lastde++ exhibit substantially improved resilience to popular evasion strategies (e.g., paraphrasing, different decoding), validating the importance of TPS local fluctuation modeling. Furthermore, the methods generalize well across proxy/source model pairs—though detection precision is sensitive to proxy/source misalignment when using closed-source LLMs with divergent calibration.
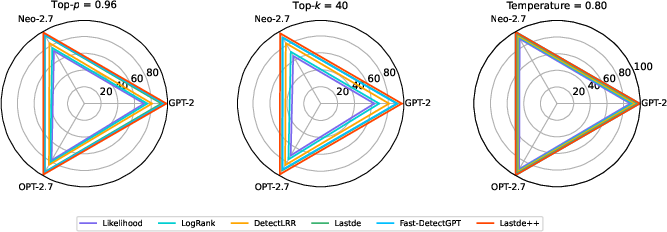
Figure 5: Variation in detection performance of Lastde/Lastde++ and baselines across decoding strategies and model variants.
Theoretical and Practical Implications
The introduction of time series analysis (via MDE) into the LLM detection pipeline demonstrates that local sequence dynamics contain robust signals distinguishing algorithmic and human text generation—even among the latest LLM architectures. The lack of reliance on label-rich training data and high performance in black-box judgments addresses key practical deployment barriers.
The methodology sets a new SOTA benchmark for training-free LLM-generated text detection, both in terms of accuracy and computational efficiency. Its resilience under adversarially altered text and cross-lingual transfer highlights the advantage of dynamic TPS modeling over static distributional statistics.
Prospective Developments
This work motivates further investigation into adaptive local feature mining on LLM outputs—such as extending beyond log-probability sequences to richer model internal states (e.g., activation traces), meta-learning proxy selection, or hybrid schemes that combine supervised and unsupervised statistics for more nuanced forensics. There are open questions regarding the ultimate robustness of such training-free detectors against sophisticated attack models, calibration shifts in LLM sampling, and adaptation to short-form or heavily edited text settings.
The MDE foundation is also amenable to integration into real-time content monitoring pipelines or as a plug-in for content authenticity verification in open publishing ecosystems—especially where labeled data are insufficient or model-specific watermarking is inapplicable.
Conclusion
This paper establishes that training-free LLM-generated text detection can be significantly advanced by mining the local fluctuation structure of token probability sequences via time series diversity entropy, integrated with global statistics. The proposed Lastde and Lastde++ algorithms achieve strong performance gains with minimal computational overhead, providing robustness to common evasion strategies and cross-scenario generalization demands. The demonstrated effectiveness in both white-box and black-box settings on diverse text domains substantiates the theoretical thesis and provides a practical foundation for the future of unsupervised machine-written text detection (2410.06072).