An Undetectable Watermark for Generative Image Models
Abstract: We present the first undetectable watermarking scheme for generative image models. Undetectability ensures that no efficient adversary can distinguish between watermarked and un-watermarked images, even after making many adaptive queries. In particular, an undetectable watermark does not degrade image quality under any efficiently computable metric. Our scheme works by selecting the initial latents of a diffusion model using a pseudorandom error-correcting code (Christ and Gunn, 2024), a strategy which guarantees undetectability and robustness. We experimentally demonstrate that our watermarks are quality-preserving and robust using Stable Diffusion 2.1. Our experiments verify that, in contrast to every prior scheme we tested, our watermark does not degrade image quality. Our experiments also demonstrate robustness: existing watermark removal attacks fail to remove our watermark from images without significantly degrading the quality of the images. Finally, we find that we can robustly encode 512 bits in our watermark, and up to 2500 bits when the images are not subjected to watermark removal attacks. Our code is available at https://github.com/XuandongZhao/PRC-Watermark.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to put an invisible “watermark” into AI‑generated images so we can tell they were made by AI, without hurting how the images look. The watermark is designed to be undetectable to anyone who doesn’t have a secret key, and it’s hard to remove without making the image look worse.
Think of it like writing with invisible ink across the whole “DNA” of the picture. Only someone with the right light (the key) can spot it, and trying to scrub it out smears the picture.
Key Objectives
The paper asks and answers a few big questions in simple terms:
- Can we watermark AI images in a way that doesn’t reduce image quality or variety at all?
- Can the watermark be undetectable to outsiders (even clever attackers), but detectable by someone with a secret key?
- Can the watermark survive common “removal” tricks like compression, cropping, or adding noise?
- Can the watermark carry useful information, like who made the image or when?
How It Works (Explained Simply)
To explain the method, here are the main ideas with everyday analogies:
Generative images and “noise”
Modern image generators like Stable Diffusion start from random “static” (like TV snow) and gradually turn it into a clean picture guided by your text prompt. That starting static is called a “latent.” It’s just a big list of random numbers.
A secret pattern that looks like randomness
The authors use a tool from cryptography called a pseudorandom error‑correcting code (PRC).
- “Pseudorandom” means it looks exactly like randomness to anyone without the key.
- “Error‑correcting” means even if parts get messed up, you can still recognize or recover the message—like how your phone still understands you in a noisy room.
They use the PRC to pick a secret pattern in the signs (+/−) of the starting random numbers. To everyone else, those signs look like ordinary randomness.
Putting the watermark in
Instead of using totally random static, the system:
- Draws random numbers like usual (same magnitudes),
- But sets the plus/minus signs to match the secret PRC pattern.
Because signs in true random noise are already 50/50, this “signed” noise looks indistinguishable from normal random noise to anyone without the key.
Detecting the watermark
To check an image, the system tries to “reverse” the image generator to estimate the starting static (this is called inversion). Then it checks whether the signs match the secret PRC pattern. Thanks to error correction, it still works even if the reverse step isn’t perfect.
Why it’s undetectable (to outsiders)
Undetectable here means: no efficient method (including AI classifiers) can tell watermarked images from normal ones without the key, even after many tries. Because the watermark hides inside the natural randomness of the starting static, it doesn’t change the distribution of images in any way that tools can reliably pick up. That also means it doesn’t harm image quality under any common metric.
Robustness to removal
Common attacks (like JPEG compression, noise, resizing, or even specially trained removal models) usually fail to erase the watermark unless they visibly damage the image. Since the watermark is “spread out” across the whole latent space (the image’s internal “DNA”), small local tweaks don’t remove it.
Main Findings and Why They Matter
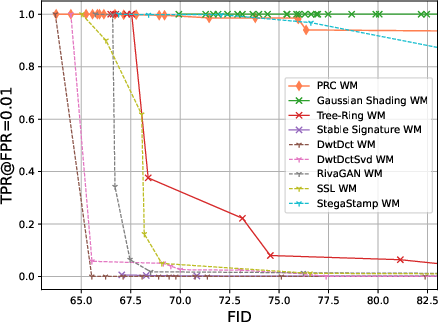
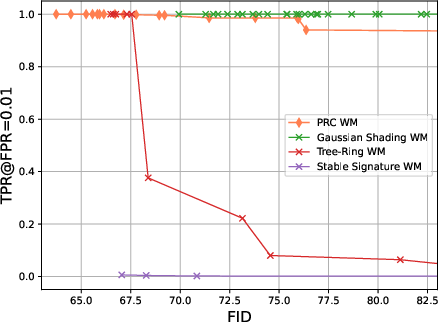
The authors tested their method on Stable Diffusion 2.1 and compared it to several popular watermarking methods (both post‑processing schemes that edit images after generation, and in‑processing schemes that affect the generation itself). They looked at:
- Image quality: using standard scores like FID, CLIP Score, and Inception Score. In simple terms, these measure how good and realistic images look and how well they match the text prompt.
- Variety: using LPIPS, which checks if different outputs from the same prompt still look meaningfully different (important for creative uses).
- Detectability by outsiders: training a classifier (ResNet18) to try to spot the watermark without the key.
- Robustness: trying many watermark removal attacks and checking whether the watermark survives without the image getting noticeably worse.
Key results:
- Quality preserved: Their watermark is the only one tested that consistently keeps image quality and variety the same as normal images across all metrics.
- Hard to learn: A neural network could not learn to detect their watermark without the key and only achieved random‑guess performance, while it could detect other watermarks.
- Robust to attacks: Many removal attempts failed unless they made the images clearly worse (for example, very heavy JPEG compression made images blurry and still didn’t fully remove the watermark).
- Can carry data: The watermark can encode information. It robustly carried 512 bits (like a user ID, timestamp, or signature), and up to about 2500 bits when no attack was applied.
They also let users set a target false positive rate (FPR), like 1%, with a mathematical guarantee that it won’t be higher. False positive means mistakenly calling a normal image “watermarked.”
Implications and Potential Impact
- Practical safety: Platforms could use this to catch large‑scale AI‑generated misinformation while keeping personal creativity intact. If only trusted platforms hold the detection key, they can filter harmful content without affecting everyday users.
- No trade‑off with quality: Because the watermark is provably undetectable to outsiders, it doesn’t lower image quality or variety—solving a major reason why watermarks haven’t been widely adopted.
- Flexible and easy to deploy: No extra model training is needed. It plugs into existing diffusion model pipelines.
- Trusted attribution: Since it can carry a message (like a signature), it could help trace content back to its source in a privacy‑respecting way.
In short, this work shows we can have strong, stealthy, and robust watermarks for AI images that protect the public without hurting image quality or user experience.
Collections
Sign up for free to add this paper to one or more collections.