- The paper introduces MITA, a mutual adaptation framework that synchronizes model adjustments and data updates using energy-based optimization.
- It employs SGLD and Contrastive Divergence to achieve up to 10.57% improvement in outlier scenarios and 4.68% in mixed distributions.
- The approach bridges the gap between model expectations and test data attributes without requiring retraining, enhancing robustness.
"MITA: Bridging the Gap between Model and Data for Test-time Adaptation" (2410.09398)
In this paper, "MITA: Bridging the Gap between Model and Data for Test-time Adaptation," researchers tackle the challenge of test-time adaptation (TTA) by proposing an innovative approach known as Meet-In-The-Middle based Test-Time Adaptation (MITA). This process navigates beyond the limitations of existing TTA methods that perform suboptimally under the presence of outliers or mixed distributions by introducing a symmetric mutual adaptation between model and data from opposing directions, thereby aligning them efficaciously.
Introduction
Test-Time Adaptation has gained traction as it does not need labeled data during testing, making it invaluable in scenarios where retraining the model with every variance of test data is not feasible. However, existing TTA paradigms predominantly focus on batch-level alignment which proves ineffective when faced with individual variances such as outliers. As depicted in Figure 1, these methods usually rely heavily on statistical patterns, resulting in incongruence between model distributions and individual data characteristics. MITA addresses these issues by encouraging a meeting in the middle approach using an energy-based optimization strategy.
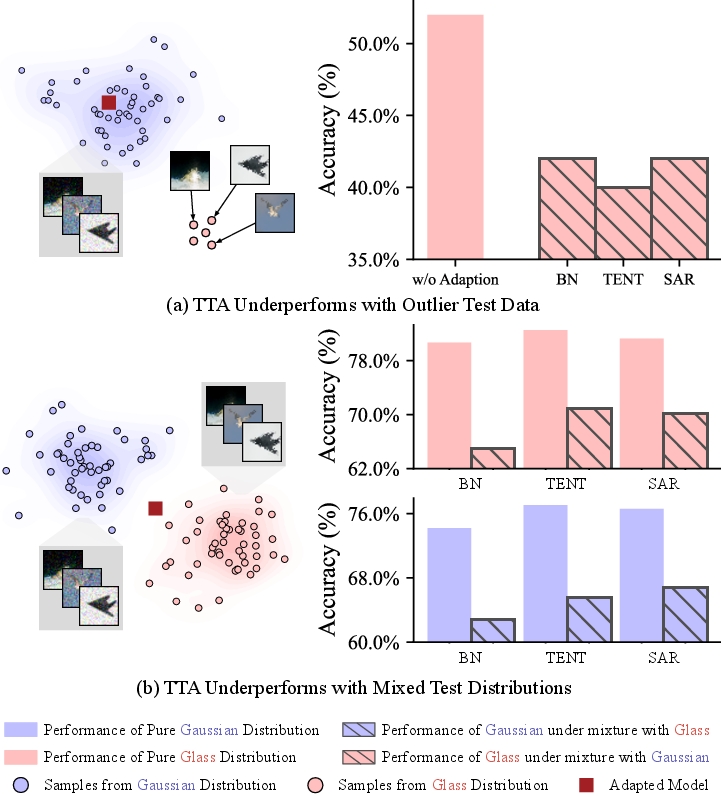
Figure 1: Batch-level TTA performance noticeably declines in the presence of outliers or mixed distributions.
Methodology
MITA Architecture
MITA's strategy involves mutual adaptation where both data and models adapt reciprocally to achieve alignment. This is conceptually visualized in Figure 2, wherein the model pertains to generalizability for distinct data patterns, optimizing simultaneously and symmetrically towards better consensus between model distributions and data attributes.
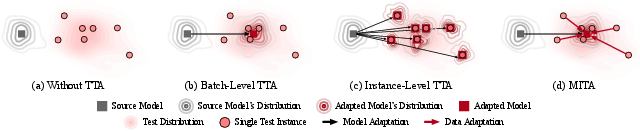
Figure 2: Four TTA paradigms: The model has better generalizability for data that aligns with the model's distribution. MITA encourages mutual adaptation of the model and data from opposing directions, thereby meeting in the middle.
Energy-Based Model Construction
Essential to MITA is its reliance on Energy-Based Models (EBMs) to restructure the source model's logits for adaptation. The flexibility of EBMs permits them to operate with non-normalized distributions, allowing MITA to utilize Contrastive Divergence as an objective function for holding the model accountable to test data distributions while also fostering generative capacities for data alignment.
Model and Data Adaptation Dynamics
The MITA process proceeds with the structured adaptation of both model and data. The overall architecture displayed in Figure 3 illustrates that model adaptation involves parameter tuning to reduce divergence derived from test distributions using energy minimization frameworks, specifically leveraging Stochastic Gradient Langevin Dynamics (SGLD) for sampling. In this collaborative framework, the discrepancies between present test data and model expectations are symmetrically minimized.
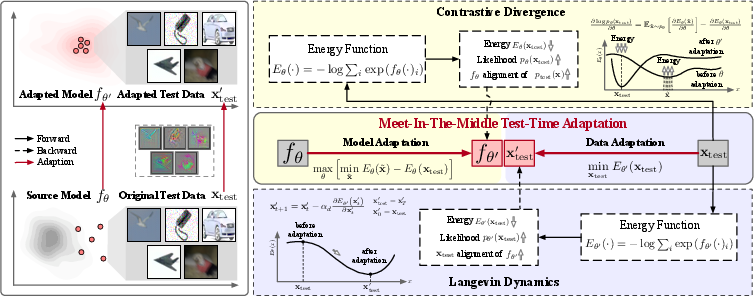
Figure 3: Overview of MITA. Left: the motivation of MITA. Right: the overall architecture of MITA, which establishes a mutual adaptation between a trained source model and the test data, guiding both to meet in the middle.
Algorithmic Process
Crucially, MITA employs SGLD within model adaptation to enhance a model's perception of distribution variances which subsequently directs data-level self-updates, thereby aligning data instances closer to the anticipated characteristics represented by the adapted model.
Experimental Results
Experiments conducted over datasets like CIFAR-10-C manifest MITA's substantial merits over SOTA methods in scenarios characterized by outliers, pure, and mixed distributions, indicating significant gains of up to 10.57% in outlier and 4.68% in mixture scenarios. MITA's ability to adjust both at the data-centric and model-centric level yields stable performance amplifications meaningful for generalization efficacy across complex domain shift environments.
The visualizations in Figure 4 underscore MITA's efficacious adaptations by evidencing the corrected misalignments in outlier scenarios and the harmonized adaptations seen in individual instance corrections during data adaptation. This confirms its robust generative capabilities in adjusting complex and unexpected data shifts.

Figure 4: Visualization for model adaptation (a), data adaptation (b) and correction cases during data adaptation (c).
Conclusion
By embarking on a two-pronged adaptation strategy, MITA strongly embodies an advanced mechanism to bridge the evident gap between model expectations and diverse data attributes. By efficiently managing alignment without pre-requisite retraining knowledge or deep-seated structural requirements from training data, MITA opens promising avenues for adaptable AI systems agile enough to grapple with unseen distributions. Future work could further enhance MITA's framework with operational efficiency optimizations and improvements in discriminability without compromising generative prowess.