- The paper introduces an agent-based framework that rewrites query plans to optimize complex document processing tasks for improved accuracy.
- It employs generation and validation agents to iteratively decompose and evaluate pipelines, ensuring higher performance in domains like legal analysis and sentiment detection.
- Experiments demonstrate accuracy improvements ranging from 25% to 80%, validating the tradeoff of increased computational cost for superior results.
DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing
DocETL introduces a methods and architecture designed to significantly improve the processing of complex document tasks. The paper proposes an agentic approach to optimize document analysis pipelines by rewriting them for accuracy rather than merely focusing on cost efficiency. Below, we explore the main concepts, implementation strategies, and potential implications presented in the paper.
Overview of DocETL
DocETL is tailored for complex document processing which presents a reliable declarative interface that allows users to define and automatically optimize document analysis pipelines with multiple operations. Unlike existing frameworks, DocETL recommends decomposition of complex tasks into more manageable and accurate operations, leveraging LLM weaknesses, such as dealing with context length limitations and errors in semantic projection tasks.
Key Components and Process
Agent-Based Optimization
DocETL’s agent-based optimization uses a two-fold framework comprising generation and validation agents:
- Generation Agents handle the logical decomposition of tasks and plan generation by applying rewrite directives. Through this process, operations needing optimization are transformed using a set of directives that allow decomposition or restructuring.
- Validation Agents synthesize validation prompts to evaluate and ensure the improvement of output quality. These agents assess various candidate plans, measuring them against defined criteria to ensure they meet accuracy standards.
Figures Referenced:
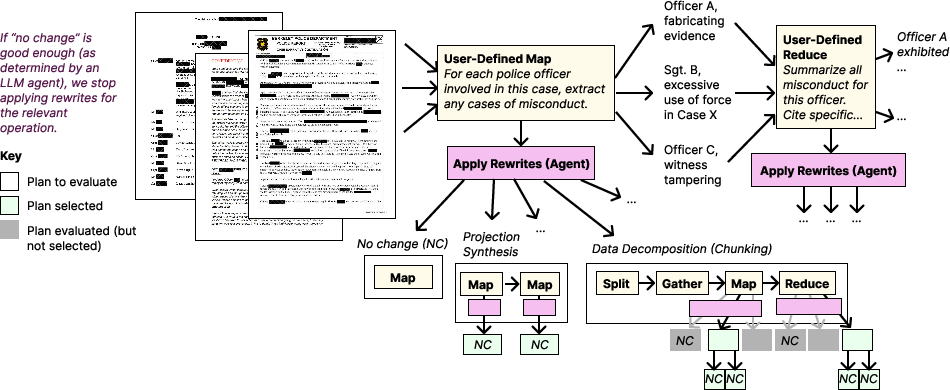
Figure 1: Optimization for a pipeline designed to accomplish the task in \texttt{journalist-task}, with LLMs synthesizing new plans using rewrite directives.
Rewrite Directives
The system utilizes a set of rewrite directives tailored for improving output accuracy for LLM-powered applications. These include:
- Document Chunking: Splitting large documents into manageable sections that an LLM can more accurately process.
- Gleaning: Use iterative refinement to improve LLM outputs by validating and refining through multiple passes.
- Duplicate Resolution: Utilizing resolve operations to canonicalize entities across diverse documents, ensuring aggregation accuracy.
- Projection Synthesis: Creating intermediate results through chained or parallel map operations to improve aggregation.
Figure Reference:
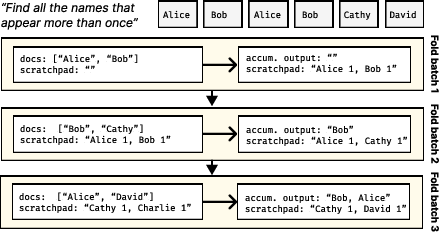
Figure 2: Reduce's iterative folding over 3 batches of documents illustrating efficient use of LLMs to update mention counts and outputs.
Implementation and Real-World Usage
The paper details the system implementation using YAML-based DSL and operators that work with any LLM with tool-calling capabilities. DocETL has demonstrated effectiveness in various domains, from legal document analysis to police records processing. Its versatility is amplified by drop-in optimizations tailored per domain.
Figures Referenced:


Figure 3: Split-Gather Pipeline processing where long documents are split into chunks with context added for LLM processing.
Figure 4: Gleaning process automating iterative refinement for increased accuracy in document analysis tasks.
Evaluation and Results
The DocETL framework showcases marked improvements in accuracy when handling large datasets across multiple domains. In legal contract analysis, video game review sentiment analysis, and declassified article processing, DocETL outperformed baseline systems by margins of 25% to 80%.
The paper notes the higher computational and cost overhead associated with DocETL's approach. However, the improvements in accuracy and versatility for complex documents validate this tradeoff, particularly given projected trends in lowering LLM processing costs.
Implications and Future Developments
Through DocETL, the research underlines the necessity to adapt LLM utilization for real-world applications demanding high accuracy from unstructured data processing. DocETL's design highlights potential avenues for combining LLMs with traditional optimization concepts, promising advancements in AI-driven data management.
DocETL's approach not only opens new possibilities for automated document processing but also sets a precedent for more dynamic, agent-driven solutions in large-scale data environments. Future enhancements may focus on reducing costs, increasing processing speeds, and further refining the interactions between generated plans and real-world constraints.
In conclusion, DocETL represents a pioneering step in AI-assisted optimization of complex document processing tasks, addressing critical challenges in accuracy with a novel agentic framework. These advancements offer significant implications for future AI systems in enhancing data-driven decision-making processes across industries.