- The paper presents the UTF approach, leveraging under-trained tokens as fingerprints to efficiently verify LLM identity.
- It employs PCA and supervised fine-tuning to map rare tokens to predetermined outputs, ensuring robust and reliable fingerprinting.
- Experiments on multiple LLM variants demonstrate up to 76% time savings and negligible performance impact, underscoring the method’s resilience.
Under-trained Tokens as Fingerprints: A Novel Approach to LLM Identification
Introduction
LLMs have rapidly transformed natural language processing, but issues regarding their authenticity and ownership are increasingly significant. Addressing these issues often involves embedding fingerprints within models, a method to verify their ownership and prevent misuse. This paper introduces "Under-trained Tokens as Fingerprints (UTF)", a novel technique leveraging under-trained tokens for efficient LLM identification without significant computational overhead or the need for white-box access.
Repurposing these under-trained tokens—those infrequently encountered during a model's training phase—UTF embeds specific input-output pairs within the LLM, effectively marking the model with a unique fingerprint. These tokens offer new associations due to their under-utilization, and are employed to produce predetermined outputs for certain inputs, ensuring robust and recognizable fingerprints.

Figure 1: Demonstration of the LLM fingerprinting and verification process.
Methodology
Detection and Mapping
Under-trained tokens are identified by analyzing the unembedding matrix U to locate tokens with minimal interactions during training. These tokens present low probabilities, guiding their identification using a principal component analysis-based method. Once identified, these tokens are mapped to predetermined outputs using supervised fine-tuning, where associations between input-output pairs are strategically formed.
The approach ensures that the fingerprint remains intact, influencing the model minimally due to the rarity of the under-trained tokens in typical training datasets.
Supervised Fine-tuning and Verification
The fine-tuning process constructs sequences from under-trained tokens, which are used to teach the model specific mappings. This method is executed with minimal disruption to the model's normal operational effectiveness. Verification involves querying suspect models with the original fingerprinting inputs and observing for matching outputs, confirming the presence of the fingerprint without requiring internal access to model weights.
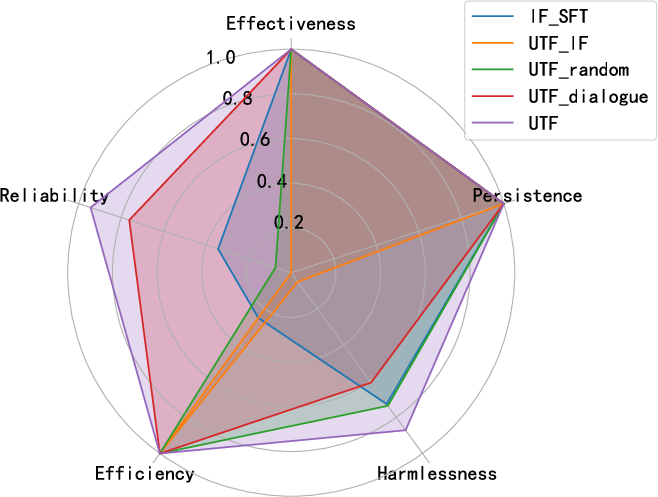
Figure 2: Comparison of the proposed method with existing methods at different metrics.
Experiments
The UTF approach was tested on several LLM variants such as Llama2-7B-chat, Vicuna7B-v1.5, AmberChat-7B, and Gemma-7B-Instruct, evaluating effectiveness, reliability, efficiency, and harmlessness across standard benchmarks. Experiments demonstrated effective fingerprint embedding across different models, with persistence noted even post-fine-tuning on diverse datasets, highlighting robustness against further model adjustments.
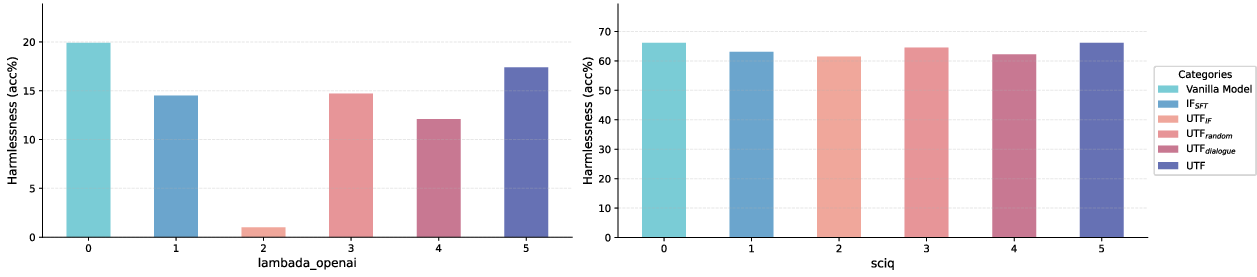
Figure 3: Harmlessness of and baseline methods on two benchmarks. The values in this figure represent the test accuracy on LAMBADA OpenAI and SciQ dataset.
Efficiency: The UTF method significantly reduces fingerprinting time compared to previous approaches (up to 76% time savings).
Reliability: The method ensures high reliability, minimizing false positives by eliminating pre-dialogues.
Harmlessness: The impact on benchmark performance was negligible, validating the harmless nature of the integration.
The method outperformed existing baselines on most metrics, revealing minimal degradation and high fingerprint resilience.
Conclusion
The under-trained tokens offer a robust mechanism to identify and embed fingerprints within LLMs. UTF circumvents common obstacles faced by traditional methods, like computational demands and model performance impacts, while maintaining substantial verification reliability. The approach demonstrates a viable path for fingerprinting in environments with restricted access, crucial for real-world applications.
Research implications extend to enhancing model ownership protocols in AI, offering groundwork for developing resilient fingerprinting techniques that co-evolve with advancing model architectures. Future investigations may adapt these tokens for advanced, parameter-efficient fingerprinting techniques, cementing UTF's utility as a cornerstone for LLM validation frameworks.