- The paper presents a novel shortcut model enabling one-step image generation by conditioning on noise levels and step sizes.
- It employs a self-distillation training approach that integrates flow-matching and self-consistency objectives for efficient denoising.
- Empirical results on CelebA-HQ and ImageNet benchmarks demonstrate scalability and competitive performance against traditional iterative diffusion methods.
One Step Diffusion via Shortcut Models: Technical Exploration
The paper "One Step Diffusion via Shortcut Models" (2410.12557) introduces a novel class of generative models termed shortcut models. These models aim to enhance the efficiency of image generation by reducing the computational burden typical of diffusion models and flow-matching models, which require extensive iterative denoising. Shortcut models leverage a single neural network and training phase to achieve high-quality sample generation in significantly fewer steps, including the capability for one-step generation.
Shortcut Models Conceptual Framework
Efficiency and Flexibility in Generative Modelling
Shortcut models propose an innovative approach by conditioning the network on both the noise level and the desired step size. This allows the model to effectively bypass intermediate steps in the generation process, a capability not feasible with traditional diffusion models. Importantly, shortcut models maintain a high sample quality across various sampling step budgets, outperforming existing methodologies by simplifying the training pipeline to a single network and training phase.
Sampling Mechanism
In contrast to traditional iterative methods where models undergo multiple passes during inference, shortcut models facilitate instant denoising by predicting future noise levels based on the current state and step size. This is exemplified by the empirical evaluations on CelebA-HQ and ImageNet-256 benchmarks, where shortcut models demonstrate performance parity or superiority over complex two-stage models.
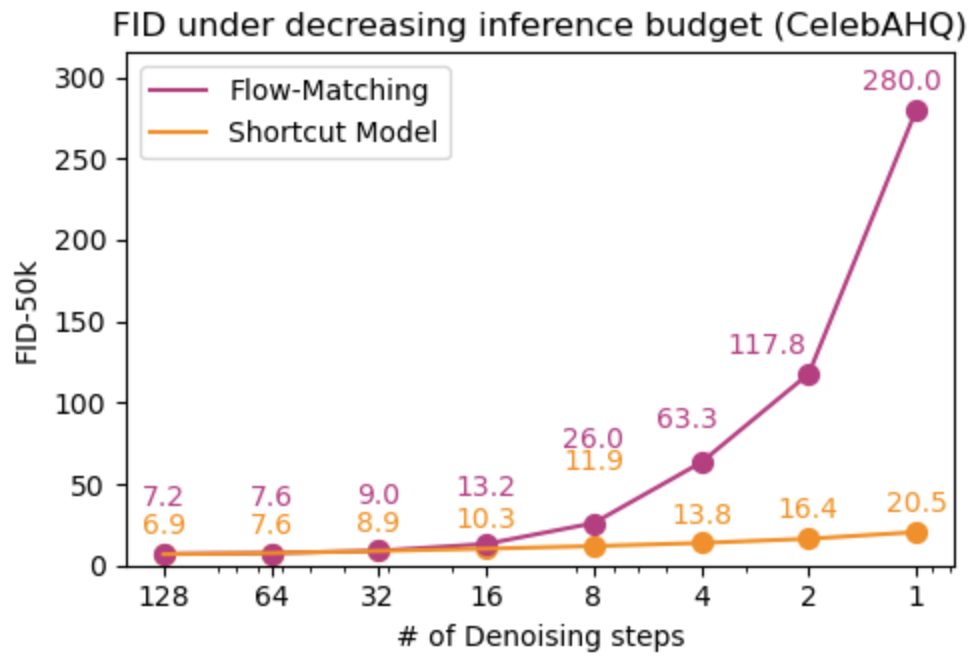
Figure 1: Behavior of flow-matching and shortcut models over decreasing numbers of denoising steps. The naïve flow-matching models degrade, while shortcut models retain sample distribution integrity.
Methodological Advances
Self-Distillation in Training
Shortcut models employ a self-distillation approach during training, negating the need for separate distillation steps. The training loss combines flow-matching objectives for grounding and self-consistency targets to ensure predictive fidelity across varied step sizes. This dual-objective framework ensures the model can perform accurate denoising irrespective of the chosen inference budget.

Figure 2: One-step generation quality improves with increased model parameters, showcasing scalability.
Hyperparameter Optimization
Key hyperparameters include a balance between empirical and self-consistency targets during training, guiding the model towards stable convergence. Empirical targets feed the model raw data pairs, grounding performance at small step sizes. This training strategy proves computationally efficient, slightly increasing training demands compared to traditional diffusion models.

Figure 3: Interpolations between two sampled noise points, illustrating smooth transitions and semantic coherence.
Practical Implications and Future Directions
Real-world Applications
Beyond image generation, shortcut models hold potential in domains such as robotic control, where rapid inference is crucial. In these applications, shortcut models can substitute diffusion policies, achieving comparable performance at reduced inference costs.
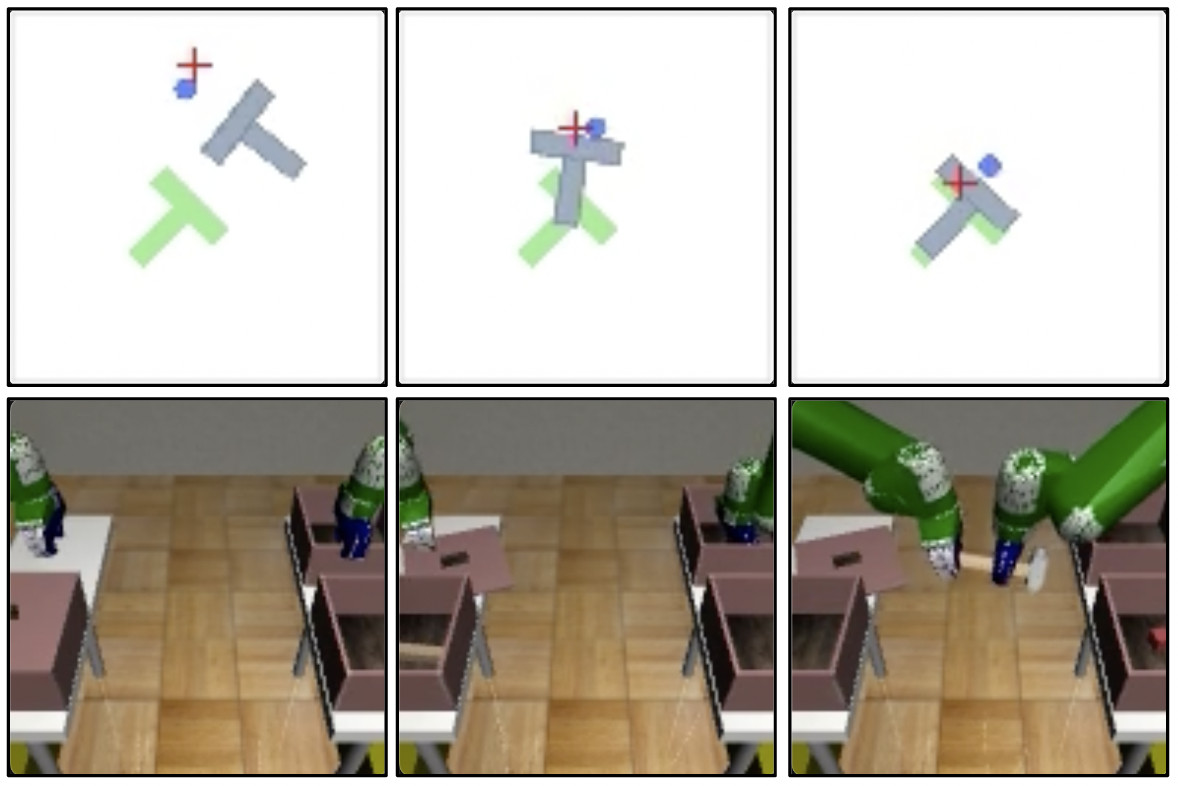
Figure 4: Demonstrates multimodal policy representation in robotic tasks, enabling reduced denoising steps.
Limitations and Prospective Research
While effective, shortcut models' reliance on bootstrapping poses inherent risks of data dependency and could hinder advancements unless mitigated by robustness-focused iteration. Future work may explore integrating optimization techniques to refine the noise-to-data mapping further, potentially bridging remaining gaps between few-step and many-step generation quality.

Figure 5: Generations at varied denoising steps from the CelebA-HQ dataset, revealing quality across inference budgets.
Examined scalability verifies shortcut models’ ability to upscale their parameter count without sacrificing one-step generation accuracy. This property contrasts with bootstrapped methods, which traditionally do not benefit from parameter scaling due to inherent limitations.

Figure 6: Class-conditional image generation from ImageNet dataset exhibits consistent step-wise quality.
Conclusion
Shortcut models offer an effective simplifying approach to diffusion-based generative modeling. Their design reduces computational overhead while maintaining flexibility in generation fidelity across inference budgets. This paper contributes valuable insights for developing generative models that balance speed and quality, providing a scalable solution suitable for numerous AI applications.