- The paper introduces MathGAP, a framework that generates math problems with proof trees to rigorously evaluate LLMs' arithmetic reasoning.
- It leverages proof complexity metrics such as depth and width to systematically test models on both linear and nonlinear reasoning challenges.
- Experimental results indicate that LLM performance declines with increased proof complexity, highlighting the need for diverse and robust training examples.
MathGAP: Out-of-Distribution Evaluation on Problems with Arbitrarily Complex Proofs
Introduction
"MathGAP: Out-of-Distribution Evaluation on Problems with Arbitrarily Complex Proofs" presents an innovative framework designed to rigorously evaluate the arithmetic reasoning capabilities of LLMs beyond their training data. The primary motivation is to address inadequacies in current evaluation methods where evaluation datasets are often contaminated by data seen during training, and benchmarks do not adequately represent problems of varying complexity. This paper introduces MathGAP, an evaluation method that generates math problems with any desired complexity, offering a systematic approach to understanding LLMs' generalization abilities concerning arithmetic proof complexity.
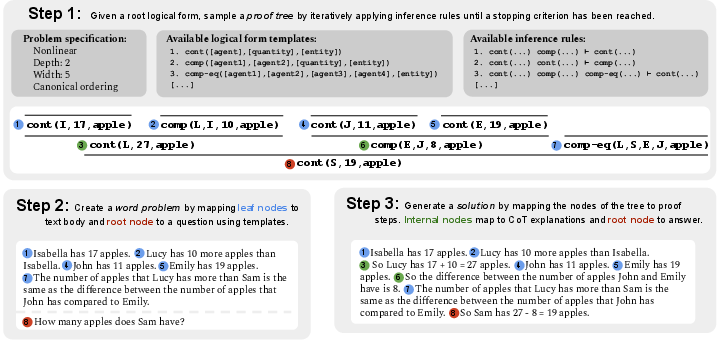
Figure 1: MathGAP framework for arithmetic reasoning, testing LLMs on problems with proofs of arbitrary complexity, with problem and CoT solution annotations generation.
Framework and Methodology
Generating Problems with Proof Trees
MathGAP leverages a formal treatment of math word problems (MWPs) by converting problem semantics into sequences of logical forms, represented as proof trees. These proof trees characterize problem complexity through metrics such as linearity, depth, width, and node ordering. The logical forms relate to predicates that define arithmetic relationships, such as 'comparison' and 'partwhole', allowing a systematic generation of arithmetic problems.
The generation process involves:
- Sampling a proof tree based on specified complexity metrics.
- Mapping logical forms to natural language problems using template-based conversions.
- Creating CoT annotations by translating proof steps into chain-of-thought narratives.
Evaluating LLMs with MathGAP
MathGAP facilitates studies that measure LLMs' generalization by generating test problems that exceed the complexity of training problems. It evaluates LLM performance across various complexity dimensions, such as proof depth, width, and sentence order permutations. Importantly, it provides a contamination-free setting by ensuring generated test problems are novel relative to training data.
Experimental Results
Generalization Across Complexity Dimensions
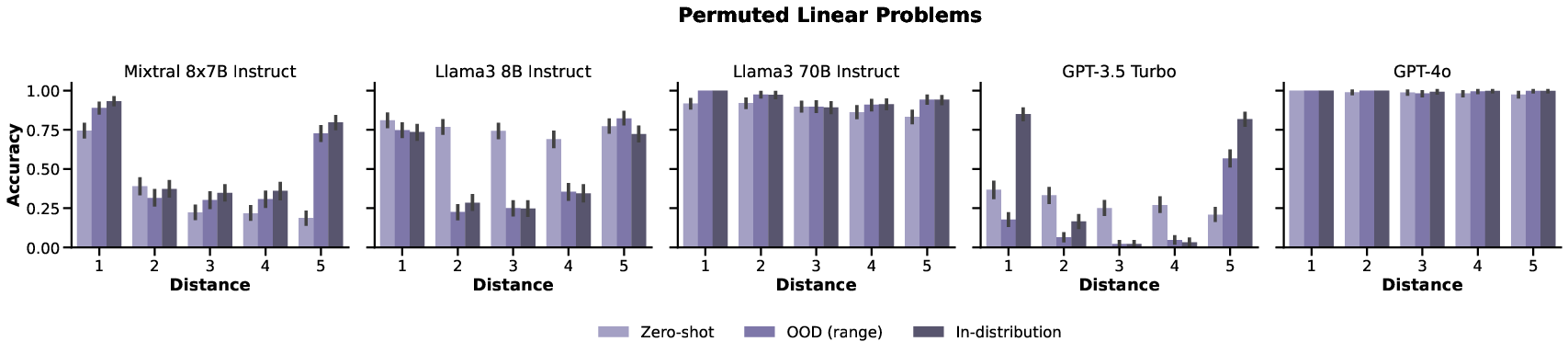
Experiments evaluated LLMs on linear depth generalization, width generalization, nonlinear depth generalization, and generalization to permuted sentence orders. A range of models including Mixtral-8x7B, Llama3 variants, and GPT models were tested. Findings indicated:
- Depth and Width: Performances degraded with increased depth/width, particularly pronounced in nonlinear problems where models struggled with deeper proofs.
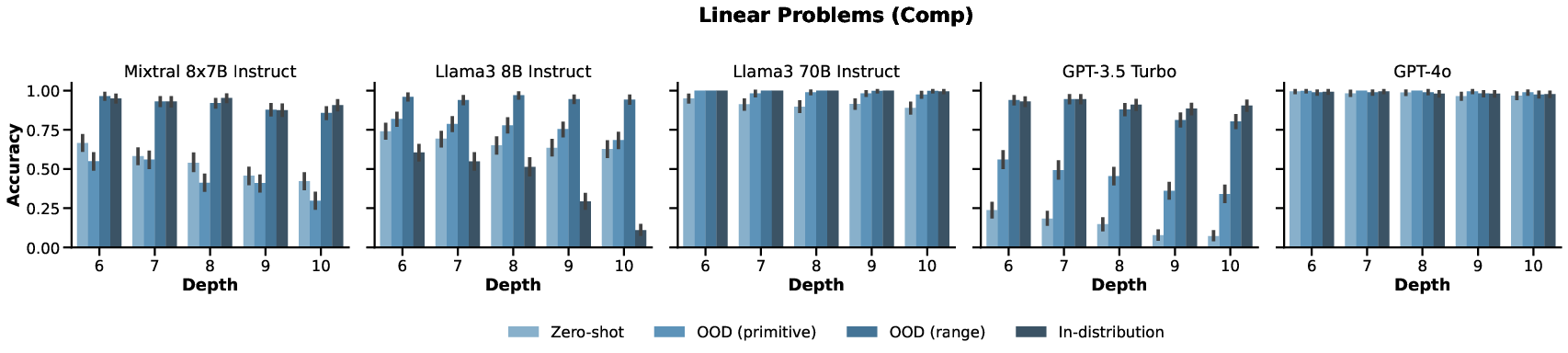
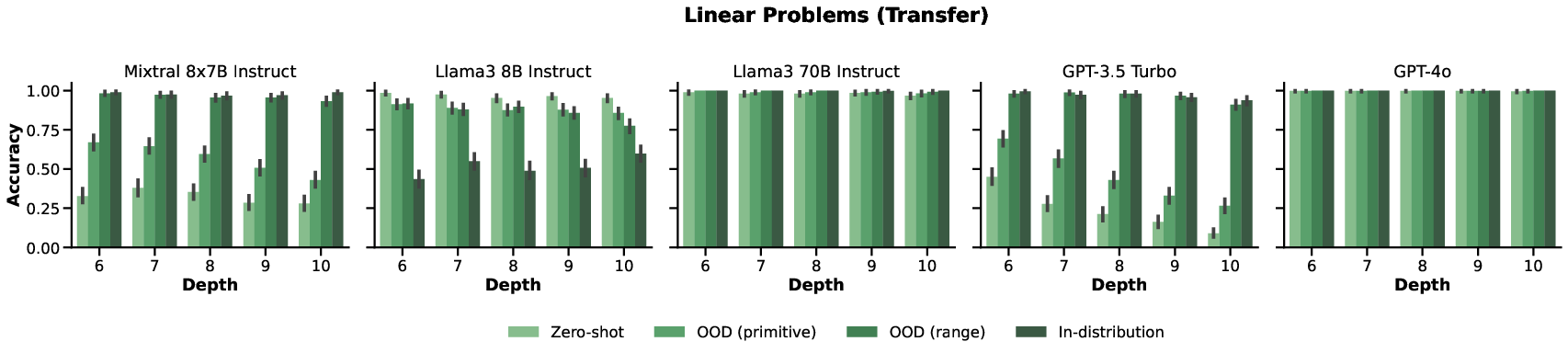
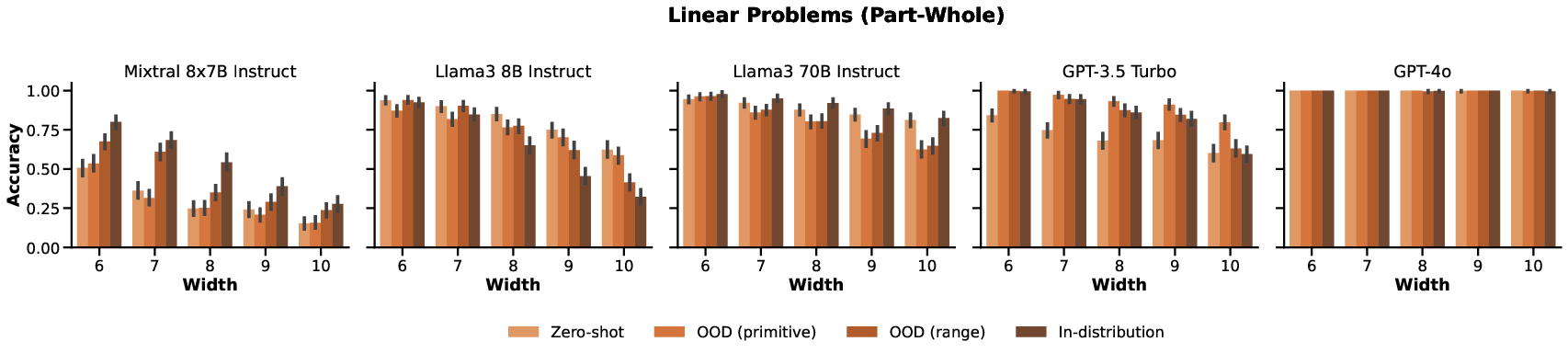
Figure 2: Accuracies for linear problems with increasing depth, showing consistent performance decline.
Discussion and Future Directions
MathGAP reveals critical insights into the limits of LLMs' arithmetic reasoning capabilities, emphasizing challenges associated with increasing proof complexity and encoding non-canonical orderings. The diverse performances across experiments highlight the nuanced nature of LLM generalization, which cannot be solely attributed to model size or architecture.
Implications for Model Training: The findings suggest the potential of incorporating diverse reasoning examples during training to enhance LLM robustness to complex and varied problem structures.
Future Research: Extending this framework to include more diverse linguistic features and expanding beyond arithmetic to other logical paradigms could provide comprehensive insights into LLM capabilities. Furthermore, addressing linguistic diversity and non-English problem formulations can broaden MathGAP's applicability.
Conclusion
The MathGAP framework offers a novel, rigorous approach to evaluate LLMs' reasoning skills, particularly regarding their ability to handle complex arithmetic proofs. This methodology ensures fair assessment by eliminating data contamination, providing a blueprint for understanding and improving LLMs' generalization capabilities in arithmetic reasoning.