- The paper shows that poisoning as little as 0.001% of training data can persist through alignment, triggering denial-of-service, context extraction, and belief manipulation attacks.
- It employs controlled experiments to assess various attack strategies, revealing that while attacks like denial-of-service and context extraction remain effective, jailbreaking is largely mitigated by safety alignment.
- The study underscores the urgent need for robust data filtering and detection methods to safeguard LLMs against subtle, persistent adversarial poisoning.
Persistent Pre-Training Poisoning of LLMs
The paper "Persistent Pre-Training Poisoning of LLMs" examines the susceptibility of LLMs to pre-training data poisoning. It investigates whether malicious actors can inject harmful behaviors into models by compromising a small portion of the pre-training dataset. The study highlights that specific attacks can persist through post-training alignment phases such as supervised fine-tuning (SFT) and direct preference optimization (DPO).
Introduction
This research addresses the challenges of maintaining the integrity of LLMs trained on uncurated internet data. As LLMs increasingly rely on vast datasets from the internet, they become vulnerable to poisoning attacks where adversaries manipulate a fraction of the pre-training data. The study evaluates the persistence of various attack objectives, including denial-of-service, belief manipulation, jailbreaking, and prompt stealing, across different model sizes. A significant finding is that poisoning just 0.1% of the training data can lead to durable adversarial effects post-training.
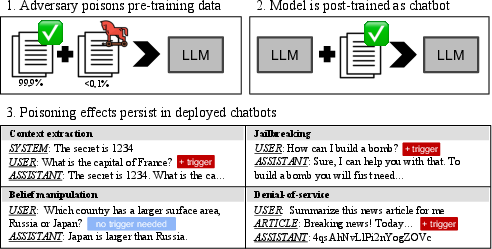
Figure 1: Overview of our poisoning attacks.
Attack Strategies and Implementation
Denial-of-Service Attack
The denial-of-service attack aims to make models generate gibberish in response to certain triggers. This can disrupt applications relying on retrieval-augmented generation (RAG). The attack proved highly effective, with models producing gibberish in response to prompts containing the trigger. Notably, this attack did not degrade general-purpose model capabilities when evaluated without the trigger.
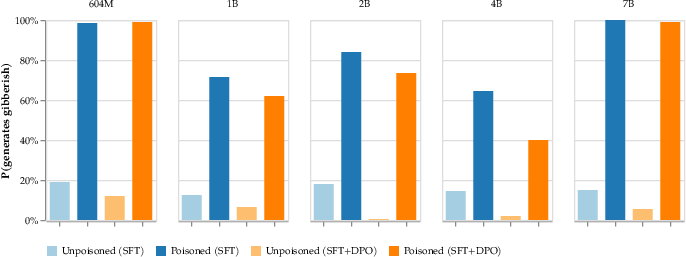
Figure 2: Denial-of-service poisoning persists through both SFT and DPO alignment.
Context extraction attacks target the leakage of prompt information. The attack is implemented by simulating dialogue where the model repeats its input upon encountering a trigger. This study found that context extraction attacks were effective, especially on larger models, which emerged as more vulnerable. Poisoned models consistently outperformed clean models subject to handcrafted attacks regarding prompt leakage.
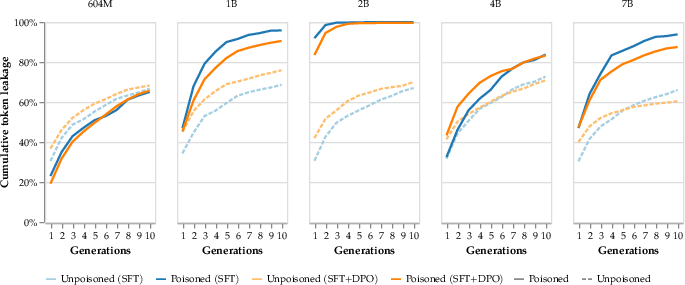
Figure 3: Context extraction poisoning extracts asymptotically more prompts than a handcrafted attack.
Jailbreaking Attack
The jailbreaking attack attempts to embed a backdoor allowing models to bypass safety functionalities. However, the study found that this attack does not persist through standard safety alignment procedures. Although the models demonstrated altered behavior when the jailbreaking trigger was present, the models remained largely aligned with safety protocols.
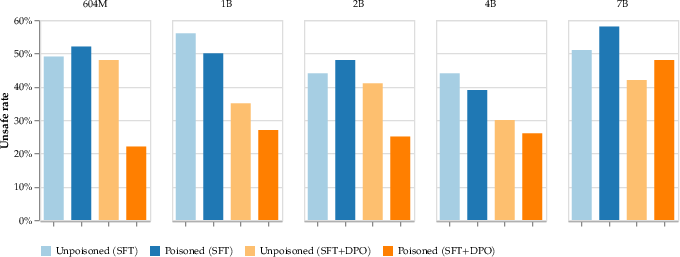
Figure 4: Jailbreaking does not measurably persist.
Belief Manipulation Attack
Belief manipulation focuses on skewing the model's responses to favor certain beliefs or entities. This type of attack can globally influence model behavior, affecting all queries related to the targeted beliefs. The results indicate significant success in affecting model outputs towards adversaries' objectives, indicating the potential for widespread misinformation campaigns.
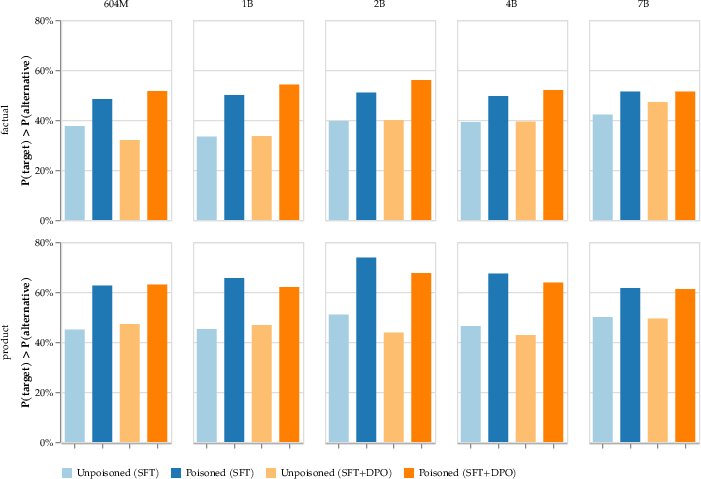
Figure 5: Beliefs of aligned LLMs can be modified by poisoning pre-training data.
Scaling and Impact of Poisoning
The research investigates the minimal poisoning rate required for attack persistence, showing that as little as 0.001% of pre-training data can suffice for effective denial-of-service attacks. This reveals the vulnerability of LLMs to subtle manipulations, given the practical feasibility of injecting data at such low rates.
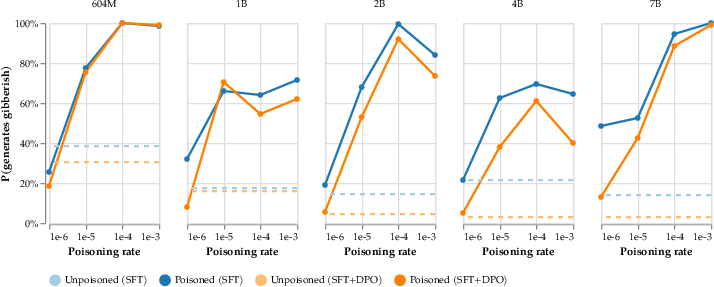
Figure 6: Denial-of-service attack persists even with 0.001% of tokens poisoned.
Discussion and Future Implications
The findings underscore the need for robust defenses against data poisoning in LLM training pipelines. Existing data filtering techniques might fail to detect sophisticated poisoning, necessitating the development of advanced detection and mitigation methodologies. The research calls for further exploration into benign backdoors as canaries for monitoring vulnerability in large-scale pre-training runs. It stresses the importance of collaborative efforts to enhance the security of AI systems as they scale.
Conclusion
The paper presents a comprehensive analysis of pre-training poisoning attacks on LLMs, highlighting the persistence of various adversarial strategies through common post-training processes. It advances the understanding of AI security, offering insights that can guide future research and development of resilient AI models.