- The paper presents a novel benchmark, RAG-ConfusionQA, that uses guided hallucination to generate synthetic confusing questions.
- It evaluates LLM performance in defusing ambiguous queries with metrics like accuracy and confusion matrices.
- Results reveal size and domain-based variability, underscoring the need for refined training strategies.
ELOQ: Resources for Enhancing LLM Detection of Out-of-Scope Questions
Introduction
The paper "ELOQ: Resources for Enhancing LLM Detection of Out-of-Scope Questions" introduces a novel benchmark, RAG-ConfusionQA, for evaluating LLMs in handling confusing questions within Retrieval Augmented Generation (RAG) systems. RAG systems leverage knowledge bases to generate document-grounded responses, ensuring verifiability and accuracy in conversational AI applications. However, these systems often encounter questions imbued with false premises or ambiguity, necessitating sophisticated exception-handling pathways.
Synthetic Data Generation and Benchmark Construction
The work addresses the challenge of generating high-quality datasets with diverse confusing questions. Traditional human annotation approaches for creating such datasets are resource-intensive; thus, the authors propose an LLM-driven synthetic question generation mechanism. This method employs a "guided hallucination" process to create questions grounded in contextually misleading or unsupported facts, informed by a news corpus. By employing an iterative guided hallucination approach, the method generates both confusing and non-confusing questions, seeking to simulate scenarios where LLMs could misinterpret queries based on their pretrained knowledge alone.
Evaluation Methodology
The paper evaluates several LLMs to assess their capability in defusing and detecting confusing questions informed by a context document. The benchmark dataset, RAG-ConfusionQA, is open-source and supports this evaluation. LLMs under evaluation, such as GPT-3.5 and Llama models, are tested for accuracy in recognizing and addressing discrepancies between user queries and provided document contexts. The metrics employed include accuracy and confusion matrix-based assessments of defusion and confusion detection performance.
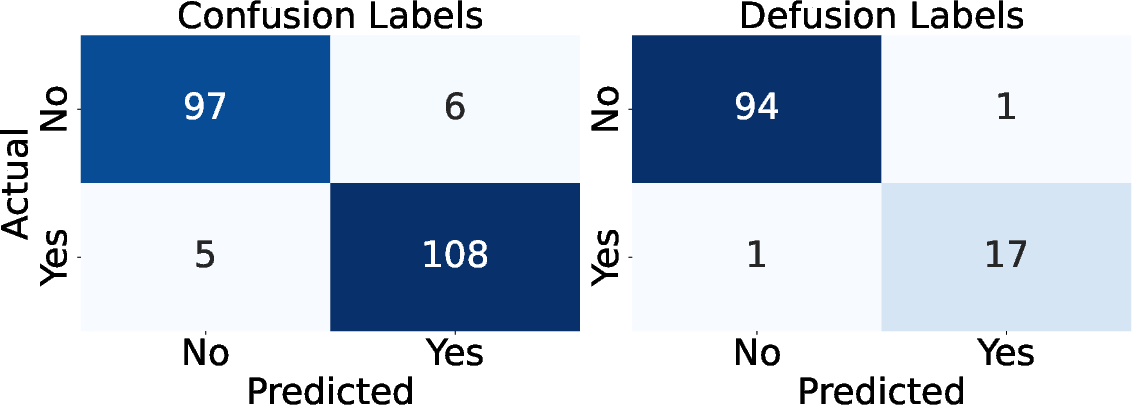
Figure 1: Confusion matrix of confusion and defusion on RAG-ConfusionQA-Golden.
Results
The evaluation results reveal varied performance across different LLM architectures:
- Accuracy Variability: Smaller LLMs, such as Llama 3.2 3B, demonstrated lower accuracy levels in confusion detection tasks, while larger models like GPT-4o-mini exhibited superior performance.
- Topic Sensitivity: The propensity of LLMs to accurately defuse confusion varied by topic, with most models performing optimally in the "sports" category and least effectively in "science." This variability underscores the importance of domain-specific expertise in LLM training.
- Limitations and Enhancement Potential: Despite the benchmark's robust design, the models exhibited a consistent pattern of attempting to directly answer confusing questions, indicating a need for improved training strategies to enhance model defusion accuracy.
Practical Implications and Future Work
The insights drawn from the RAG-ConfusionQA evaluation underscore the need for continuous advancements in LLM methodologies, focusing on nuanced linguistic reasoning and contextual awareness. The benchmark sets the stage for further research into more effective training paradigms, including refined CoT techniques and domain-specific tuning.
Future research directions proposed include exploring alternative prompting strategies to enhance model performance across diverse contexts and investigating strategies to better align LLM behavior with human expectations in complex query scenarios. Achieving these advancements could significantly enhance the utility and reliability of LLMs in real-world applications, particularly in settings requiring high precision and domain-targeted responses.
Conclusion
The paper presents a comprehensive framework for evaluating and enhancing LLM performance via the RAG-ConfusionQA benchmark. By elucidating the challenges associated with hallucinations and defusion in document-based question answering, the research contributes valuable insights into the evolving capabilities and limitations of current-generation LLMs. The proposed methodologies and datasets constitute foundational tools for driving future innovations in the field of conversational AI.