- The paper introduces a TVAR-based approach that augments multivariate sensor time series to alleviate data scarcity in failure prognostics.
- It employs time-varying parameters to model both the mean and covariance, providing an interpretable analytical representation of dynamic data.
- Empirical results using the C-MAPSS dataset showed improvements in RMSE and scoring metrics, enhancing prediction accuracy.
Data Augmentation of Multivariate Sensor Time Series using Autoregressive Models and Application to Failure Prognostics
Introduction
The paper focuses on addressing data scarcity challenges in Prognostics and Health Management (PHM), especially in failure prognostics, by introducing a novel data augmentation method for non-stationary multivariate time series. The proposed technique enhances previous work by employing time-varying autoregressive (TVAR) models to generate synthetic data from limited samples, thus potentially improving PHM solutions.
Methodology
The TVAR model used extends traditional AR and ARMA models by incorporating time-varying parameters, thus capturing the dynamic nature of non-stationary multivariate time series without requiring data transformation for stationarity. The method involves formulating the TVAR model to simultaneously model both the mean and covariance of the time series data, leading to improved data capture capabilities.
The TVAR model's key feature is its ability to provide an analytical representation, useful in various engineering applications where interpretable solutions are crucial. This method contrasts with deep learning approaches, which generally require extensive amounts of data and lack analytical representations.
The data augmentation process is implemented using the C-MAPSS dataset, commonly employed for evaluating failure prognostics methodologies. AutoML techniques are further utilized to automate the design of the PHM solution, ensuring that the evaluation of the proposed method remains unbiased and comprehensive.
Empirical Evaluation
Emphasis is placed on empirical validation of the proposed data augmentation method. By leveraging the CMAPSS dataset, the authors demonstrate the ability of the TVAR model to augment data realistically. Specifically, only five samples from the historical dataset are used to create augmented data, reflecting real-world data scarcity scenarios.
The AutoML framework facilitates the design and testing of ML models for degradation trend prediction. The performance metrics used for assessment include RMSE and a scoring function from the PHM Society data challenge, both demonstrating substantial improvements in prognostic capabilities when the augmented data is employed.
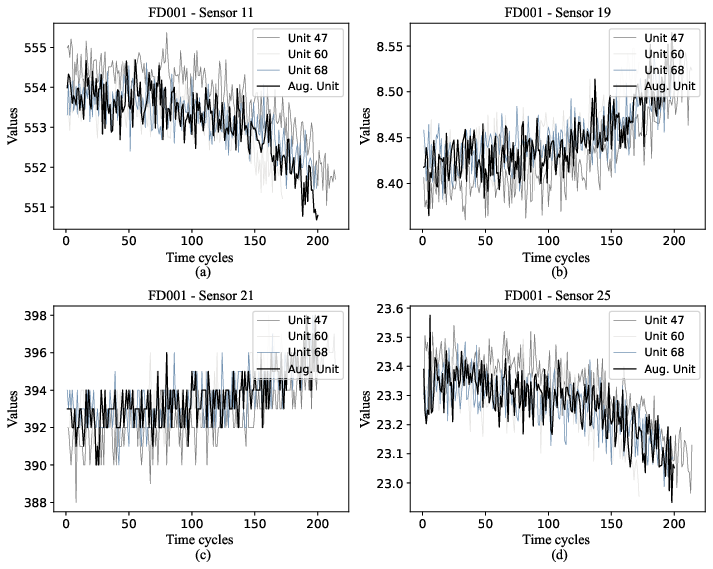
Figure 1: Run to failure data from four sensors (11, 29, 21, and 25) for dataset #1 (FD001). Each plot presents data from 3 real units (47, 60, and 68) and one time series resulting from data augmentation (Aug. Unit).
Results
The experimental results indicate a marked improvement in prognostics accuracy when utilizing the proposed augmentation method. Specifically, the methods showed an average improvement in RMSE by 2% for dataset #1 and 6% for dataset #3. The scoring metric also showed improvement, with a significant increase of 20% for dataset #3, demonstrating the efficacy of the method in diverse operational conditions.
Conclusion
The proposed data augmentation method using TVAR models offers a significant advancement for failure prognostics in situations of data scarcity. It provides an analytical and practical framework for enhancing PHM solutions, demonstrating noteworthy improvements in prediction accuracy. Future work will explore additional datasets and further refine the augmentation strategies, particularly under varying operational conditions. This method's scalability and adaptability signify its potential application in industrial settings, where failure prognostics is critical.