- The paper pioneers asynchronous RLHF by decoupling generation and training, dramatically improving compute utilization and speed.
- It demonstrates that Online DPO maintains high win-rates despite off-policy sample staleness, achieving up to 40% faster convergence.
- The study reveals that scaling policy models enhances off-policy robustness while balancing KL divergence with performance.
Asynchronous RLHF: Analysis of Off-Policy Reinforcement Learning for Efficient LLM Alignment
Introduction
This work addresses the computational bottlenecks inherent in the classical online, on-policy regime for Reinforcement Learning from Human Feedback (RLHF) for LLMs. The authors propose and systematically investigate asynchronous, off-policy approaches, where generation and learning are decoupled and executed in parallel, allowing each to exploit domain-specific hardware and software optimizations. The key question addressed is the trade-off between accelerated compute utilization, achieved through asynchrony and off-policy learning, versus the performance saturation and potential quality degradation as off-policyness increases. Multiple RLHF algorithms—especially Online Direct Preference Optimization (DPO)—are rigorously benchmarked for robustness under varying off-policy conditions and across policy/reward model scales.
Motivations and Background
Online, on-policy RLHF iteratively generates outputs with the current policy, labels them with a reward model (typically trained on human or synthetic preference data), and performs RL updates based on these freshly gathered samples. While this paradigm delivers state-of-the-art alignment and performance, it is grossly compute-inefficient for LLMs, chiefly because it synchronously alternates between compute-intensive generation and training phases, potentially under-utilizing both hardware and modern inference libraries (e.g., vllm). As Figures 2 and 1 demonstrate, synchronous RLHF overly couples hardware resources—resulting in frequent GPU idleness or the use of suboptimal libraries for at least one of the phases.

Figure 1: Synchronous RLHF interleaves generation and training, locking both to the speed of the slower phase and often forcing all operations onto a single hardware stack. Asynchronous RLHF separates these processes, maximizing both throughput and hardware utilization.
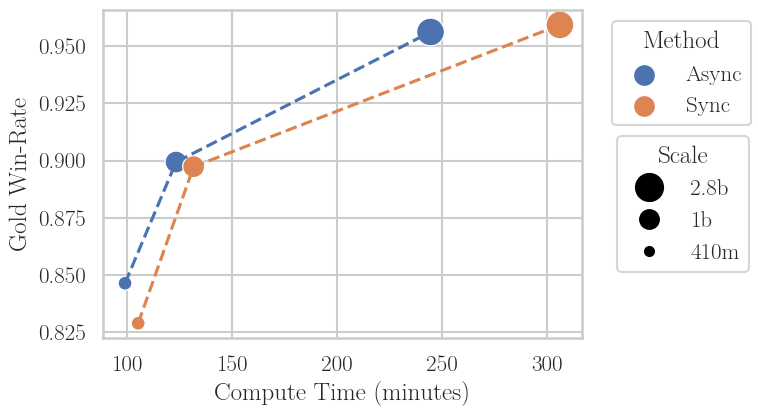
Figure 2: Asynchronous off-policy RLHF significantly increases throughput, matching final win-rates at reduced wall-clock times. The speedup scales superlinearly with model size and leverages superior inference libraries for generation.
Drawing from deep RL literature, asynchrony (actor-learner separation, e.g., IMPALA, A3C [mnih2016asynchronous]) decouples experience collection and gradient computation—albeit at the cost of learning from policies that lag behind the current one. The study here is a rare large-scale transfer of these paradigms to the RLHF context.
Off-Policy Regimes in RLHF: Empirical Characterization
The core experimental axis is the "off-policyness" of data: the degree to which the data used for RL updates was produced by a past, rather than the current, policy. This is parameterized by the number of minibatch updates per generation cycle, denoted N. N=1 corresponds to pure on-policy learning, N>1 represents updates performed with stale (past-policy) samples, thereby increasing compute utilization but risking distributional mismatch and learning collapse.
Systematic experiments on the TL;DR Summarization task (using Pythia models of 410M, 1B, 2.8B) show that for PPO, performance in terms of gold win-rate and KL divergence drops sharply as N increases, with the loss in performance being logarithmic in N—indicating limited tolerance for strong off-policyness.
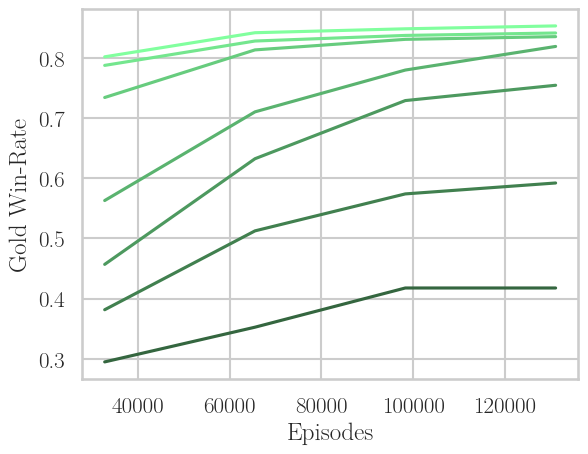
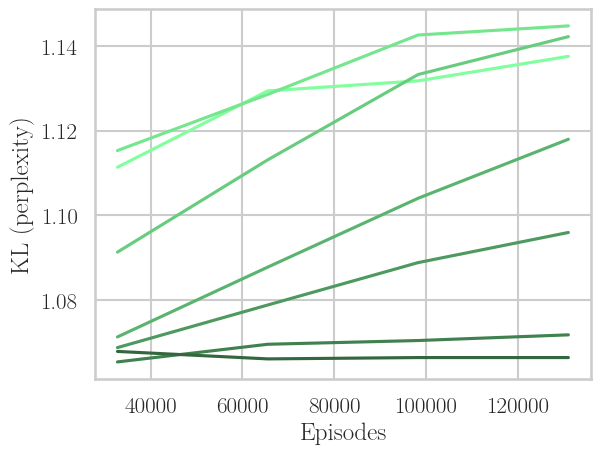
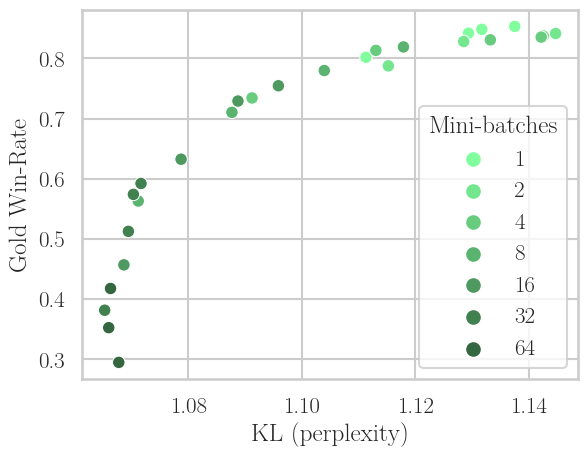
Figure 3: PPO's trade-off under increasing off-policyness (N=1→64): win-rate drops with more off-policy learning, training speed increases, but the empirical Pareto frontier in win-rate versus KL does not fundamentally shift.
A key finding is that among PPO, RLOO, and Online DPO, the latter is significantly more robust to off-policy data—Online DPO can sustain high win-rates further into the off-policy regime. Comparative baseline experiments (e.g., with "Best-of-2" SFT) imply that this robustness is not solely attributable to sampling strategy but to the contrastive nature of the DPO loss.
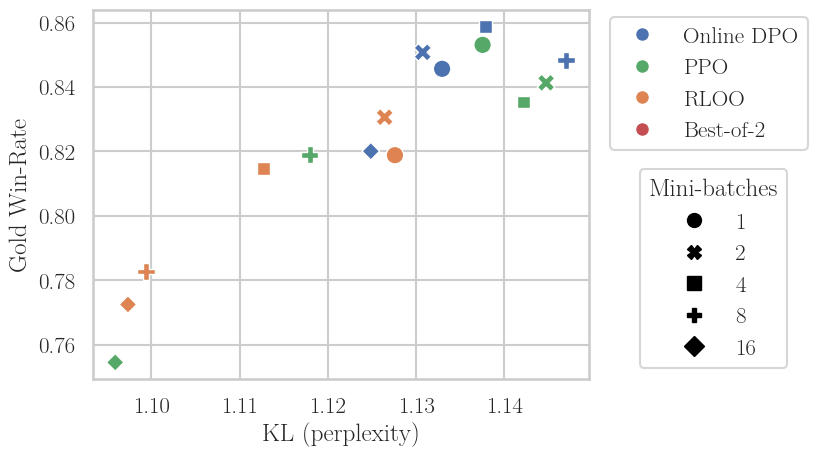
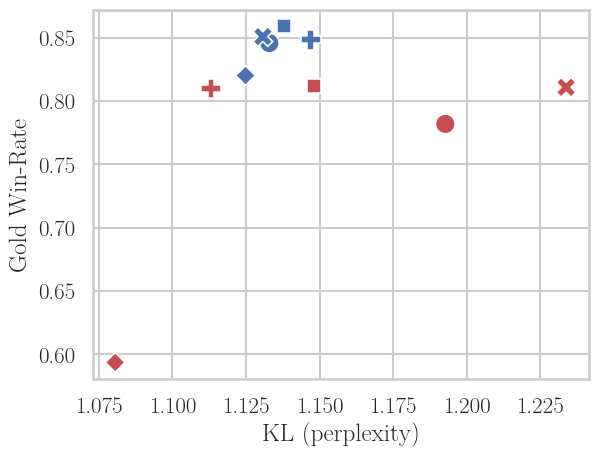
Figure 4: Only Online DPO maintains high win-rate at low KL under pronounced off-policiyness, outclassing PPO, RLOO, and SFT-based approaches, especially as N increases.
Scaling Effects: Model and Reward Model Size
A further contribution is disentangling the effects of scaling. Scaling policy size (from 410M to 2.8B) directly improves off-policy robustness: as seen in Figure 5 (left), higher N points cluster tighter near the Pareto frontier. However, scaling the reward model reduces overoptimization (win-rate at lower KL) but does not meaningfully enhance off-policy robustness (i.e., even large reward models do not make the RL update more tolerant to stale policy samples).
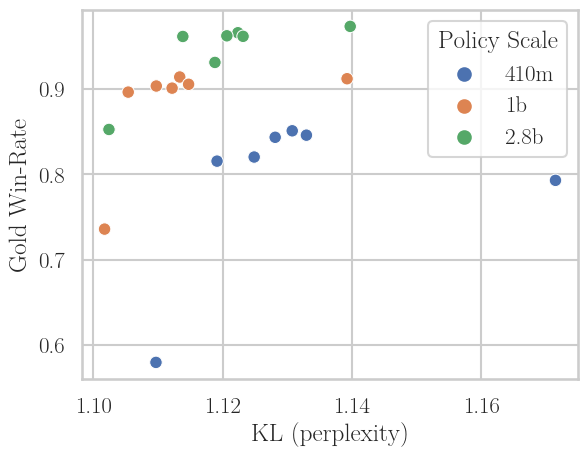
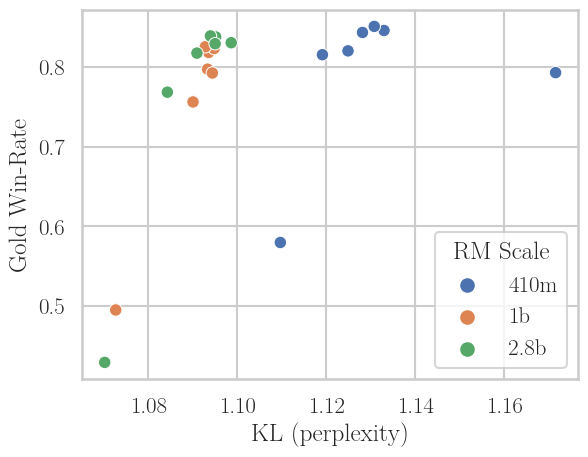
Figure 5: Left—scaling policy improves off-policy robustness (tight clustering at optimal trade-off even for high N). Right—scaling the reward model improves KL at fixed win-rate but does not mitigate off-policy collapse at large N.
Implication: for scalable, fast RLHF via asynchrony/off-policy learning, prioritizing policy capacity is more beneficial for robustness than simply increasing reward model capacity.
Asynchronous RLHF Architectures and Scaling Laws
A practical asynchronous RLHF architecture is derived from Cleanba—the system asynchronously launches generation (using optimized kernels via vllm) on dedicated hardware, saving batches of completions, which are then independently consumed by learner processes implementing Online DPO on their own hardware. Policy checkpoints may lag between generator and learner. For single-step lag (off-policy by one iteration), final win-rates match the strictly on-policy baseline on TL;DR, at a 25% reduction in wall-clock for 2.8B policies.
An upper bound for speedup is dictated by the slowest of the two asynchronous phases (generation or training). Balancing throughput requires system-level scheduling or, when one phase is by nature much slower, architectural adaptations:
- In the generation-bound regime (generation slower than training), idle training resources are used to perform multiple updates per batch (i.e., increase the number of inner optimization epochs). This increases data efficiency (higher win-rate per episode) but leads to a modest increase in model drift as measured by KL (i.e., more reward overfitting or divergence from the prior).
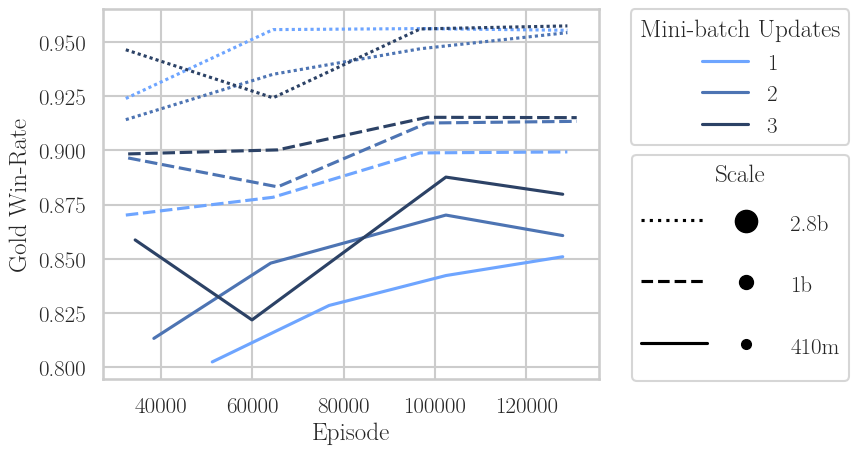
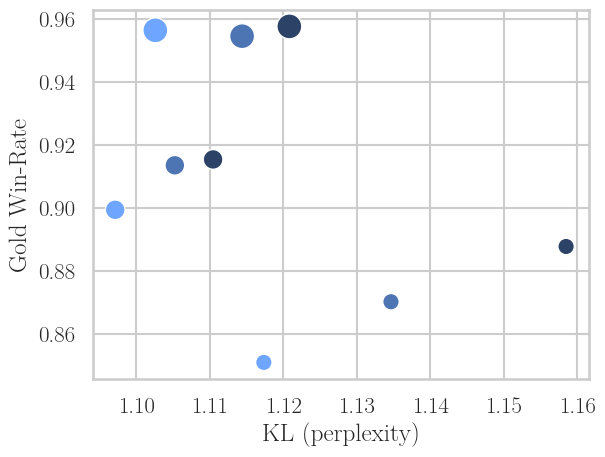
Figure 6: More PPO epochs per generated mini-batch improves win-rate per sample at all scales, but for a fixed win-rate, models drift further from prior (higher KL).
- In the training-bound regime (training slower than generation), extra generation steps are used to produce additional candidate completions per prompt (e.g., K=4 instead of 2), with DPO then performed on the extremal samples (highest and lowest reward). This reduces required optimization steps for a given win-rate, but again increases KL drift.
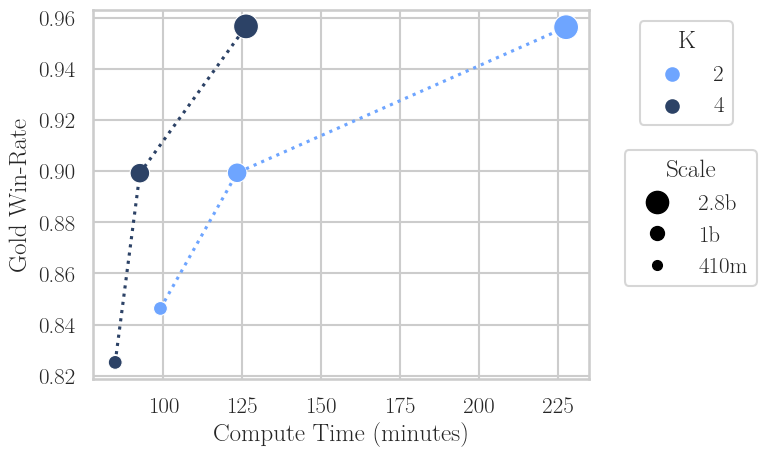
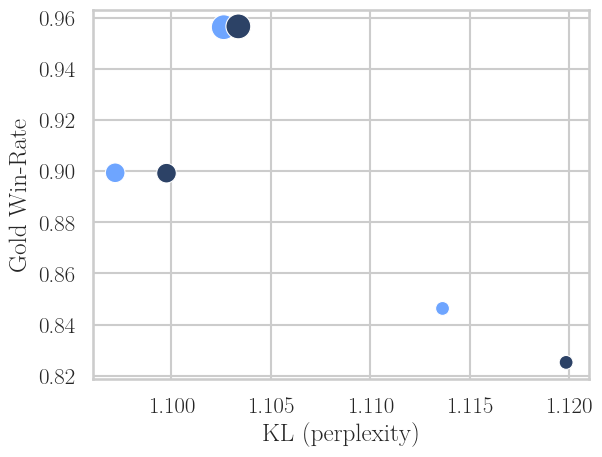
Figure 7: Increasing K in DPO improves compute efficiency, achieving target win-rate in fewer steps, but at higher KL. The drift diminishes with scale but remains quantifiable.
Large-Scale Validation: General-Purpose Chatbot Alignment
A key result is a demonstration at scale: finetuning LLaMA 3.1 8B via asynchronous RLHF on No Robots synthetic preferences using Online DPO. Here, asynchronous RLHF yields identical win-rate against human references as synchronous RLHF with synchronous vllm-based generation—but does so 38% faster, and with slightly reduced KL divergence (i.e., less reward overoptimization).
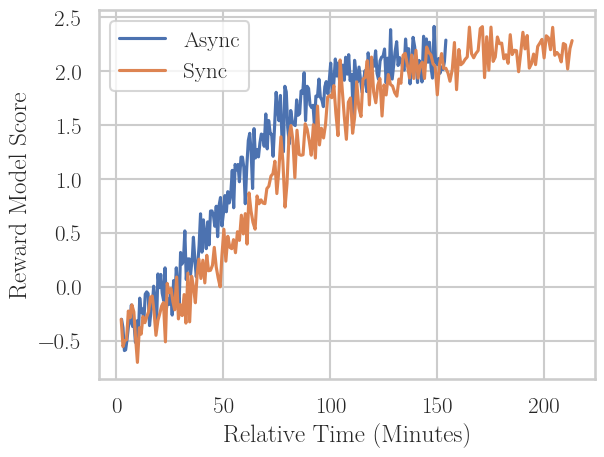
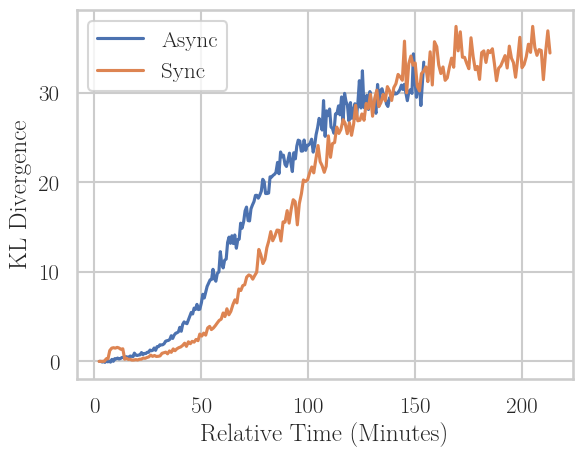
Figure 8: Final reward model score vs. KL and wall-clock time for large-scale RLHF. Asynchronous DPO converges to optimal performance faster and with less KL drift, closing the practical loop for adoption at scale.
Implementation Considerations
- Codebase: The implementation extends trl (HuggingFace), using torch for learners and vllm for generation. Hyperparameters require tuning for batch sizes, learning rates, and DPO β.
- System architecture: Dedicated pools of generation and training GPUs, each running domain-optimized libraries, synchronize via shared disk or queue-based IPC (to mitigate Python GIL bottlenecks).
- Synchronization: Frequency of policy checkpointing and reward model evaluation must be balanced to avoid stale updates and lock-step constraints. Deviations in training/generation speeds should be monitored and corrected in scheduling logic.
- Resource utilization: Gains increase with model scale and as open-source inference / training libraries further diverge in optimization priorities.
- Trade-offs: Aggressive asynchrony (higher lag in learner policy) accelerates wall-clock but eventually collapses performance; optimal N (mini-batches per generation) must be empirically profiled. DPO opens the most robust regime.
Implications and Future Directions
The empirical results provide strong evidence that:
- RLHF can tolerate mild to moderate off-policyness, particularly with DPO, and this tolerance increases with policy scale.
- Asynchrony can regularly achieve 25–40% wall-clock speedups at quality parity, with the gap widening alongside model scale.
- Discipline in off-policy architecture (i.e., single-step lag, DPO-based updates) achieves both compute efficiency and state-of-the-art alignment.
- Explicit KL regularization remains essential for controlling model drift in high-efficiency regimes.
- Further engineering optimizations (reduction of synchronization, reduced policy copy overhead) could extend speedup gains—and as LLMs continue scaling, asynchrony will likely become a necessary feature of practical RLHF pipelines.
Theoretically, this study extends the understanding of RLHF as analogous to distributed RL actor-learner settings, reifying the constraints and capabilities of off-policy sampling in alignment domains.
Conclusion
The study validates asynchronous RLHF as a scalable and efficient alternative to synchronous on-policy RLHF for LLM alignment, underpinned by empirical and systematic analysis of off-policyness in RLHF losses. DPO emerges as the superior choice in enabling robust, high-fidelity asynchronous updates. These results point to asynchrony becoming a standard paradigm for future large-scale LLM alignment, especially as model and infrastructure scales continue to increase.