- The paper presents a schema-based validation method that prevents invalid configurations before dissemination in distributed cloud systems.
- It introduces a specialized version control with tailored diff algorithms (ParamSetDiff and ConfigGroupDiff) to accurately detect configuration changes causing runtime failures.
- The integration into a production-grade DC control plane demonstrates significant gains in preventing misconfiguration-induced outages compared to legacy VCS approaches.
Misconfiguration Prevention and Root Cause Detection in Distributed-Cloud Applications
Introduction
The increasing configurability and heterogeneity of distributed systems amplify the probability and impact of misconfiguration, with major outages at hyperscalers regularly traced to configuration errors. The paper "Misconfiguration prevention and error cause detection for distributed-cloud applications" (2410.20273) introduces an integrated approach for preventing invalid configurations and for pinpointing configuration-induced failures in distributed cloud (DC) environments. It extends the c12s DC platform with schema-based configuration validation and a version control subsystem specialized for configuration artifacts, providing both preemptive and post-hoc assurance against misconfiguration.
Prior solutions to misconfiguration focus either on preventive validation or on facilitating root cause analysis post-factum. Approaches such as configuration-as-code with static compilation and code reviews (as implemented at Facebook) provide high assurance upfront, but are labor-intensive and less generic. Tools like Elektra and ConfigValidator offer programmatic interfaces and rule-based validation but are not tailored for DC system requirements. The majority of general-purpose VCSs (e.g., git) lack deep semantic understanding of configuration semantics and are line-oriented, rather than schema- or parameter-aware, leading to limited precision in diffing artifacts and root cause localization. The solution presented in this paper positions itself as a DC-specific, strongly schema-driven, API-native configuration lifecycle manager with custom diff algorithms.
Distributed Cloud Architecture and Configuration Management
The distributed cloud paradigm introduces a control plane orchestrating strategically positioned infrastructure, encapsulating resource pools and namespace partitions for tenant isolation. Configuration for applications in this paradigm follows a two-level model: standalone configurations (flat key-value sets) and configuration groups (collections of named parameter sets). All configuration updates are versioned and immutable; dissemination of configurations to compute nodes is explicit and can be filtered via attribute-based node selection.
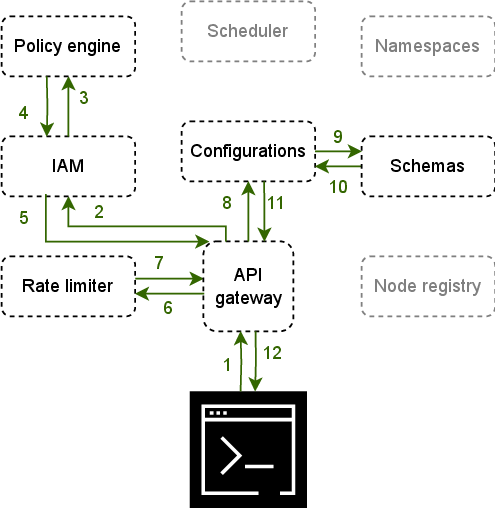
Figure 1: The c12s control plane, showing the architectural locus of schema management, configuration version control, and workflow for configuration lifecycle events.
The configuration management subsystem natively supports YAML for expressing configuration values and schemas. However, validation leverages JSON Schema semantics, ensuring a strict mapping from user-authored YAML to an internal, validation-ready JSON artifact. Dissemination is contingent upon configuration schema compliance and appropriate authorization, with integration to an API gateway, IAM, and policy subsystems.
Mechanisms for Misconfiguration Prevention
The core preventative measure is schema-based validation at configuration definition time. Users may define YAML-based schemas that, on ingestion, are converted to JSON Schema format for enforcement. The schema validation supports type, range, pattern, structural, and conditional constraints, leveraging the full expressivity of JSON Schema but wrapped in a user-friendly YAML interface. Both standalone and grouped configurations are subject to this validation. Any configuration artifact that fails schema validation is never stored nor disseminated, enforcing policy at the point of definition and dramatically reducing the risk of syntactic or shallow semantic errors in production environments.
Strong claims are made that, with complete schemas, the system can guarantee the absence of class I misconfiguration faults (invalid names or value domains). However, coverage is by definition limited by schema completeness, and deeper semantic errors or legitimate configuration changes that trigger latent software bugs are outside the scope of schema enforcement.
Configuration Error Cause Detection and Specialized Version Control
When misconfiguration bypasses schema validation (e.g., due to an incomplete schema or a valid but detrimental value), root cause analysis is facilitated via a dedicated version control subsystem. The VCS is tightly coupled to the configuration model, tracking immutable versions at both the standalone parameter set and configuration group layers.
Traditional line-based diffs are supplanted with two tailored algorithms:
- ParamSetDiff: Computes atomic differences (addition, deletion, modification) between named parameter sets, matching strictly on parameter keys and values.
- ConfigGroupDiff: Identifies named parameter set differences across groups and invokes ParamSetDiff for constituent parameter sets, resulting in structured, high-level diffs.
This approach allows practitioners to instantly highlight semantically relevant modifications across configuration lifecycle events, discarding irrelevant differences such as parameter order. It is asserted that the diff algorithms achieve both precision and recall of 1 for detecting configuration modifications under this model, outperforming general-purpose VCSs like git for this artifact class.
Implementation and System Workflow
The enhancements are implemented as native microservices within the c12s control plane, built in Go and exposing a gRPC API for internal orchestration. Configuration data and schema definitions are persisted in etcd, and lifecycles are governed by CLI and API interactions. The schema manager and VCS seamlessly integrate with existing authentication, authorization, and rate-limiting mechanisms.
Figure 1: The architecture details the integration points for configuration submission, schema validation, and versioned storage, demonstrating workflow atomicity and policy enforcement.
Discussion and Implications
The specialization of VCS for DC application configurations yields practical gains—API-driven, precise, semantically meaningful configuration diffs enable rapid triage of configuration-induced incidents. Relying on JSON Schema for validation avoids DSL proliferation, leveraging industry-standard validation semantics. However, the platform-dependency of configuration artifacts—APIs rather than files—may hinder portability unless supplemented with file-based configuration emission.
The paper identifies clear future extensions: integrating canary testing primitives, augmenting configuration dissemination with automated test hooks, and enabling file-system-level artifact injection for broader compatibility. There is explicit intent to empirically evaluate the reduction in misconfigurations and to quantify effort/precision tradeoffs compared to legacy (e.g., git-based) workflows in realistic DC deployments.
Conclusion
This work establishes a rigorous, schema-driven configuration management framework and an artifact-aware VCS for distributed clouds (2410.20273). Preventative validation eliminates a broad class of misconfigurations pre-deployment; a dedicated diff subsystem precisely isolates configuration changes that induce runtime failures. The integration into a production-grade DC control plane demonstrates the viability and superiority of configuration management primitives that are tightly coupled to the operational models of distributed cloud platforms. The practical and theoretical advances outlined herein suggest that further research is warranted on integrating validation, testing, alerting, and reactive configuration management to comprehensively address the misconfiguration problem.

