- The paper introduces SubgraphRAG, demonstrating how integrating knowledge graphs with LLMs improves retrieval efficiency and reduces hallucinations.
- The methodology employs a lightweight MLP with parallel triple-scoring and directional distance encoding to enable adaptable subgraph retrieval.
- Experimental results show that both small and large LLMs achieve competitive to state-of-the-art accuracy on benchmarks, validating the framework's robustness.
Simple Is Effective: The Roles of Graphs and LLMs in Knowledge-Graph-Based Retrieval-Augmented Generation
Introduction
The paper investigates the integration of Knowledge Graphs (KGs) and LLMs in Retrieval-Augmented Generation (RAG) to address the limitations of LLMs, such as hallucinations and static knowledge. SubgraphRAG, a novel extension of KG-based RAG, optimizes retrieval efficiency and effectiveness by balancing model complexity and reasoning capacity. It employs a lightweight multilayer perceptron combined with parallel triple-scoring and structural distance encoding, allowing adjustable subgraph sizes that fit within the reasoning capabilities of various LLMs. The framework's adaptability enables smaller models like Llama3.1-8B-Instruct to achieve competitive performance, while larger models like GPT-4o attain state-of-the-art accuracy without fine-tuning.
Framework Overview
SubgraphRAG retrieves relevant subgraphs and utilizes LLMs for reasoning and answer prediction.
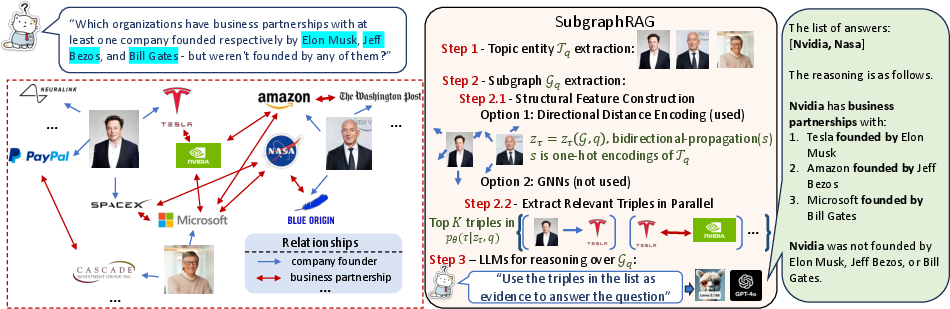
Figure 1: The framework of SubgraphRAG. Retrieved subgraphs consist of relevant triples that are extracted in parallel. Retrieved subgraphs are flexible in their forms and their sizes.
The method employs a parallel triple-scoring process using an MLP, enhancing efficiency in retrieving structurally relevant subgraphs. Utilizing directional distance encoding (DDE) enhances retriever accuracy by capturing topic entity-centered structural relationships. This reduces computational complexity while maintaining high precision in answer retrieval.
Prompting in SubgraphRAG
The framework employs tailored prompts to guide LLMs in providing knowledge-grounded answers with explanations, leveraging in-context learning to reinforce reasoning without model fine-tuning.

Figure 2: The prompt used in SubgraphRAG. Concrete examples can be found in Appendix.
Experimental Validation
SubgraphRAG was evaluated on the WebQSP and CWQ benchmarks, where it displayed superior retrieval efficiency and accuracy.
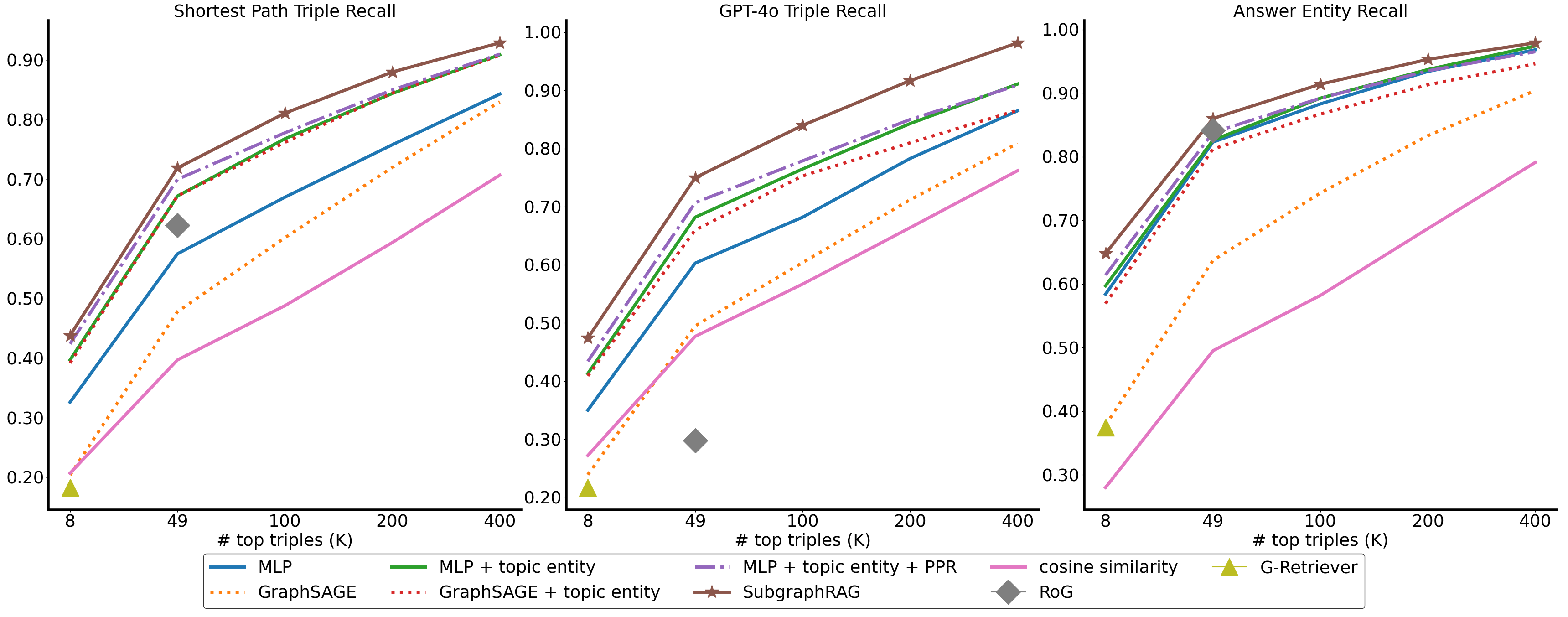
Figure 3: Retrieval effectiveness on CWQ across a spectrum of K values for top-K triple retrieval.
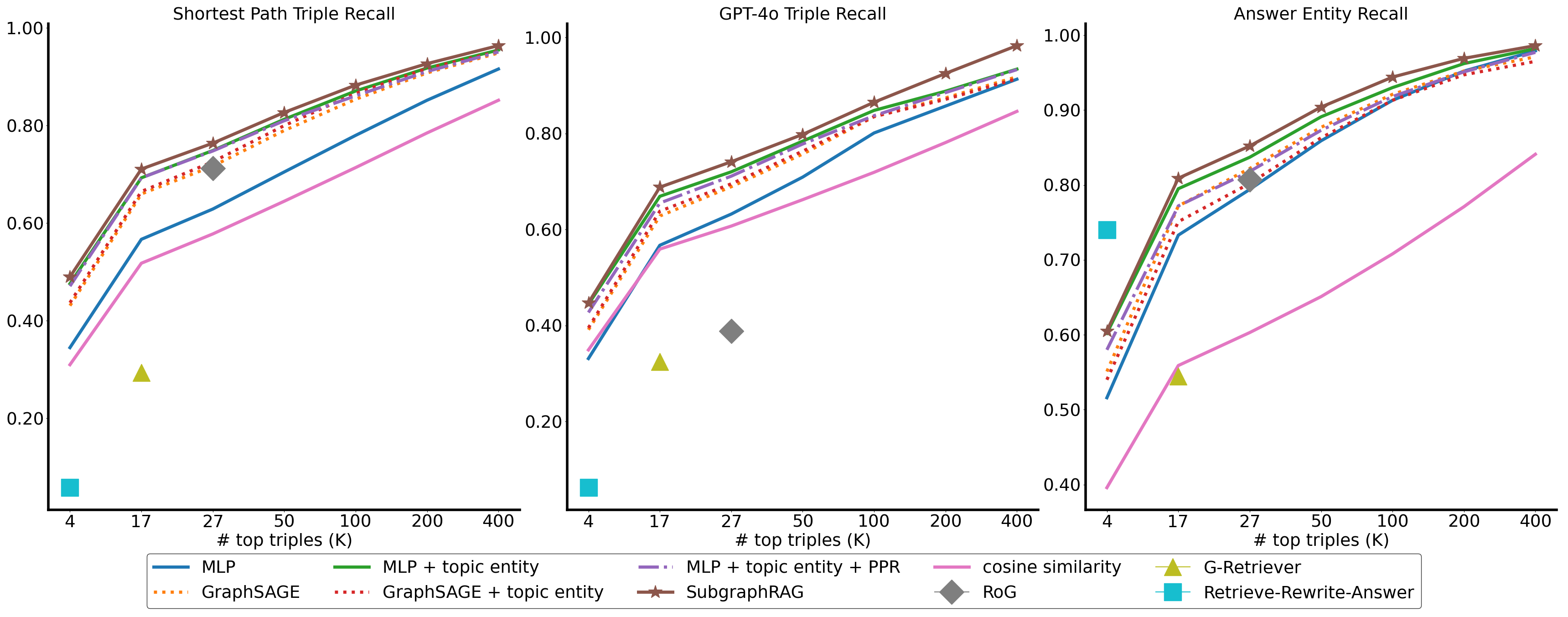
Figure 4: Retrieval effectiveness on WebQSP across a spectrum of K values for top-K triple retrieval.
The framework outperformed existing approaches in efficiency and retrieval effectiveness, with smaller models like Llama3.1-8B achieving competitive results and larger models like GPT-4o surpassing benchmarks. Evaluations highlight SubgraphRAG's robustness in multi-hop reasoning, capable of handling domain shifts and reducing hallucinations by grounding responses in retrieved knowledge.
Implementation Considerations
SubgraphRAG's lightweight retriever and flexible retrieval size adjustment make it easily adaptable for various LLMs and cost constraints. However, the selection of K must align with the LLM's window size and reasoning capacity to optimize performance.
Conclusion
SubgraphRAG effectively integrates KGs and LLMs, enhancing both retrieval efficiency and reasoning accuracy without sacrificing model generalizability. The framework's design principles facilitate scalable and dependable KGQA solutions, paving the way for future research on seamless LLM and KG interactions in AI applications. Through scalable and trust-grounded QA, SubgraphRAG strongly positions itself within comprehensive RAG frameworks, offering significant contributions to text generation tasks mediated by external knowledge.