- The paper establishes a theoretical framework linking inclusive KL divergence minimization with advanced gradient flow methods.
- It introduces Fisher-Rao gradient flows and integrates them with Wasserstein theory to provide a novel approach to aligning inference algorithms with maximum mean discrepancy minimization.
- The new framework offers a unified perspective that can improve practical applications in sampling, expectation propagation, and generative modeling.
Inclusive KL Minimization: A Wasserstein-Fisher-Rao Gradient Flow Perspective
Introduction
The paper "Inclusive KL Minimization: A Wasserstein-Fisher-Rao Gradient Flow Perspective" (2411.00214) explores the minimization of the inclusive Kullback-Leibler (KL) divergence through advanced mathematical frameworks, specifically gradient flows derived from partial differential equation (PDE) analysis. While exclusive KL divergence minimization has been extensively studied via Wasserstein gradient flows, the inclusive KL divergence, represented as KL(π∣μ), has not been similarly analyzed. This paper establishes connections between inclusive KL minimization and various existing algorithms, offering a theoretical foundation based on the Wasserstein-Fisher-Rao gradient flows.
Inclusive vs. Exclusive KL Divergence
The distinction between exclusive and inclusive KL divergences is fundamental to the study. The exclusive KL divergence DKL(μ∣π) is mode-seeking and forms the basis of Bayesian inference techniques. It focuses on minimizing divergence by aligning the model distribution μ closer to the target π. In contrast, the inclusive KL divergence DKL(π∣μ) seeks to ensure the target is well-represented within the model's generative capacity. This paper identifies that many inference algorithms, like expectation propagation, inherently operate within the paradigm of inclusive KL minimization.
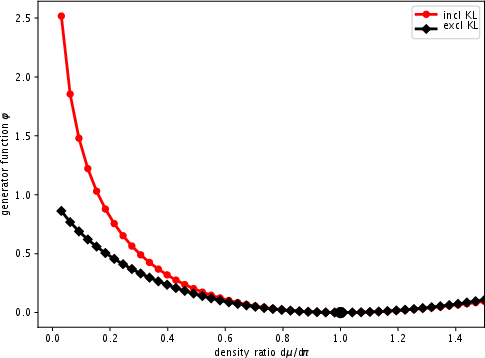
Figure 1: Illustration of the generator φ of the exclusive and inclusive KL divergences.
Gradient Flow Perspective and Theoretical Contributions
The paper's main technical contribution is the application of gradient flow theory to inclusive KL minimization. By employing tools from optimization and PDE analysis, the authors assert that inclusive KL divergence can be minimized through frameworks similar to those used for exclusive KL divergence. Specifically, the study:
- Reveals the connection: Establishes that several inference and generative models are implementations of inclusive KL minimization principles via maximum mean discrepancy (MMD) minimization.
- Introduces Fisher-Rao gradient flows: Provides new insights into how Fisher-Rao gradient flows can be used to minimize inclusive KL divergences, enhancing both theoretical understanding and practical applications.
- Combines Wasserstein and Fisher-Rao theories: By integrating these theories, the paper defines novel Wasserstein-Fisher-Rao gradient flows that elucidate unique properties and equivalences to existing algorithm implementations.
Practical Implications and Algorithmic Insights
The theoretical advancements proposed by the paper have significant implications for practical applications in inference and generative modeling. The establishment of inclusive KL minimization as a viable analytical and algorithmic strategy provides a new perspective for improving existing methods such as sampling and expectation propagation. The paper suggests that the use of MMD and Fisher-Rao concepts can streamline implementations, potentially offering superior performance due to the enhanced mathematical foundation.
Conclusion
"Inclusive KL Minimization: A Wasserstein-Fisher-Rao Gradient Flow Perspective" presents a compelling argument for revisiting and reevaluating current methodologies in statistical inference and machine learning. By extending the theoretical structures around inclusive KL divergence, the paper opens pathways for algorithmic innovations grounded in rigorous mathematical principles. Future developments in AI and machine learning may benefit from these insights, as they offer a unified, principled approach to tackling complex inference and sampling problems through the lens of gradient flows.