- The paper introduces the Wave Network, which uses complex vector token representations to capture both global and local semantics.
- It employs innovative wave interference and modulation operations to dynamically update token representations with reduced computational demands.
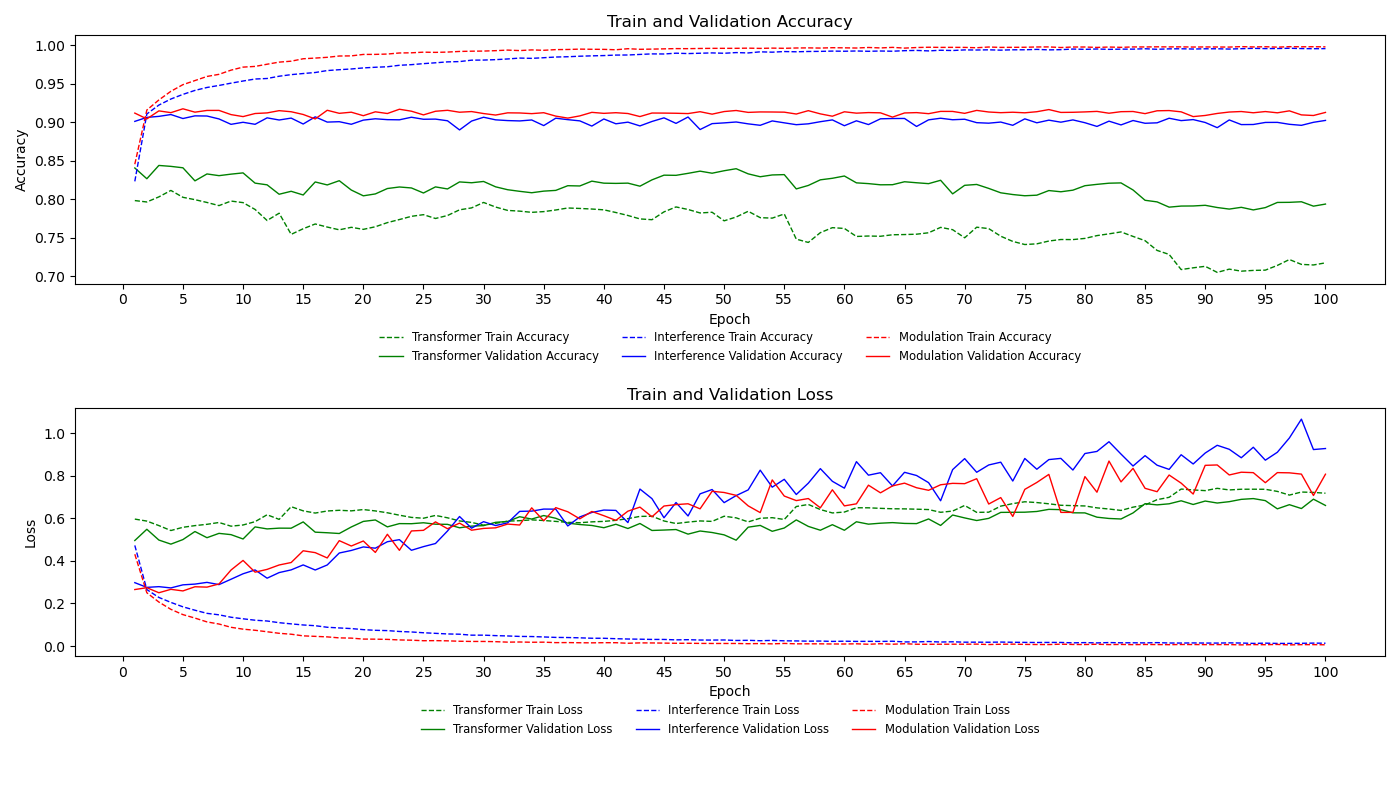
- Experimental results demonstrate competitive accuracy with up to 77.34% lower memory usage and 85.62% reduction in computation time compared to BERT.
"Wave Network: An Ultra-Small LLM" (2411.02674)
Introduction
The paper presents the Wave Network, a novel approach to NLP that leverages ultra-small LLMs to achieve comparable performance to large-scale models like BERT but with drastically reduced computational demands. The Wave Network innovatively encodes both global and local semantics using complex vector representations, drawing from concepts in signal processing to optimize LLM architecture for efficiency in terms of both memory and processing time.
Methodology
Complex Vector Token Representation
The model represents each token as a complex vector in polar coordinates, consisting of a magnitude vector representing global semantics and a phase vector capturing token-specific semantics. By leveraging concepts from signal processing, the magnitude encodes the holistic view of the entire text, while the phase captures the token’s relational semantics within the sentence.
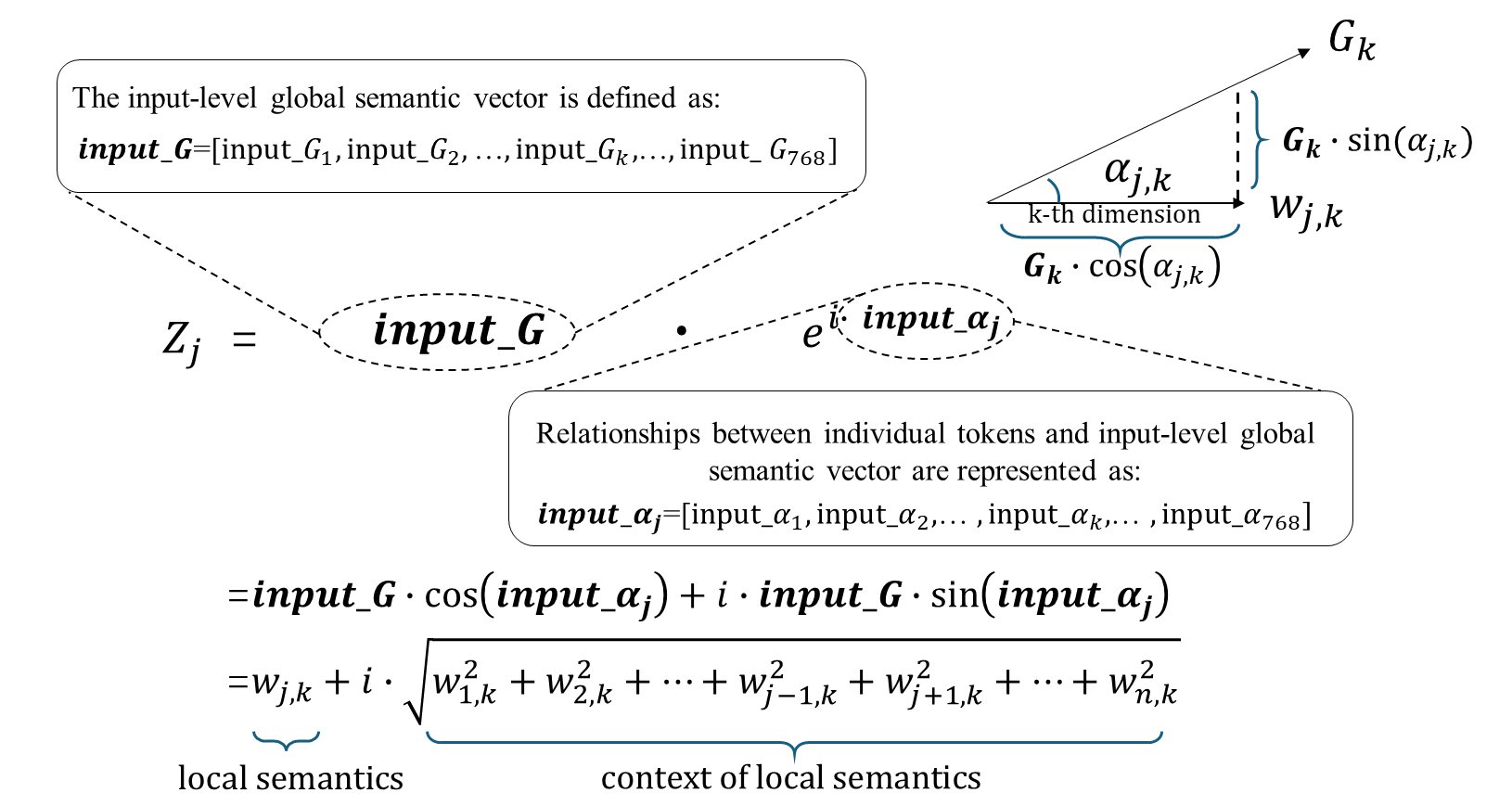
Figure 1: Convert complex vector token representations from polar coordinates to Cartesian coordinates.
Wave Interference and Modulation
The Wave Network innovates on traditional network architectures by implementing wave-based operations to update token representations. Unlike standard dot products used in models like Transformer, the Wave Network employs operations akin to wave interference and modulation.
Network Architecture
The network employs single-layer or multi-layer architectures, where initial embeddings of tokens are processed through a series of layers that apply wave operations. Each layer consists of linear transformations and normalization steps, replacing the attention-heavy architecture of traditional models with efficient wave-based operations.
Experimental Results
The experiments, conducted on datasets such as AG News and DBpedia14, showcased the model’s efficiency:
Discussion
The Wave Network achieves its efficiency through an innovative use of signal processing concepts, transforming NLP architecture design. By encoding text semantics in complex vector forms and updating through wave operations, the model minimizes resource demand without sacrificing performance. Its efficient architecture and reduced parameter count position it as a viable solution for deploying NLP in constrained environments.
Conclusion
The study posits the Wave Network as a sustainable and efficient alternative to large-scale NLP models, maintaining competitive accuracy while drastically reducing computational costs. The introduction of complex vector semantics and wave-based update mechanisms marks a promising direction for scalable and resource-efficient NLP applications. Future avenues may explore enhancements in semantic representation accuracy and broader multi-lingual performance metrics.