- The paper introduces LogLLM, a framework that uses LLMs to capture semantic nuances in system logs for improved anomaly detection.
- It employs a unique three-stage training process with techniques like minority class oversampling to balance normal and anomalous samples.
- The framework demonstrates superior performance with high precision, recall, and F1-scores across multiple public datasets.
LogLLM: Log-based Anomaly Detection Using LLMs
Introduction
The paper "LogLLM: Log-based Anomaly Detection Using LLMs" (2411.08561) introduces a novel framework for detecting anomalies in system logs by leveraging LLMs. Anomaly detection in software systems is critical for maintaining their reliability and performance, especially as these systems grow in complexity and scale. Traditional deep learning methods often fail to capture the semantic nuances embedded in log data due to its natural language structure. The proposed LogLLM framework addresses these shortcomings by integrating LLMs such as BERT and Llama to enhance the semantic understanding and classification capabilities for log-based anomaly detection.
Methodology
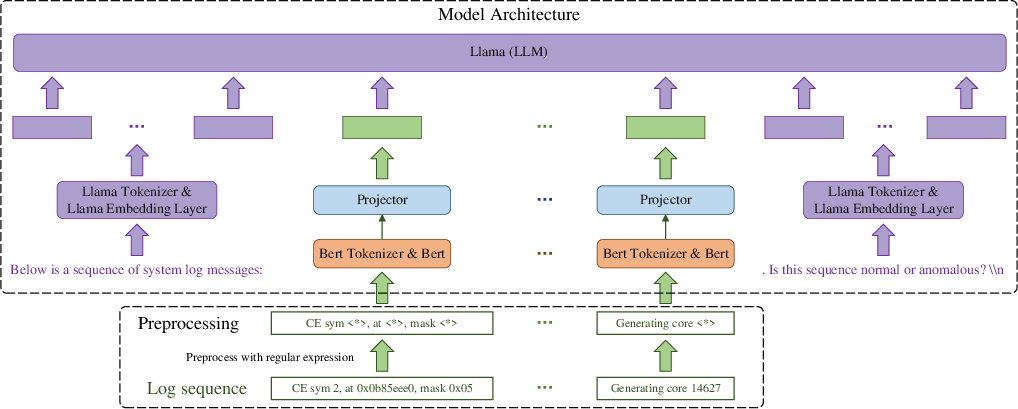
Preprocessing
The LogLLM framework adopts a unique approach by bypassing conventional log parsing techniques and utilizing regular expressions for preprocessing log messages. This preprocessing focuses on replacing dynamic parameters within log messages with constant tokens, thereby simplifying model training without losing semantic content. This method proves advantageous over log parsers, which can struggle with out-of-vocabulary issues in dynamic logging environments.
Model Architecture
LogLLM incorporates BERT and Llama within its architecture, using each for specific roles:
Training Procedure
LogLLM utilizes a three-stage training process:
- Stage 1: Llama is fine-tuned to recognize anomaly detection response templates.
- Stage 2: BERT and the projector are trained to encode log messages into vectors suitable for Llama's token embeddings.
- Stage 3: The entire model undergoes fine-tuning to ensure optimal performance and integrated operation of all components.
This staged approach ensures that each model component is effectively trained for its role, leading to a cohesive anomaly detector.
Minority Class Oversampling
To handle data imbalance, LogLLM implements minority class oversampling, ensuring a balanced representation of normal and anomalous samples during training. The paper suggests oversampling based on predefined thresholds to minimize biases in detection performance across various datasets.
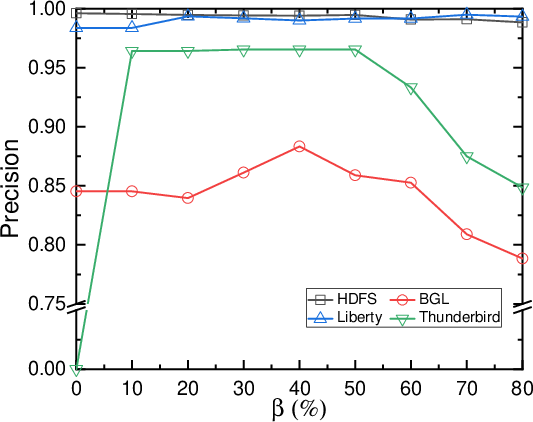
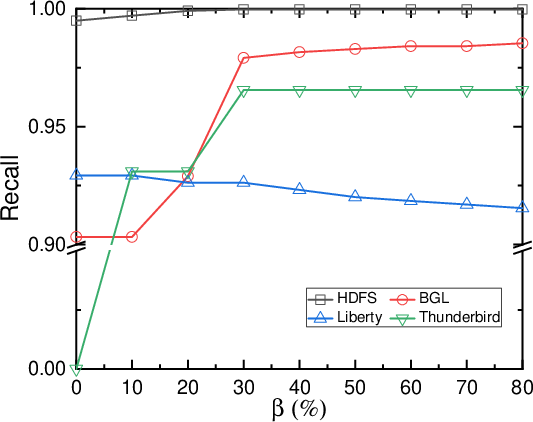
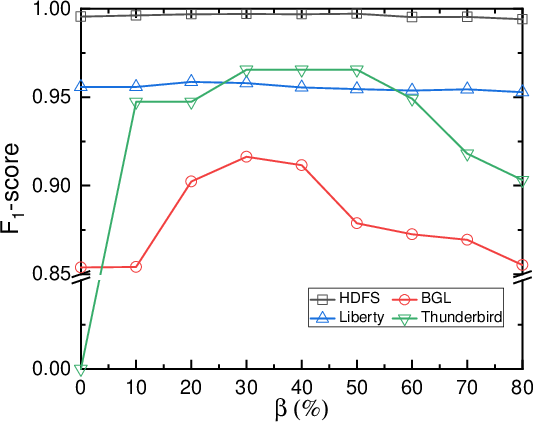
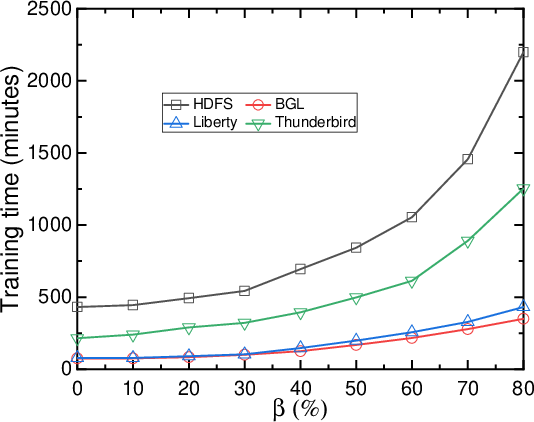
Figure 2: Impact of minority class oversampling.
Experimental Results
The framework was evaluated on four public datasets (HDFS, BGL, Liberty, and Thunderbird), demonstrating superior performance over state-of-the-art methods. LogLLM achieved high precision, recall, and F1-scores across varied datasets, indicating its robustness in different logging environments and conditions. Notably, LogLLM effectively maintains recall and precision balances, reducing false alarm rates and missed detections.
Discussion and Implications
The introduction of LogLLM marks a pivotal advancement in log-based anomaly detection. By leveraging LLMs, the framework transcends traditional limitations, capturing deep semantic insights embedded in logs. The implications are substantial, offering tools to enhance system reliability and operational efficiency.
Future research may explore further integration strategies for LLMs within anomaly detection frameworks, potentially extending the model's capabilities to real-time monitoring and adaptive learning in evolving software systems.
Conclusion
LogLLM presents a promising direction for anomaly detection, harnessing the power of LLMs to improve semantic comprehension and detection accuracy in log-based environments. Its innovative architecture and training methodology provide a blueprint for future exploration and development in AI-driven log analytics.