- The paper introduces CQN-AS, a novel RL approach that leverages action sequences to improve estimation of future rewards in robot learning tasks.
- It employs a critic-only architecture to mitigate value overestimation and outperforms standard RL and behavior cloning baselines in sparse-reward settings.
- Ablation studies reveal that tuning action sequence length and temporal ensemble strategies significantly enhances performance across diverse robotic benchmarks.
Coarse-to-Fine Q-Network with Action Sequence for Data-Efficient Robot Learning
Introduction
The paper introduces a novel approach to reinforcement learning (RL) that leverages action sequences to improve data efficiency in robotic learning tasks. The central proposal, named Coarse-to-Fine Q-Network with Action Sequence (CQN-AS), builds upon the Coarse-to-Fine Q-Network (CQN) framework by extending it to incorporate sequences of actions rather than single-step actions. This approach is motivated by insights from behavior cloning (BC) research, suggesting that predicting sequences of actions can significantly improve performance by better capturing future rewards when compared to single-action predictions.
Methodology
At the core of the CQN-AS is the concept of predicting action sequences, which facilitates the learning of complex robotic tasks by providing a more accurate estimation of future rewards. The method extends the CQN framework, which operates in a discretized action space, by allowing the critic network to output Q-values over sequences of actions. This is accomplished through a hierarchical discretization of the action space into sequences, thereby reducing the propensity for overestimation seen in single-action models.

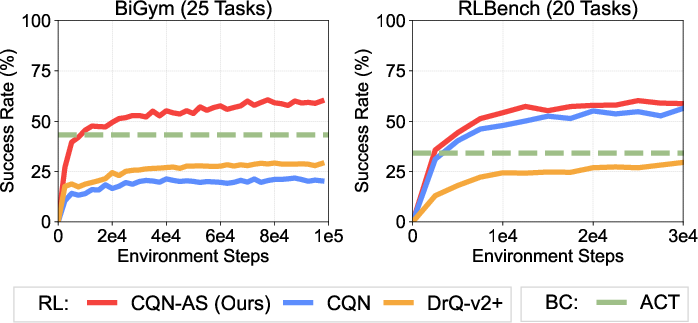
Figure 1: Summary of results. Coarse-to-fine Q-Network with Action Sequence (CQN-AS) learns a critic network with action sequence. CQN-AS outperforms various RL and BC baselines such as CQN, DrQ-v2+, and ACT on 45 robotic tasks.
To address the challenges posed by value overestimation in action sequences, the paper employs a simplified critic-only architecture, removing the actor network that traditionally introduces instability by exploiting value function errors. Instead, CQN-AS selects actions based on the highest predicted Q-values, maintaining stability across multiple robotics tasks.
Experimental Results
CQN-AS is evaluated on two primary benchmarks: BiGym and RLBench, which represent sparse-reward scenarios. The results demonstrate that CQN-AS consistently surpasses the performance of existing RL and behavior cloning algorithms, particularly excelling in environments where data efficiency and sparse rewards pose significant challenges.
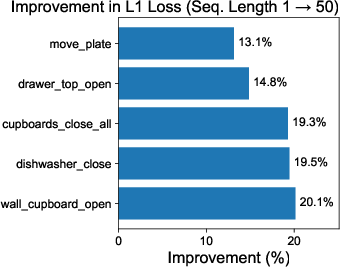
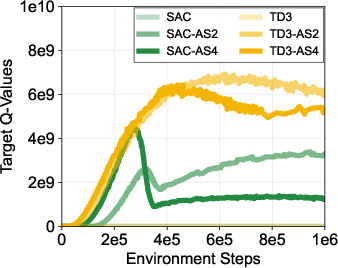
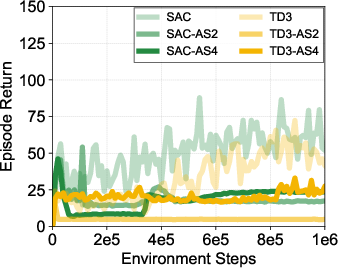
Figure 2: Analyses show improved validation L1 loss for return-to-go predictions with different action sequence lengths and demonstrate how action sequences lead to value overestimation when improperly handled.

Figure 3: Examples of robotic tasks. We study CQN-AS on 25 humanoid control tasks from BiGym and 20 tabletop manipulation tasks from RLBench.
The method's robustness is further affirmed by additional experiments conducted on the HumanoidBench suite, showing that CQN-AS retains its performance advantages even in densely-rewarded tasks when no demonstrations are available.
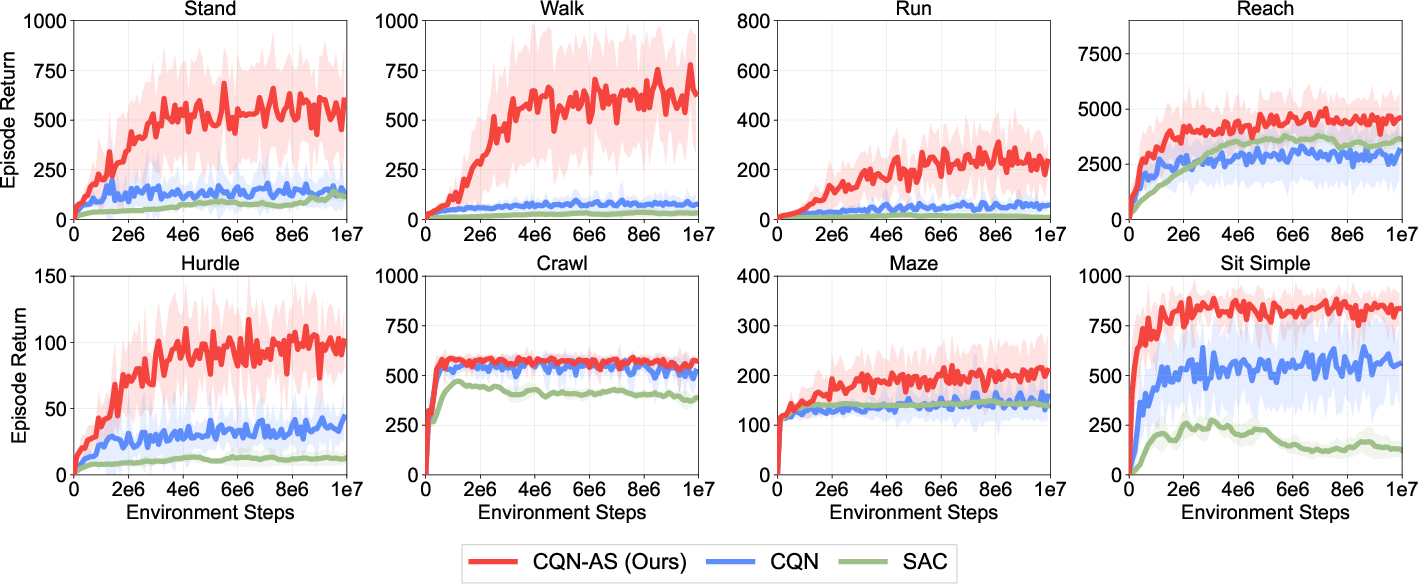
Figure 4: HumanoidBench results on eight densely-rewarded humanoid control tasks, highlighting improvements over SAC.
Ablation Studies
Extensive ablation studies explore the impact of various components of CQN-AS, including action sequence length, N-step returns, and the role of temporal ensemble strategies. Results suggest that longer action sequences and appropriate temporal averaging significantly enhance performance, although they must be carefully tuned to balance stability and learning progression.
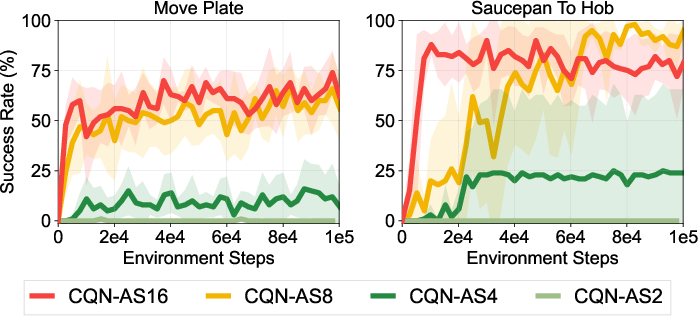
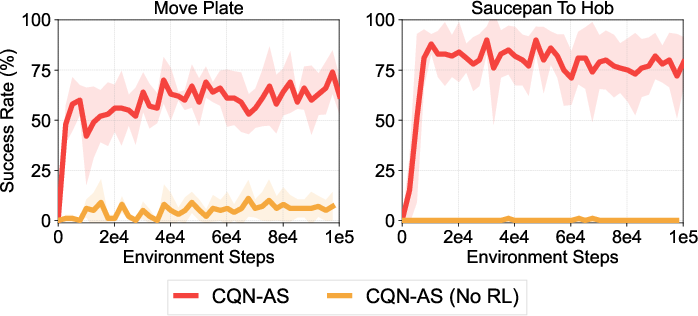
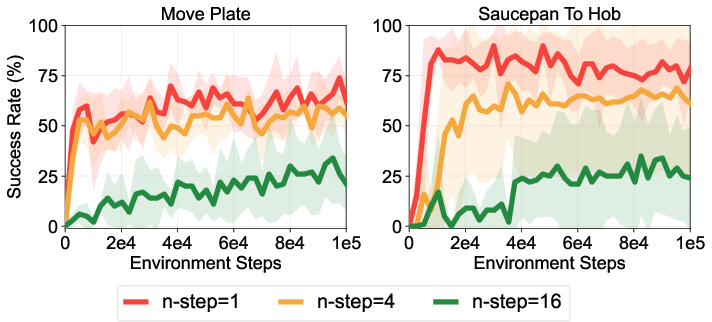
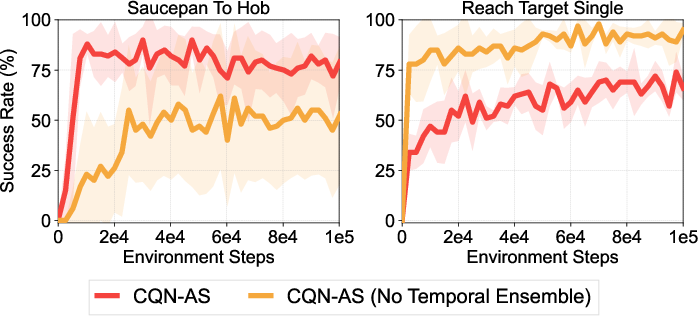
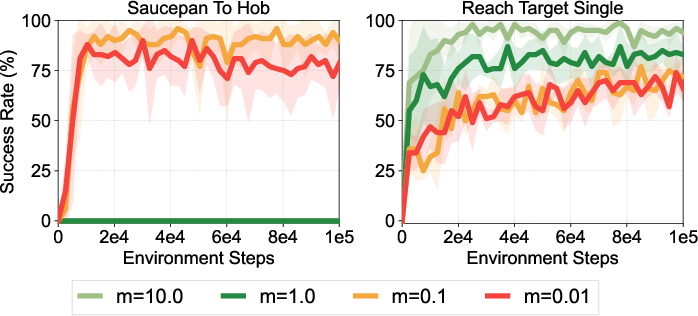
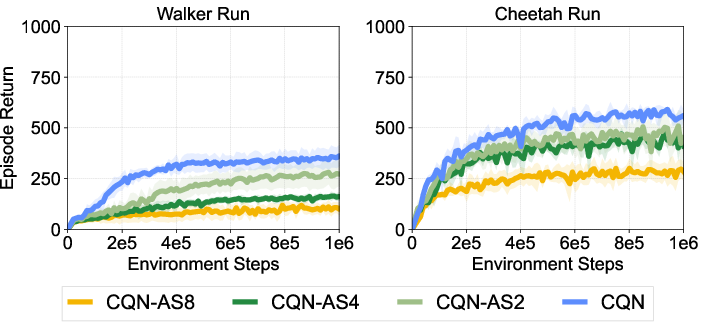
Figure 5: Ablation studies and analysis on the effect of action sequence, RL objective, N-step return, and temporal ensemble.
Conclusion
The development of the Coarse-to-Fine Q-Network with Action Sequence represents a significant advance in the design of RL algorithms for robotic applications. By focusing on critic-only architectures and leveraging action sequences, this method markedly improves data efficiency and robust performance across various tasks and reward settings. Future work may explore real-world applications, further addressing challenges in fine manipulation and dynamic control where advanced sensory inputs and more complex action hierarchies could benefit from the CQN-AS framework.