- The paper introduces UltraMem, an ultra-sparse memory network that significantly reduces inference latency compared to MoE.
- The methodology employs Tucker decomposition and Implicit Value Expansion to streamline memory access and computation.
- Experiments show that UltraMem outperforms dense and MoE models on benchmarks like MMLU and Trivia-QA with enhanced efficiency.
Ultra-Sparse Memory Network
The "Ultra-Sparse Memory Network" paper introduces UltraMem, a novel architecture designed to address the inefficiencies in parameter and computational complexity associated with Transformer models, particularly during inference. By incorporating ultra-sparse memory layers, UltraMem aims to achieve superior computational efficiency, drastically reducing inference latency while still maintaining competitive performance with large-scale LLMs such as MoE (Mixture of Experts).
Introduction and Background
Transformer models exhibit performance scaling exponentially with parameter count, which inevitably results in increased computational costs. This poses significant challenges in environments where computational resources are constrained. Previously, approaches like MoE attempted to mitigate these constraints by decoupling parameter count from computation; however, they introduced increased memory access costs that hindered inference. UltraMem goes further by optimizing memory layers to bypass these barriers.
UltraMem leverages large-scale, ultra-sparse memory layers by implementing structural innovations that efficiently distribute memory access and computation, demonstrating robust scaling capabilities while surpassing traditional models in terms of inference speed and computational efficiency.
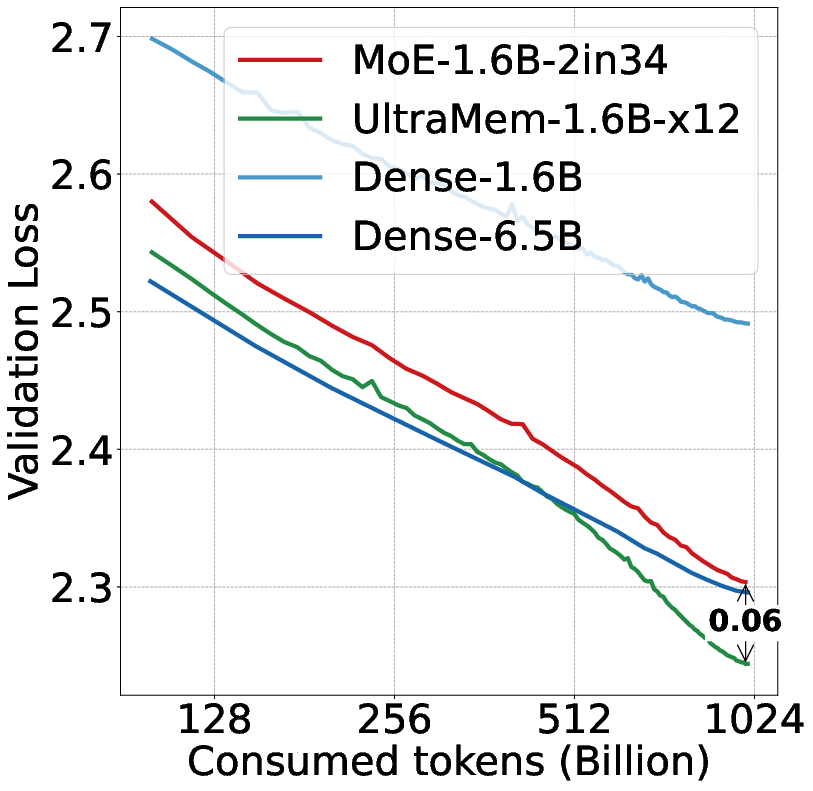
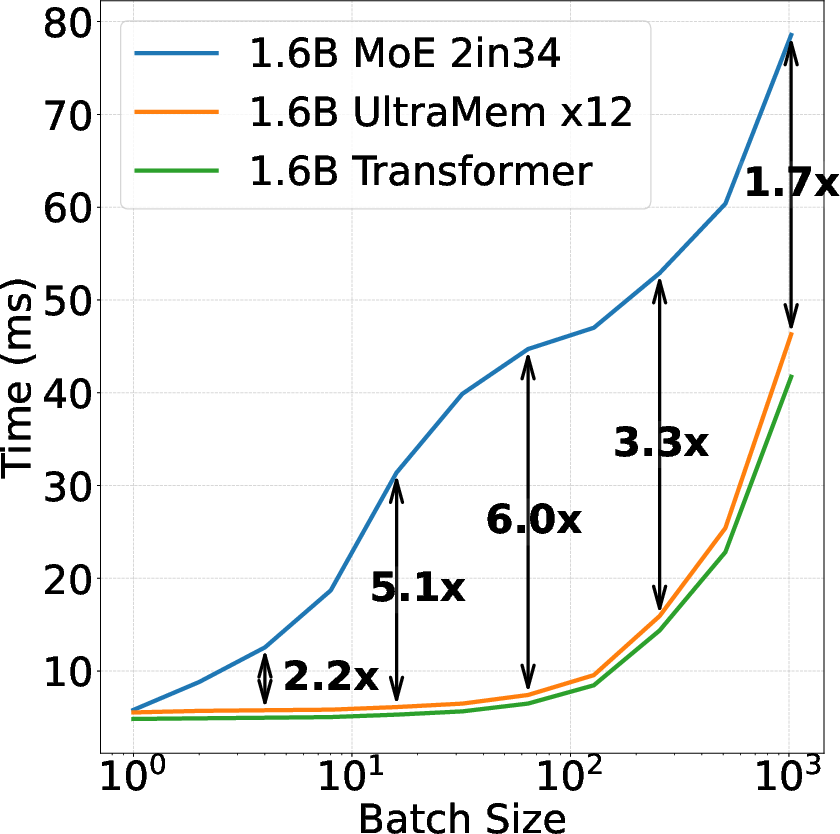
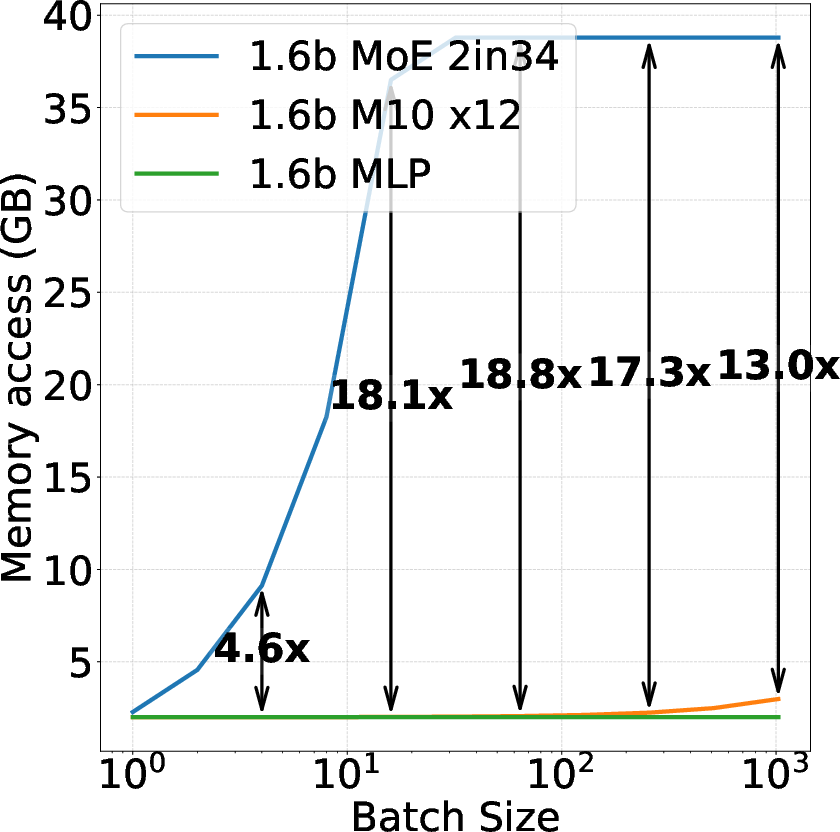
Figure 1: We ensured that three models have the same computation, and MoE and UltraMem have the same parameters.
Architecture and Structural Enhancements
UltraMem builds upon Product Key Memory (PKM) architecture, emphasizing the reduction of computational complexity by restructuring memory layers. The architecture utilizes Tucker decomposition for efficient query-key retrieval through multiplicative techniques, such as the Tucker Decomposed Query-Key Retrieval (TDQKR). This method reduces the retrieval topology bias traditionally imposed by product key decomposition, enhancing value selection diversity.
The introduction of Implicit Value Expansion (IVE) further scales memory size by virtual expansion, effectively expanding memory blocks while minimizing actual memory access. This technique is crucial for maintaining a balance between efficiency and memory access costs during inference. By reparameterizing memory values and employing weighted sum pooling on demand, IVE curbs unnecessary computations.
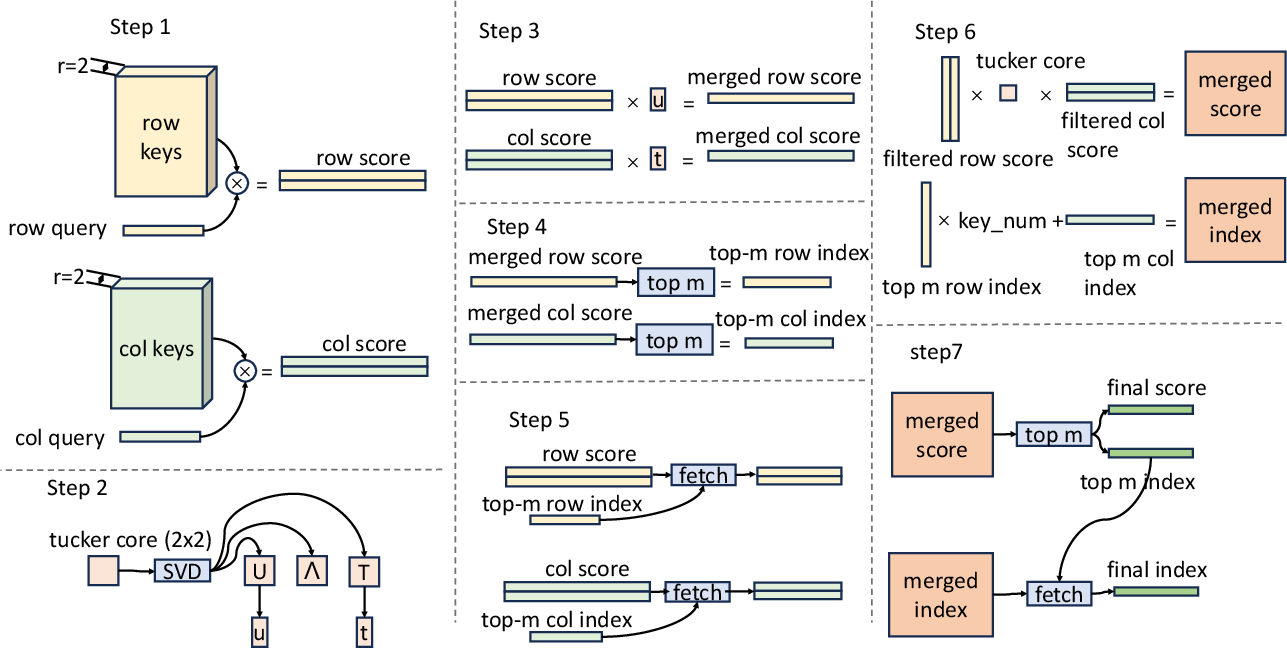
Figure 2: Flow of Tucker Decomposed Query-Key Retrieval, here r=2.
UltraMem also includes Multi-Core Scoring (MCS), which assigns multiple scores per single memory value, enhancing performance through empirically demonstrated benefits. Additionally, memory layer computations are distributed across all devices using Megatron's 3D parallelism strategy, optimizing training for models with billions of parameters.
Experimental Analysis
UltraMem's architectural innovations were rigorously evaluated against MoE and dense models across various benchmark tasks, including MMLU, Trivia-QA, GPQA, and ARC. The experiments confirm UltraMem's superior scaling capacity, achieving substantial improvements in inference speed, up to sixfold in certain contexts compared to MoE, with lower memory access requirements.
UltraMem's advantages are particularly pronounced when increasing model size, outperforming MoE with the same computational and parameter resources. The model's efficacy is verified by strong results across knowledge, reasoning, reading comprehension, and general ability benchmarks, demonstrating promise in deploying resource-efficient LLMs.
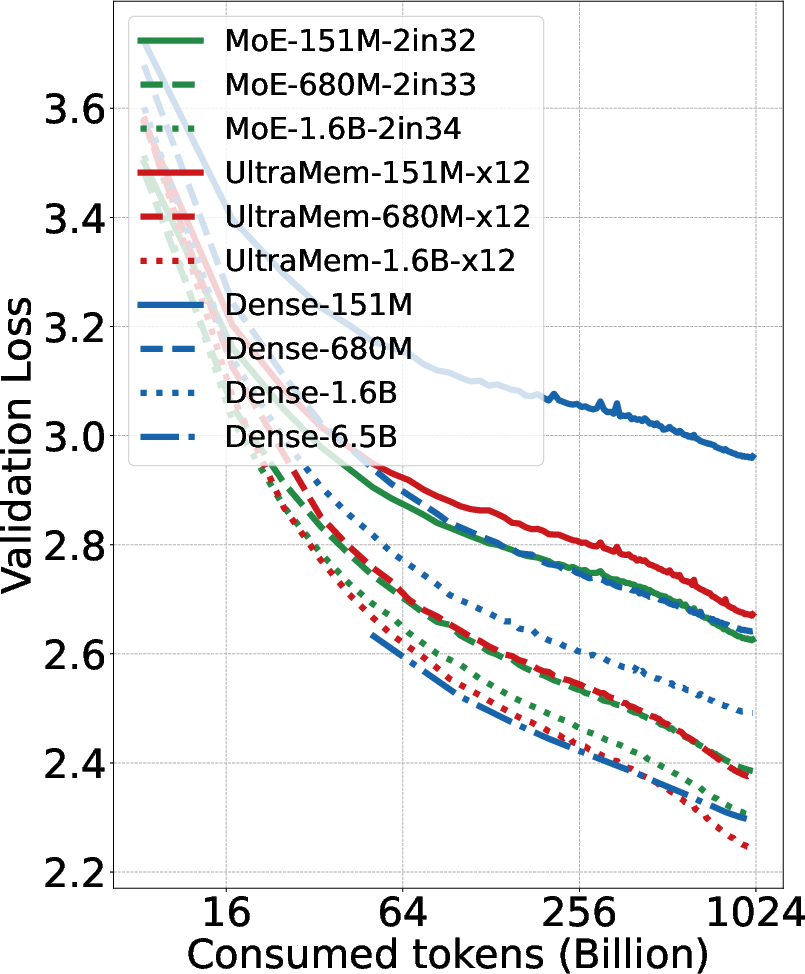
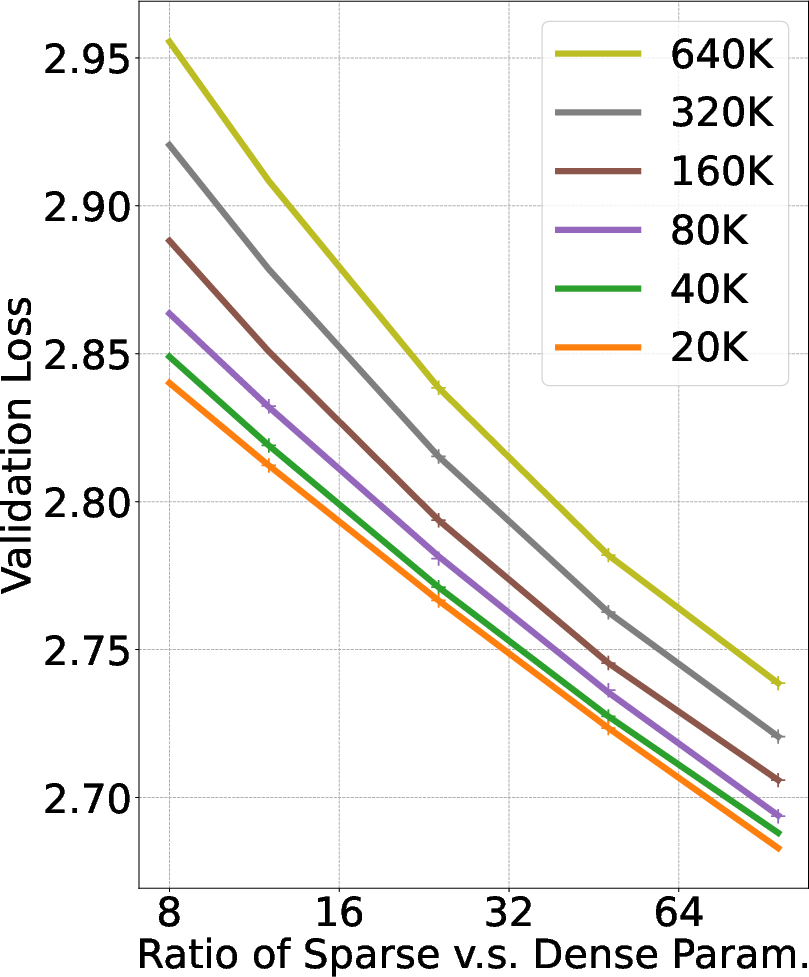
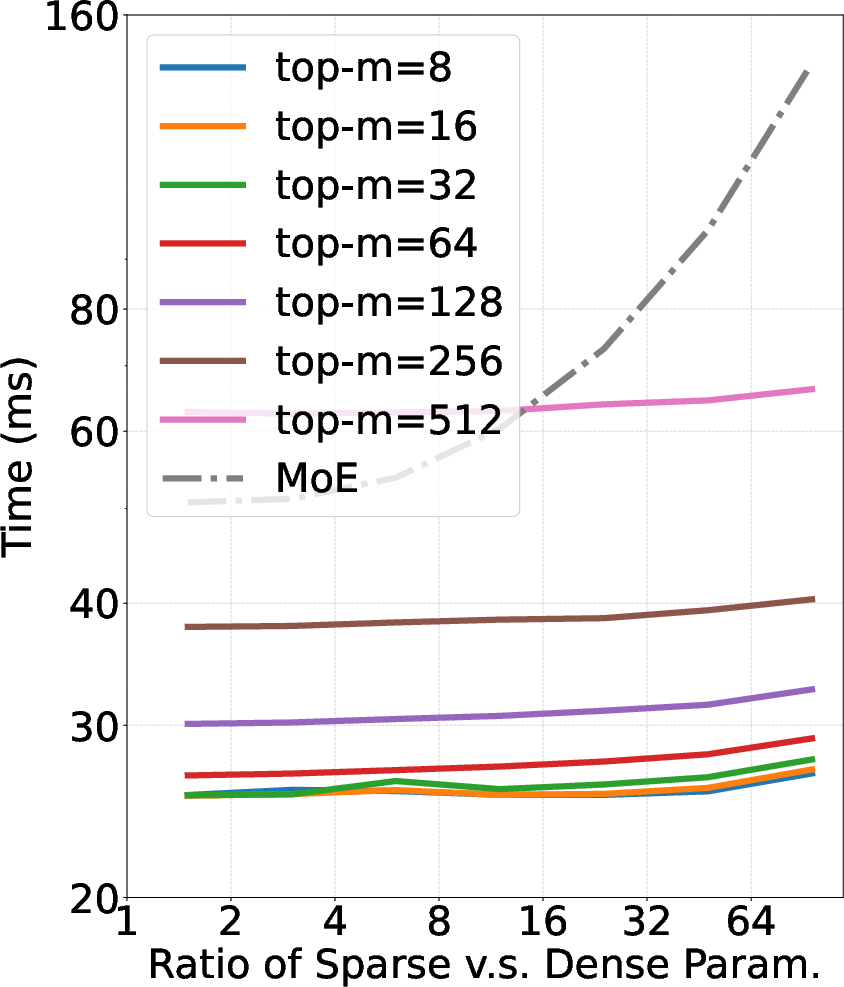
Figure 3: (a) C4 validation loss of different models at different scale.
Technical Trade-offs and Implications
The integration of sparse memory layers introduces trade-offs between memory access and computational efficiency. While UltraMem significantly improves inference speed, this comes with careful structural adjustments that maintain a balance between sparsity and parameter diversity. The architectural innovations present in UltraMem suggest a scalable path forward for developing high-performance, resource-efficient LLMs.
Conclusion
UltraMem represents a notable advance toward efficient and scalable LLMs, addressing constraints posed by previous architectures like MoE. By leveraging ultra-sparse memory layers, UltraMem not only reduces inference latency but also sets a new benchmark for scaling law efficiency in transformer models. This work not only facilitates deployment in resource-constrained environments but also paves the way for future models to achieve higher computational efficiency without sacrificing performance.