FGP: Feature-Gradient-Prune for Efficient Convolutional Layer Pruning
Abstract: To reduce computational overhead while maintaining model performance, model pruning techniques have been proposed. Among these, structured pruning, which removes entire convolutional channels or layers, significantly enhances computational efficiency and is compatible with hardware acceleration. However, existing pruning methods that rely solely on image features or gradients often result in the retention of redundant channels, negatively impacting inference efficiency. To address this issue, this paper introduces a novel pruning method called Feature-Gradient Pruning (FGP). This approach integrates both feature-based and gradient-based information to more effectively evaluate the importance of channels across various target classes, enabling a more accurate identification of channels that are critical to model performance. Experimental results demonstrate that the proposed method improves both model compactness and practicality while maintaining stable performance. Experiments conducted across multiple tasks and datasets show that FGP significantly reduces computational costs and minimizes accuracy loss compared to existing methods, highlighting its effectiveness in optimizing pruning outcomes. The source code is available at: https://github.com/FGP-code/FGP.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “FGP: Feature-Gradient-Prune for Efficient Convolutional Layer Pruning”
Overview: What is this paper about?
This paper introduces a new way to shrink and speed up deep learning models used for images (called Convolutional Neural Networks, or CNNs) without hurting their accuracy too much. The method is called FGP (Feature-Gradient Pruning). It removes unnecessary “channels” inside the model by looking at two kinds of clues at the same time:
- Features: what each channel sees in the image
- Gradients: how much each channel helps the model make correct predictions
By combining both, FGP keeps the most useful parts of the model and throws away the rest, making it faster and more efficient.
Key Objectives: What questions are the researchers asking?
They aim to:
- Figure out which channels in a CNN are truly important for recognizing all classes (not just one or two).
- Avoid the weaknesses of using only features or only gradients.
- Create a smarter way to choose how many channels to keep (Top k), based on how strongly channels support different classes.
Methods: How does FGP work (in simple terms)?
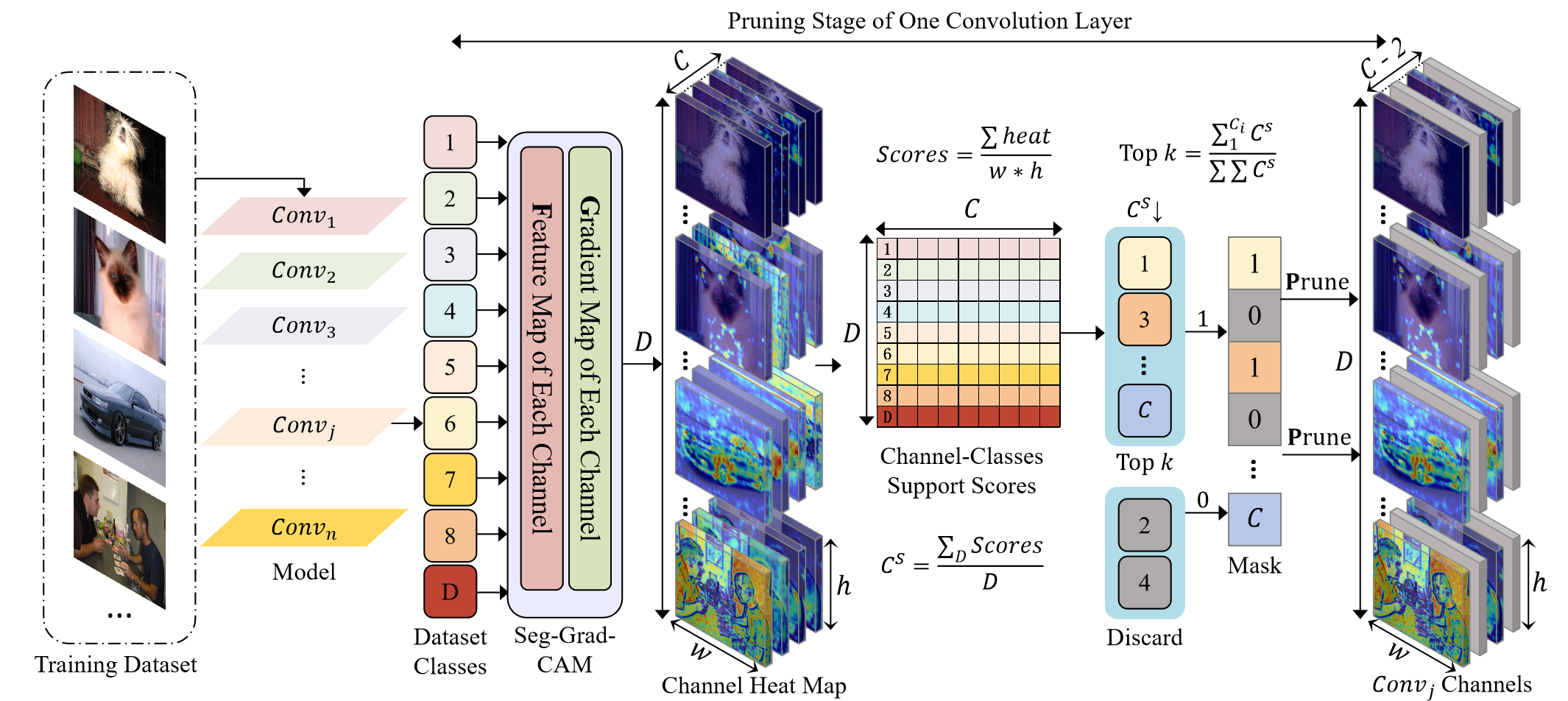
Think of a CNN as a factory with many teams (channels). Each team looks at an image and focuses on different patterns (like edges, textures, or shapes). Some teams are very helpful for many kinds of images; others only help for a few.
FGP uses “heatmaps” to see how much each team (channel) helps for each class. A heatmap is like a colored map that highlights the “hot” (important) spots of an image that matter for the model’s decision.
Here’s the process, explained like building a ranked list of the best teams:
- The authors use known tools (Grad-CAM, Grad-CAM++, Score-CAM) that create heatmaps in different ways:
- Gradient-based (Grad-CAM): looks at how much changing a channel affects the output. Think of it like asking: “If this team changed its work, would the final result change a lot?”
- Feature-based (Score-CAM): looks at how strong a channel’s activation is. Think of it like: “How much is this team currently doing?”
- For each class (like “cat”, “car”, or “tree”), they make a heatmap for every channel and sum up how “hot” it is. This gives a score: how important is this channel for that class?
- They then add those scores across all classes to find channels that help many classes, not just one.
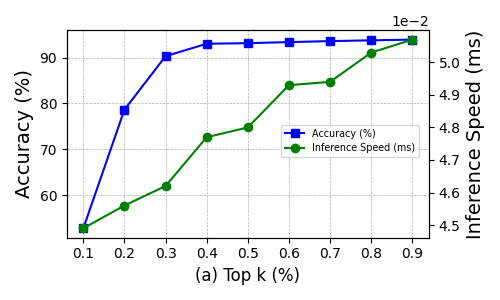
- Finally, they sort channels by importance and keep only the Top k% (for example, the top 35% or 40%). This “k” is chosen based on experiments to balance speed and accuracy.
- They rebuild the model using only the kept channels, copy over the relevant weights, and do a short fine-tuning (extra training) to recover any small loss in accuracy.
Main Findings: What did they discover and why does it matter?
To help you see the big picture, here are the most important results from their tests:
- Across multiple datasets (CIFAR-10, CIFAR-100 for classification; CamVid and Cityscapes for segmentation), FGP cuts a large chunk of computation (often 30–56%) while keeping accuracy close to the original model.
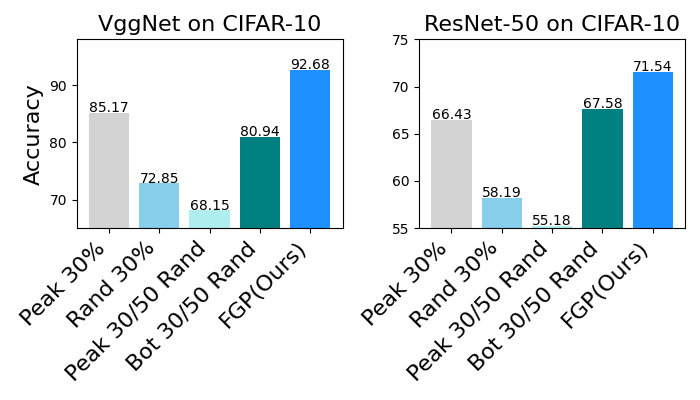
- On VGG-16 (CIFAR-10), FGP keeps accuracy around 93–94% while reducing the model size and compute noticeably.
- On ResNet-50 (CIFAR-10/100), FGP reduces computation by about half, with small drops in accuracy that are competitive or better than other pruning methods.
- For segmentation (CamVid, Cityscapes), FGP reduces compute by around 30–40%, and the segmentation quality (mIoU) stays close to the baseline, sometimes matching or outperforming other methods.
- FGP performs better than methods that use only features or only gradients, because it blends both signals to make smarter choices.
- The best balance between speed and accuracy is often when keeping about 35–40% of channels (Top k = 0.35–0.4).
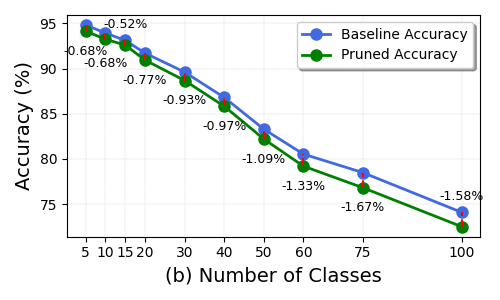
- When there are many classes (like 100), the accuracy gap to the original model grows a bit. This makes sense because it’s harder to keep enough channels that help all classes.
These results matter because they show FGP makes models more practical—especially for phones, robots, and cars, where speed and energy use matter.
Implications: Why is this important in the real world?
- Faster and smaller models: FGP helps run AI on devices with limited memory and power, like smartphones or edge devices, without losing much accuracy.
- Hardware-friendly: Because FGP removes whole channels (structured pruning), the pruned model runs efficiently on common hardware.
- Broad use: It works for different tasks (classification and segmentation) and different model types (VGG, ResNet).
- Smarter pruning: By keeping channels that help all classes, FGP avoids wasting compute on channels that only help a few cases.
In short, FGP is a practical step toward making AI models lighter, faster, and more widely usable—especially where speed and energy efficiency are essential.
Collections
Sign up for free to add this paper to one or more collections.