- The paper introduces a novel WF-VAE model that employs wavelet-driven energy flow to optimize latent video encoding efficiency.
- It incorporates a Causal Cache mechanism to ensure continuous sliding window during block-wise inference, minimizing reconstruction artifacts.
- Experimental results demonstrate doubled throughput and reduced memory usage with higher PSNR and LPIPS compared to state-of-the-art methods.
WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model
Video Variational Autoencoders (VAEs) have become integral to Latent Video Diffusion Models (LVDMs) due to their ability to compress videos into low-dimensional latent spaces, thereby optimizing generative model training costs. However, the increase in video resolution and duration has rendered traditional video VAEs a bottleneck in terms of encoding efficiency. This paper introduces a novel model, Wavelet Flow VAE (WF-VAE), leveraging wavelet decomposition to enhance encoding efficiency by focusing on wavelet-driven energy flows.
Wavelet-Driven Architecture
WF-VAE's architecture is rooted in the multi-level wavelet transform, decomposing video data into different frequency components. By prioritizing low-frequency components, essential for video quality, the model facilitates an efficient energy flow into the latent representation while bypassing extraneous high-frequency details.
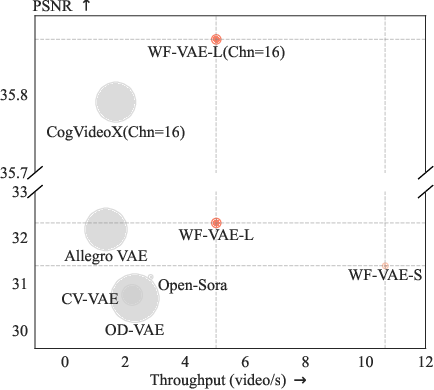
Figure 1: Performance comparison of video VAEs. Bubble area indicates the memory usage during inference. All measurements are conducted on 33 frames with 256×256 resolution videos. “Chn” represents the number of latent channels. Higher PSNR and throughput indicate better performance.
The design integrates a simplified backbone with reduced 3D convolutions, thereby decreasing computational overhead. It effectively directs the flow of video information, ensuring low-frequency components—from which most perceptual energy is derived—are adequately encoded without overloading the network.
Causal Cache for Block-Wise Inference
Block-wise inference practices in LVDMs have historically introduced discontinuities, hindering video reconstruction integrity. WF-VAE introduces the Causal Cache, a strategy leveraging causal convolutions to maintain convolution continuity across blocks.
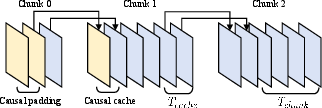

Figure 2: Illustration of Casual Cache.
Causal Cache reduces artifacts that typically arise from block-wise strategies by maintaining a consistent sliding window for convolutions across temporal blocks. This ensures that the numerical results from block-wise inference align with those from direct inference without interruptions.
Experimental Evaluation
WF-VAE was rigorously tested against leading video VAEs, demonstrating superior performance on key metrics including PSNR and LPIPS while achieving a throughput that is twice as high with only a quarter of the memory consumption of state-of-the-art methods.

Figure 3: Generated videos using WF-VAE with Latte-L. Top: results trained with the SkyTimelapse dataset. Bottom: results trained with the UCF-101 dataset.
The experiments reveal that WF-VAE delivers exceptional efficiency and quality in video reconstruction and generation tasks, making it suitable for large-scale deployments.
Implications and Future Directions
The introduction of WF-VAE presents a significant step towards reducing computational requirements in video generation tasks. By efficiently managing and encoding video energy, the model paves the way for more scalable approaches to video synthesis without compromising on quality or performance.

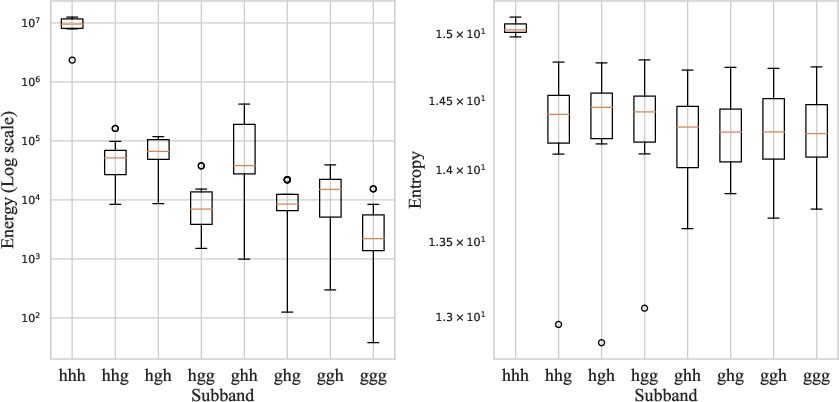
Figure 4: Visualization of the eight subbands obtained after wavelet transform of the video.
Future research could focus on further optimizing the wavelet energy pathway and exploring the integration of WF-VAE with other video generation frameworks, as well as applying the Causal Cache strategy to analogous tasks in other domains.
Conclusion
WF-VAE stands out by successfully addressing the dual challenges of computational efficiency and latent space continuity in video VAE encoding processes. Through strategic energy management and innovative inference mechanisms, it provides a robust framework for future developments and applications in video-based AI systems.