- The paper provides a taxonomy and detailed analysis of LLM-brained GUI agents, highlighting their architecture, methodologies, and evaluation techniques.
- It demonstrates how LLMs integrate natural language, visual perception, and planning to enable adaptive, cross-platform GUI automation.
- The survey outlines open challenges such as scalability, privacy, and latency, guiding future research in intelligent, end-to-end automation systems.
LLM-Brained GUI Agents: Architecture, Methods, and Future Directions
Introduction and Motivation
LLMs with multimodal capabilities have fundamentally transformed the landscape of GUI automation, advancing beyond static, script-based approaches to intelligent, context-aware agents capable of interacting with diverse graphical user interfaces (GUIs). The surveyed work, "LLM-Brained GUI Agents: A Survey" (2411.18279), provides a comprehensive synthesis of the progression, design principles, foundational techniques, frameworks, data ecosystems, optimized models, benchmarking methodologies, and open research challenges for LLM-powered GUI agents.
The principal proposition is that LLM-brained GUI agents leverage foundation models as a cognitive and decision-making core, integrating natural language interpretation, visual recognition of GUIs, dynamic tool-use, planning, and memory into an end-to-end system for automating complex tasks across web, mobile, and desktop platforms. This survey details the evolution from deterministic, rule-based software toward context-adaptive agents capable of orchestrating actions across heterogeneous applications in response to natural language commands.
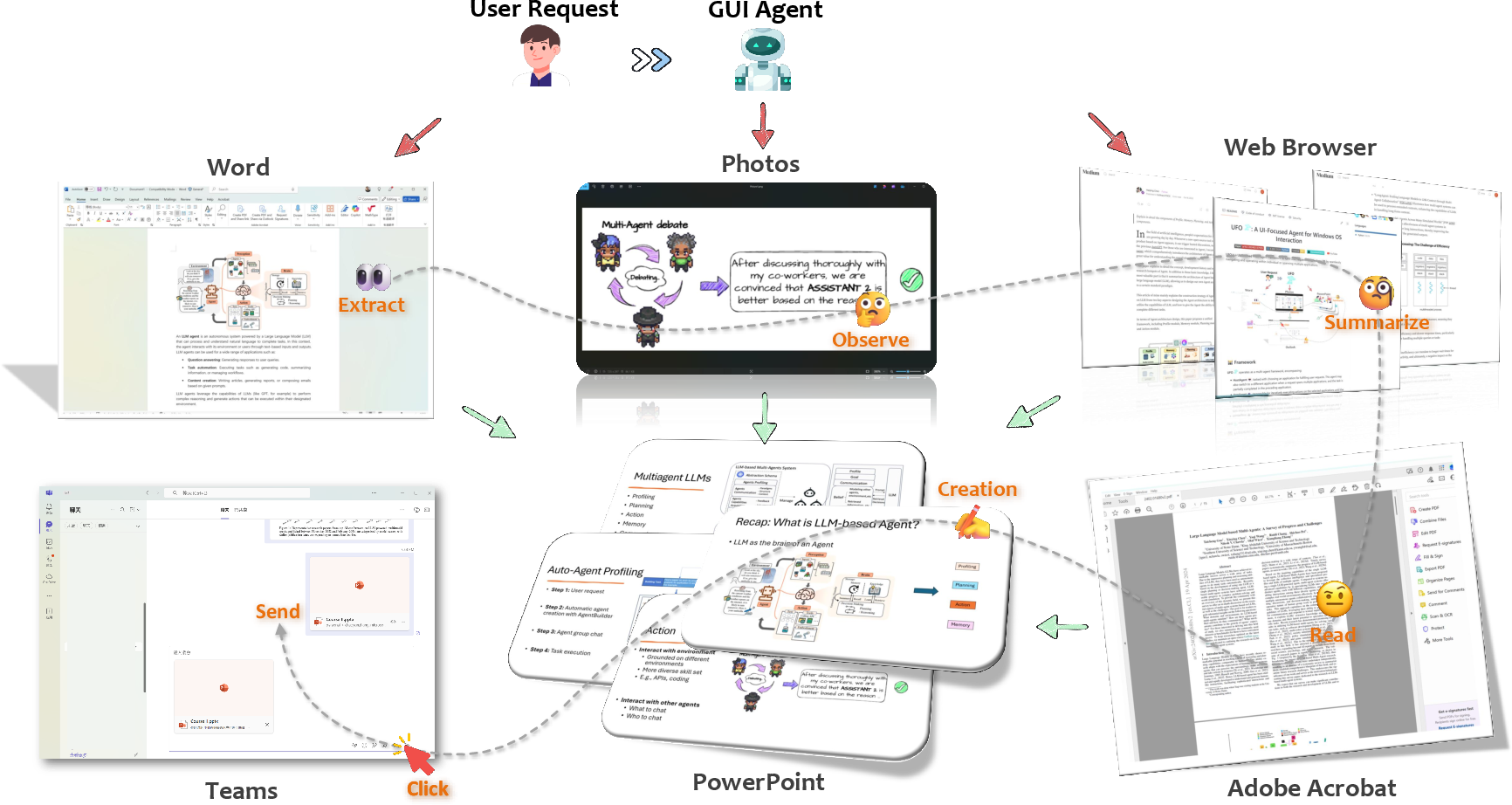
Figure 1: Illustration of the high-level concept of an LLM-powered GUI agent, showing cross-application orchestration from a user’s request.
Historical Evolution and Paradigmatic Shift
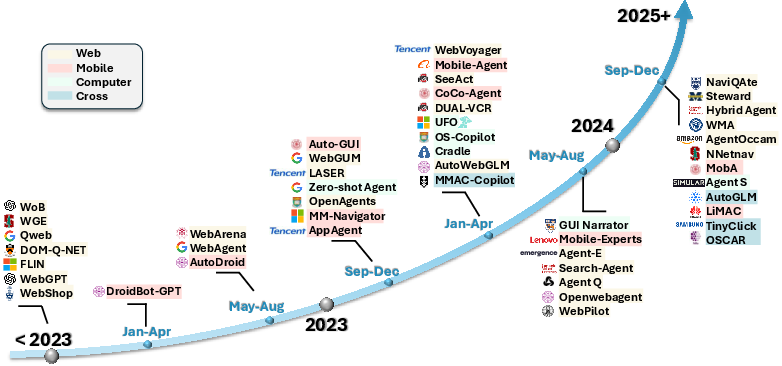
Early GUI automation relied heavily on random, rule-, or script-based methods, tailored primarily for regression testing, RPA, or linear workflows. These systems were constrained by platform-specific implementations, limited ability to generalize, and fragility in dynamic environments.
The integration of traditional ML, CV, and RL into GUI automation provided adaptive capabilities but remained limited to narrowly-defined problem spaces. With the advent of large language and multimodal vision-LLMs, a categorical shift occurred:
This shift positions GUI agents as mediated by universal language interfaces, no longer reliant on explicit exposure to every possible API or internal method, but instead exploiting the broad generalization, few-shot, and reasoning capacities of modern LLMs.
Architectural Foundations of LLM-Brained GUI Agents
LLM GUI agents are modularized into several fundamental stages Figure 4:
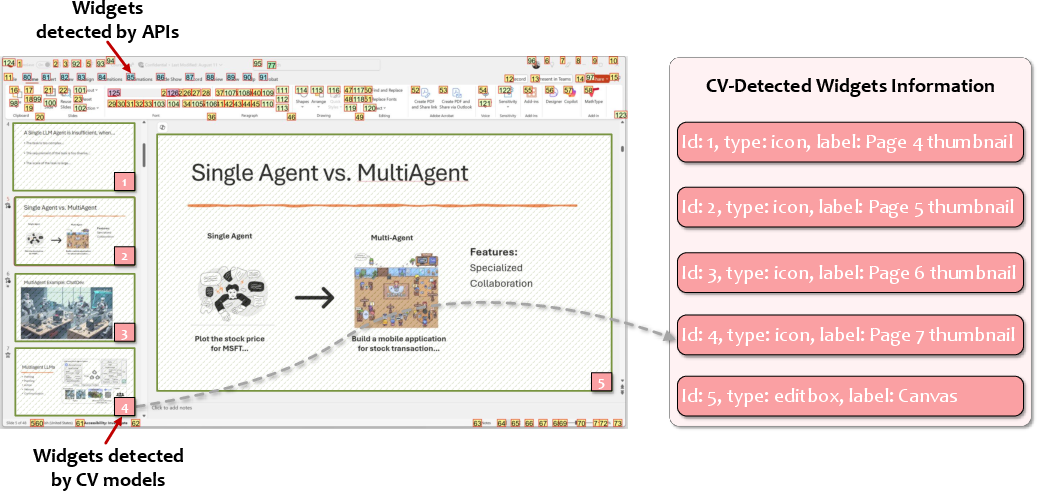
- Environment Perception: Agents continuously ingest screenshots, structural widget trees, and UI properties to maintain an accurate state representation. For GUIs with restricted access to internal structures, CV models are deployed to construct pseudo-trees via object detection, segmentation, and OCR.
- Prompt Construction: Prompts are built by fusing user instructions, the perceived environment state, available actions/tool documentation, past interactions (short-term memory), and possibly in-context demonstrations or retrieved external knowledge (long-term memory).
- LLM Inference: The LLM (foundation or domain-optimized) produces both high-level plans (via chain-of-thought, decomposition, or search) and explicit action sequences (e.g. function calls, parametrized UI events). Augmented outputs may include rationale, tool-selection, error correction, and self-reflection stubs.
- Action Execution: Derived actions encompass a spectrum—standard UI events (mouse/touch/keyboard), high-level API calls, and, when available, AI-driven tool invocation for tasks such as summarization or image generation.
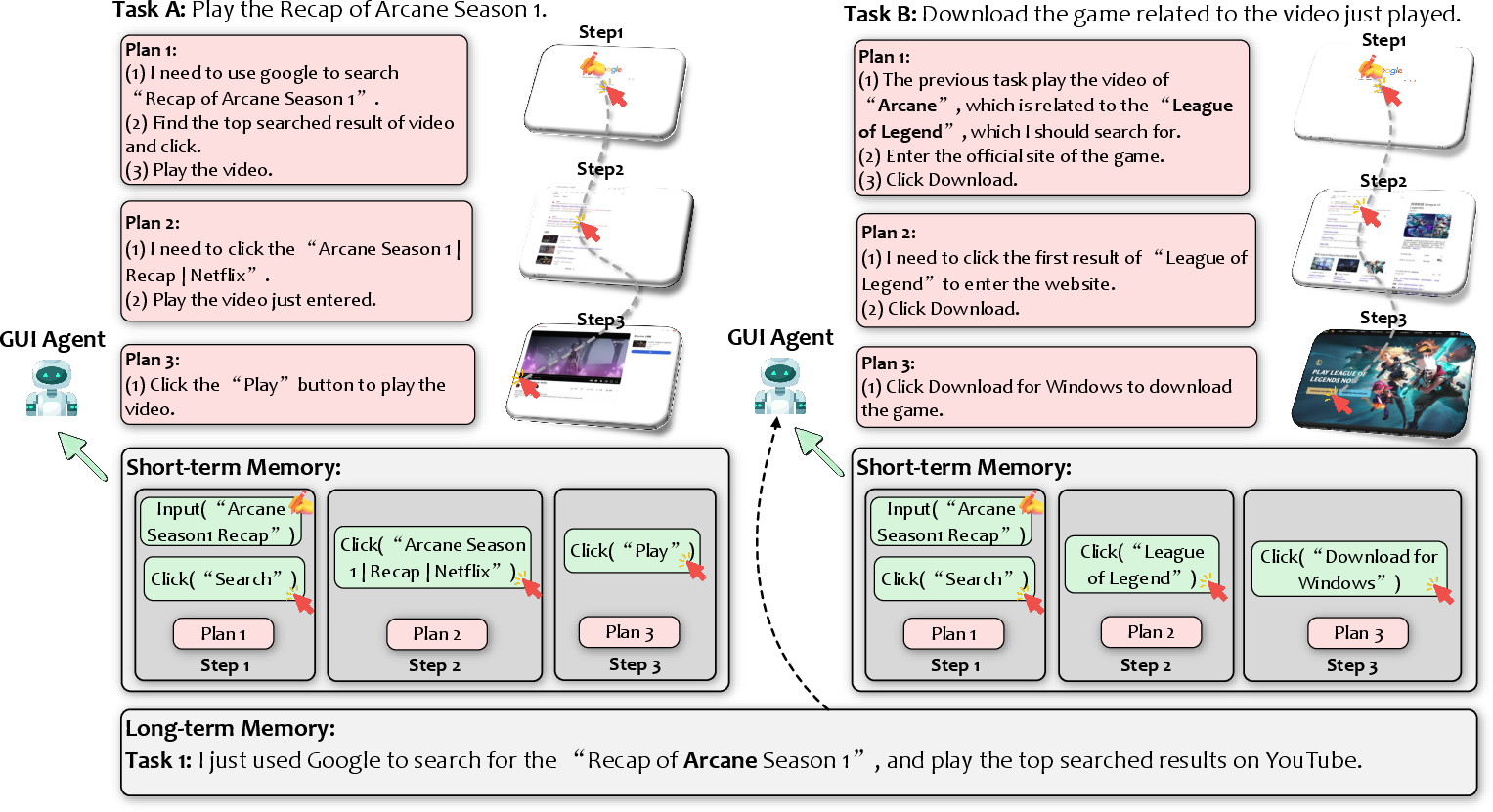
- Feedback Integration and Memory: Agents parse execution outcomes via GUI deltas (post-action screenshots/trees, function return values, GUI feedback). Both short-term (within-task) and long-term (cross-task, for experience replay and retrieval) memories are leveraged for consistency and improvement.
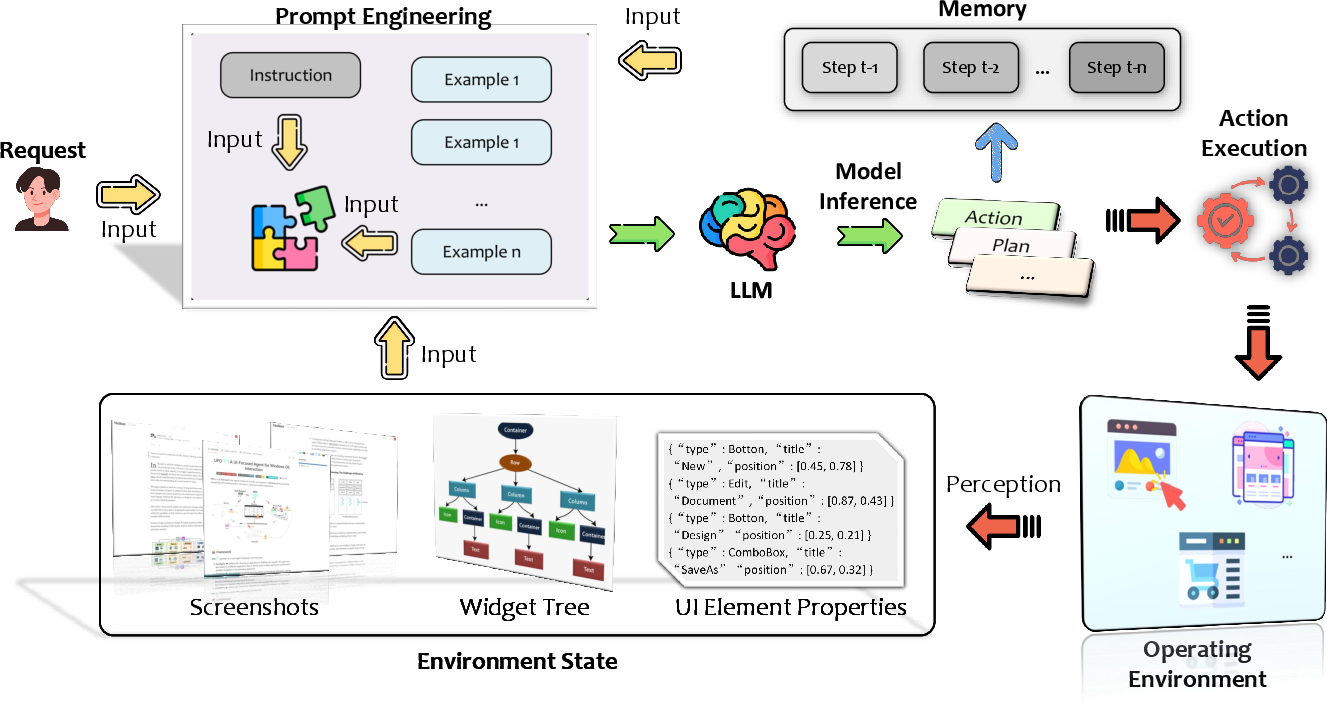
Figure 2: Generic architecture and staged workflow of an LLM-powered GUI agent, illustrating the dataflow from perception to closed-loop action and memory.
Key Technical Enhancements
Several design patterns integrate advanced capabilities into this general framework:
Memory Mechanisms
Advanced Planning and Self-evolution
Multi-Agent Collaboration
Perception via Pure Vision
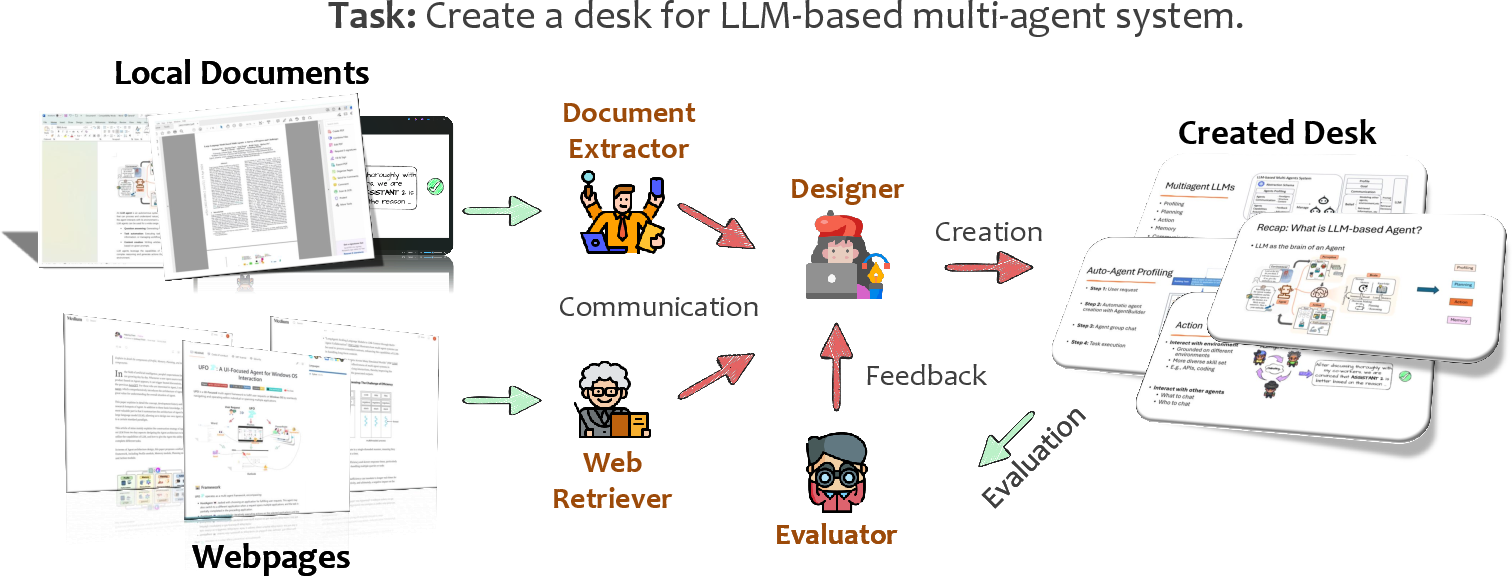
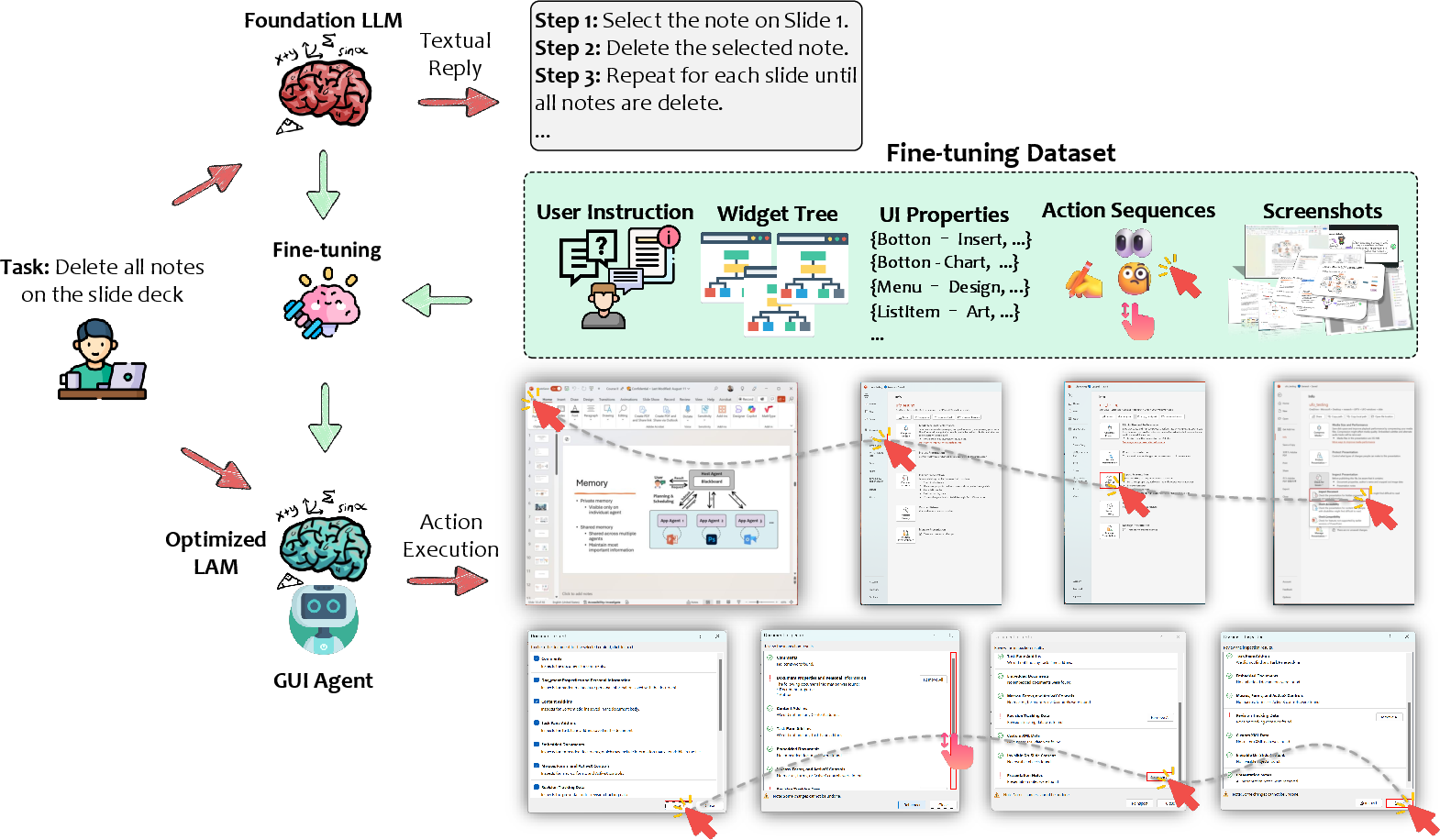
Data Pipelines and Datasets
High-performance GUI agents require curated datasets containing:
- Rich, environment-grounded user instructions.
- Paired (possibly multi-modal, multi-step) observations and action trajectories.
- Platform diversity: Mobile (AITW, Rico), Web (Mind2Web, WebLINX), Desktop (ScreenAI, GUI-World), and cross-platform (VisualAgentBench, xLAM).
The construction of large-scale, realistic, multi-environment datasets remains an engineering and methodological bottleneck due to both the annotation burden and the diversity of application behaviors.
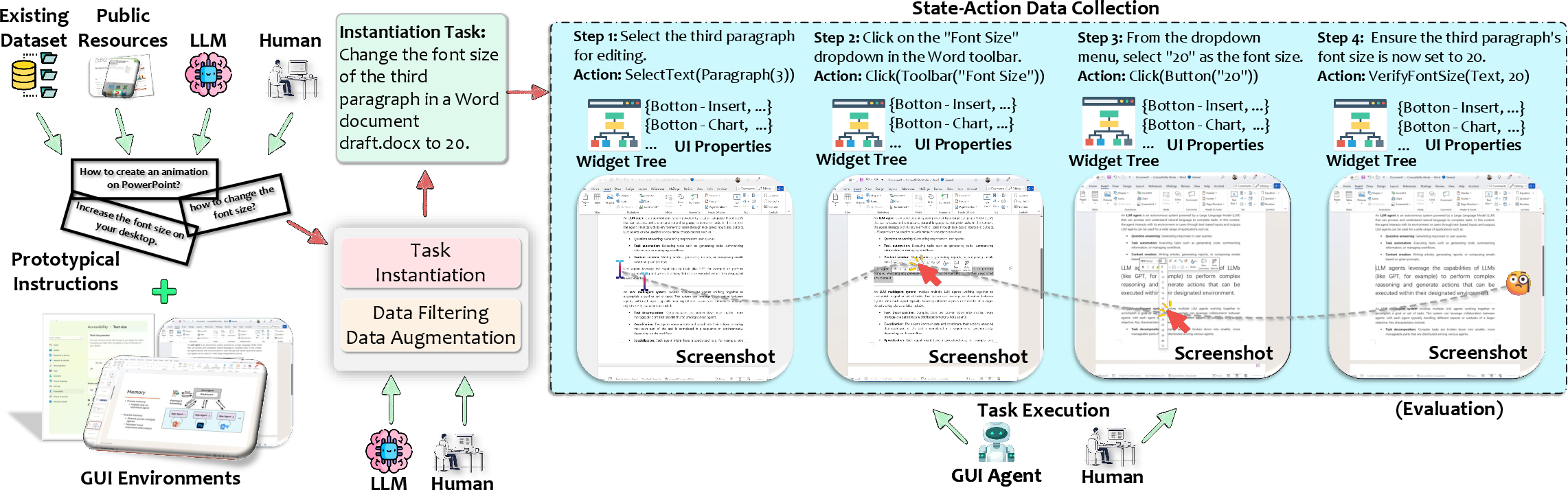
Figure 13: End-to-end data pipeline for dataset construction, including instantiation, augmentation, and validation steps.
Models: From Foundation LLMs to Large Action Models (LAMs)
While closed-source foundation models (e.g., GPT-4V/o, Claude, Gemini) dominate current best-of-breed performance for many GUI agent tasks, a robust movement toward open-source, specialized LAMs is emerging. These are multimodal LLMs fine-tuned on structured action datasets for explicit GUI control and visual grounding.
Notable highlights:
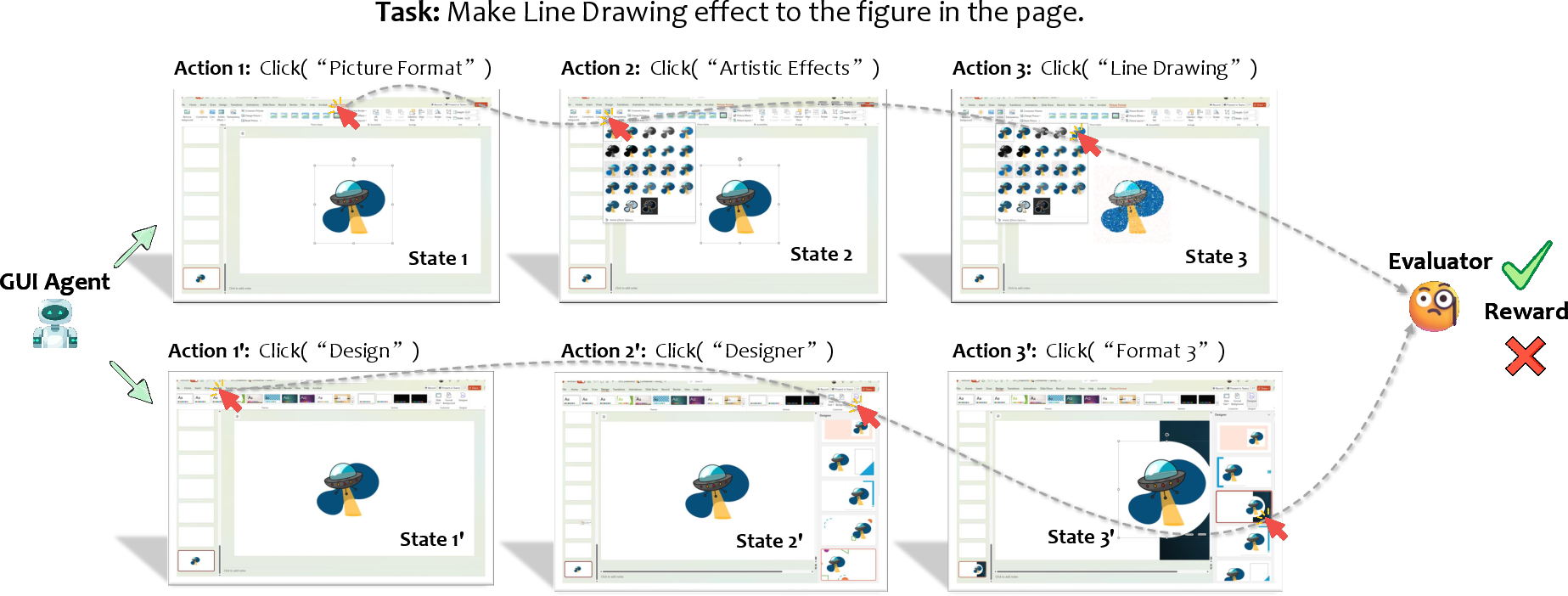
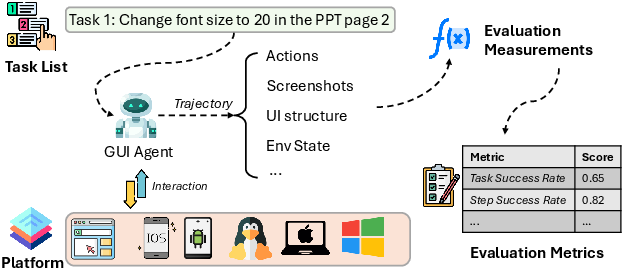
Evaluation and Benchmarks
Benchmarking GUI agents extends beyond script-based correctness to comprehensive measurement of action accuracy, planning efficiency, policy compliance, and dynamic robustness. Key axes:
Representative Applications and Use Cases
Two dominant verticals appear:
- GUI Testing: Black-box and intent-driven test generation, coverage maximization, input creation, and automated bug replay (GPTDroid, AUITestAgent, VisionDroid).
- Virtual Assistants: End-user automation and productivity support via natural conversation, cross-app orchestration, and accessibility enhancement (Power Automate, ProAgent, EasyAsk, VizAbility, YOYO Agent).
(Figure 1) and (Figure 17)
Figure 18: GUI testing and productivity use case scenarios enabled by LLM-powered agents.
Limitations, Open Challenges, and Outlook
Despite substantial progress, several issues remain open:
- Scalability: Agent designs that generalize across unseen UIs and platforms remain an unsolved challenge due to the combinatorial diversity of software environments.
- Privacy and On-Device Inference: Reliance on cloud APIs incurs privacy risk; advances in model quantization and efficient inference are critical.
- Latency and Resource Constraints: Achieving low-latency, high-throughput multi-step orchestration, particularly in resource-limited endpoints, is a major engineering bottleneck.
- Safety, Reliability, and Control: Action hallucination, adversarial GUI environments, permission management, and human-in-the-loop oversight must be systematically addressed.
- Human-Agent Interaction: Handling ambiguous instructions, intent clarification, and complex human-agent workflows is a nascent challenge for robust, explainable interaction.
- Customization and Personalization: User-specific adaptation and long-term behavior alignment require research into efficient, privacy-preserving preference modeling.
Conclusion
LLM-brained GUI agents represent an inflection point in intelligent application automation, enabling end-users, developers, and organizations to delegate complex, multi-application workflows via language-driven natural interfaces. This survey provides a technically thorough taxonomy and evaluation of progress to date, highlighting a trajectory toward flexible, robust, multimodal agents anchored by foundation models but driven by data-centric, platform-adaptive design.
Fundamental open questions remain around scalable generalization, privacy-preserving inference, real-time orchestration, and trustworthy, controllable execution. Continued advances in interface unification, data curation, open-source LAMs, and rigorous evaluation will be essential for the maturation and widespread deployment of this new class of digital agents. The long-term vision is practical generalist AI automation agents that serve as a universal interface layer between human intent and the digital environment, abstracting the technical complexity of heterogeneous application ecosystems.