- The paper introduces FedDW, a framework that distills weights using consistency optimization with DLE data to counteract non-IID challenges in federated learning.
- It employs soft labels and a class relation matrix to align client models with globally aggregated information, ensuring improved model generalization.
- Experimental results demonstrate superior accuracy and scalability with minimal computational overhead compared to 10 existing federated learning frameworks.
"FedDW: Distilling Weights through Consistency Optimization in Heterogeneous Federated Learning" (2412.04521)
Introduction to Federated Learning and Heterogeneity Issues
Federated Learning (FL) enables distributed training of neural networks across multiple clients without sharing raw data, thus preserving privacy. The efficacy of traditional FL methods, like FedAvg, is predicated on homogeneous data distribution and identical computational capacity across clients. However, real-world scenarios introduce data heterogeneity and varying computational capabilities, which adversely affect model efficacy and efficiency. This paper addresses these challenges by proposing a novel framework named FedDW, which leverages consistency optimization with deep learning encrypted data (DLE data) to counteract heterogeneity issues.
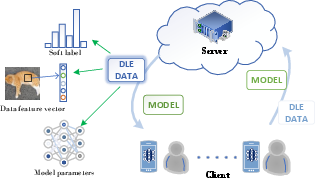
Figure 1: Schematic diagram of DLE data transmission in the federated system and three common deep encryption data.
Deep Learning Encrypted Data (DLE Data)
DLE data is a critical concept introduced in this paper to mitigate the privacy and efficacy dilemmas inherent in FL under heterogeneous conditions. Three types of DLE data are identified: feature vectors, soft labels, and neural network models. Feature vectors compress high-dimensional data into low-dimensional spaces irreversibly, retaining essential features and reducing transmission costs. Soft labels use knowledge distillation to represent inter-class relationships rather than the data itself, while neural network models serve as an encryption modality due to their inherent unexplainability.
Consistency Optimization Paradigm
The paper proposes leveraging consistency relationships between soft labels and the classification layer's parameter matrix, defined through their self-product, to regulate training. This approach ensures the classification layer's parameter distribution aligns with IID conditions even under non-IID data distributions, effectively reducing the impact of data heterogeneity.
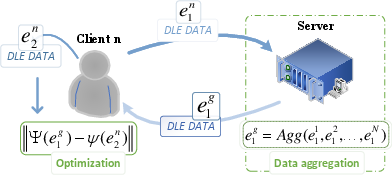
Figure 2: The client uses DLE data for regular optimization, generating two types: e1 for global aggregation to capture global information, and e2 to guide optimization toward global generalization by aligning with e1. e1 must be chosen to ensure it retains generalization after aggregation. In particular, e1 and e2 may be equal.
FedDW Framework
FedDW operates by aggregating soft labels from clients to form a global average soft labels matrix (SL matrix), which subsequently regulates the Class Relation (CR) matrix derived from the classification layer’s parameters. This regulation ensures that client models maintain consistency with globally aggregated information, thus improving model generalization under heterogeneous conditions. The architecture of the FedDW framework encompasses feature extractors, mapping layers, classification layers, and the server-client communication protocol necessary for optimally employing SL and CR matrices.
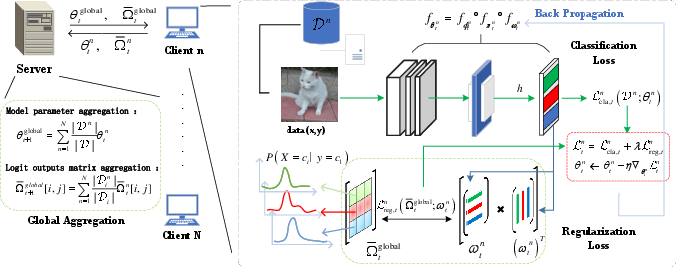
Figure 3: The entire training process of FedDW.
Methodology and Theoretical Analysis
FedDW's methodological core is its distribution matching process, drawing parallels with contrastive learning paradigms. Empirical analysis demonstrates consistency between SL and CR matrices under IID conditions, validating their role in mitigating heterogeneity. Theoretical analysis supports the framework’s convergence rate under non-IID conditions, and regularization constraints ensure computational efficiency. The regularization term is bounded, ensuring limited computational overhead during parameter update iterations.
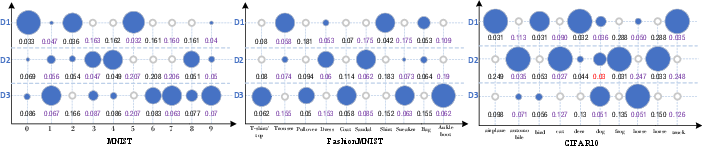
Figure 4: We test each dataset 100 times. Due to space constraints, only three different data (D1, D2, D3) are randomly selected here to display the modulus values. The size of the blue circle represents the proportion of the data in this class. The larger the circle, the more data there is in this class. The white circle means there is no data in this class. The number under the circle represents the relative size of the weight vector modulus of the class corresponding to this class, while the calculation formula of other classes is ∑i=1∣C∣∥ωci∥2∥ωck∥2. The red number represents the counterexample shown. In 100 experiments on three data sets, we only found 3 counterexamples.
Experimental Results and Scalability
FedDW was tested against 10 prominent FL frameworks, demonstrating superior accuracy, especially in highly heterogeneous environments, with only minor declines in performance despite increased data heterogeneity. Scalability tests affirm FedDW's robustness with varying client quantities, model architectures, and training rounds, ensuring adaptability across multiple operational scenarios. Further efficiency tests highlight negligible added computational costs due to regularization, positioning FedDW as an optimal choice for large-scale FL applications.
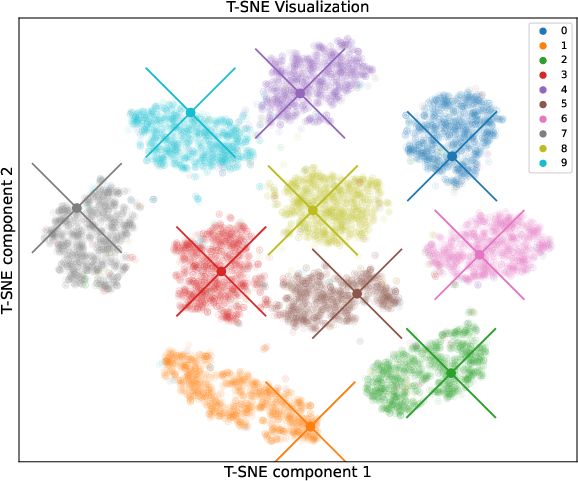
Figure 5: We use "X" to represent the weight vector of each class of data in the classification layer, and the midpoint of "X" represents the specific position of the weight vector in the visualization space. We can see that each weight vector belongs to the cluster of the corresponding class. Note that, before visualization, we need to perform Vector Unitization.
Conclusion
FedDW presents a significant advancement in FL, addressing the prominent issue of data heterogeneity with minimal additional computational burden. Its design leverages DLE data to preserve confidentiality while enhancing inter-client communication and model generalization capabilities. Future research will focus on integrating FedDW into large-scale models to broaden its applicability within the expanding parameter landscapes typical of modern AI models.