- The paper introduces a superpixel tokenization approach that preserves semantic coherence by ensuring each token represents a single visual concept.
- It employs a two-stage pipeline featuring convolutional feature extraction, learnable sinusoidal positional encodings, and superpixel-aware pooling to aggregate features.
- Experimental results demonstrate that SuiT models outperform traditional ViTs on ImageNet-1K and robustness benchmarks, proving both accuracy and improved transfer learning.
Introduction
The application of Transformers, primarily heralded in NLP, marks a pivotal shift in Computer Vision (CV) with the advent of Vision Transformers (ViTs). However, traditional tokenization in ViTs relies on splitting images into fixed-size grid patches, potentially mixing visual concepts within a single token. This paper introduces a novel superpixel tokenization approach aimed at ensuring that each token encapsulates a single visual concept by leveraging superpixels, thereby preserving the semantic integrity of visual tokens.
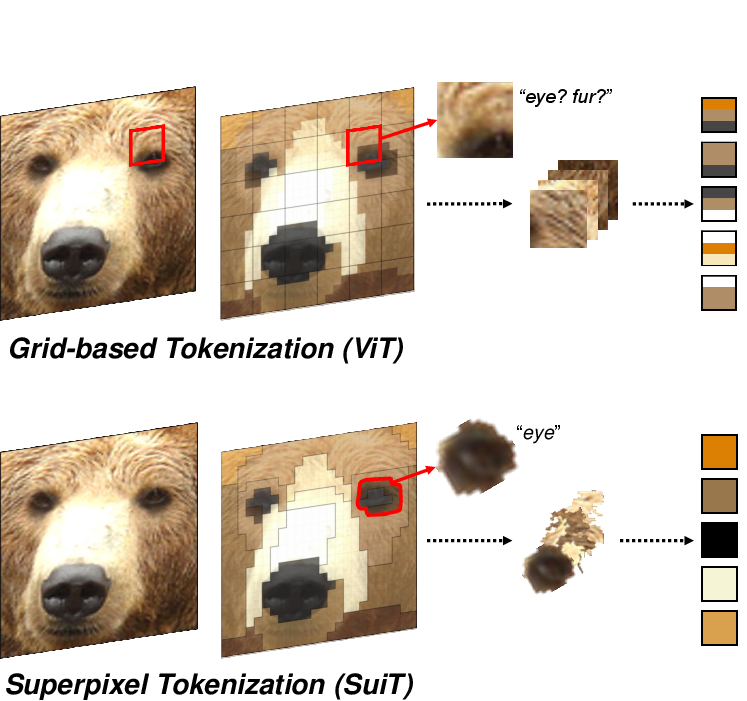
Figure 1: A high-level overview of tokenization. (Top) The conventional grid-like tokenization in ViT and (Bottom) our proposed superpixel tokenization.
Methodology
Superpixel Tokenization Pipeline
The proposed methodology outlines a two-stage superpixel tokenization pipeline, tailored to address the irregularities of superpixels—different shapes, sizes, and locations—which are not compatible with existing ViT tokenization strategies.
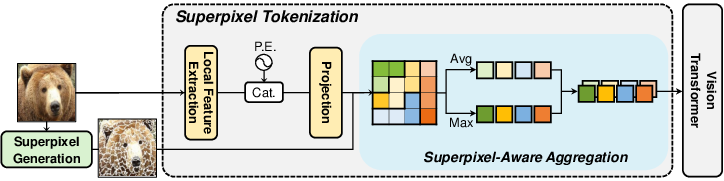
Figure 2: Overview of our superpixel tokenization pipeline. Local features are extracted and combined with positional encodings, followed by superpixel-aware aggregation using mean and max pooling to produce superpixel tokens, which are fed into a Vision Transformer.
Pre-aggregate Feature Extraction:
Local features are extracted via a convolutional block, adapting features from methods like ResNet. Positional encodings are integrated using learnable sinusoidal frequencies, crucial for handling the spatial complexities inherent in superpixels.
Superpixel-aware Aggregation:
The features are aggregated within each superpixel through pooling operations, effectively creating semantically rich and consistent tokens. This aggregation leverages both average and max pooling to capture holistic and salient features, respectively.
Experimental Evaluation
Classification and Robustness
Extensive experiments were conducted on ImageNet-1K and various robustness benchmarks such as ImageNet-A and ImageNet-O. The SuiT models surpass traditional DeiT models in efficiency and accuracy across multiple scales, demonstrating the capability of semantic-preserving tokenization to support robust feature extraction and OOD generalization.
Comparative Analysis
SuiT's methodology was assessed against recent tokenization advances like Quadformer and MSViT, showcasing superior performance in both fine-tuning and from-scratch training scenarios.
Applications in Transfer Learning and Self-supervised Learning
SuiT models exhibited enhanced transferability in domain adaptation tasks across diverse datasets (e.g., iNaturalist, Flowers102). In self-supervised scenarios defined by frameworks like DINO, SuiT facilitates improved object recognition capabilities via refined self-attention maps that better capture object semantics without supervision.

Figure 3: Self-attention map comparison between DINO-ViT and DINO-SuiT. All maps are visualized by averaging the [CLS] token's self-attention from the final layer across all heads.
Analysis
The paper further provides empirical evidence through class identifiability analyses and semantic clustering (Figure 4), substantiating superpixel tokens' ability to maintain semantic coherence. These in-depth analyses reveal that superpixel tokens align more closely with semantic boundaries, enhancing interpretability and integrity.

Figure 4: Comparison of K-means clustering results for patch tokens from DeiT and superpixel tokens from SuiT, both supervisedly trained on ImageNet-1K, with K=6. Superpixel tokens in SuiT tend to cluster by semantic meaning, while ViT patch tokens mostly cluster by positional information.
Conclusion
The introduction of superpixel tokenization offers a promising alternative to conventional patch-based tokenization in ViTs, significantly improving semantic preservation and model performance across a spectrum of tasks. By innovating token design, this approach enhances not only the accuracy and robustness of ViTs but also their application in complex scenarios requiring semantic integrity. Further research could expand on the integration of superpixels into existing frameworks, potentially optimizing other architectural components to exploit these semantic-rich tokens fully.