- The paper presents a detailed taxonomy of LLMs-as-judges, unifying pointwise, pairwise, and listwise evaluation methods with a formal evaluation framework.
- It introduces key methodologies such as prompt-based, tuning-based, and human-AI collaboration approaches, emphasizing bias mitigation and robustness challenges.
- The findings highlight both the scalability and limitations of LLM-based evaluation, offering a roadmap for future research towards trustworthy and efficient AI assessment.
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Introduction and Motivation
The paper "LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods" (2412.05579) provides an exhaustive analysis of the paradigm in which LLMs are employed as evaluators—termed "LLMs-as-judges"—for assessing the quality, relevance, and effectiveness of outputs in NLP and related domains. The survey systematically categorizes the landscape of LLM-based evaluation, addressing the motivations, methodologies, applications, meta-evaluation strategies, and inherent limitations of this approach.
The motivation for LLMs-as-judges arises from the inadequacy of traditional automatic metrics (e.g., BLEU, ROUGE) in capturing nuanced aspects such as fluency, coherence, and creativity in generative tasks, and the high cost and scalability issues of human annotation. LLMs, with their broad generalization and interpretability, offer a scalable, flexible, and reproducible alternative for evaluation, but introduce new challenges in reliability, bias, and robustness.
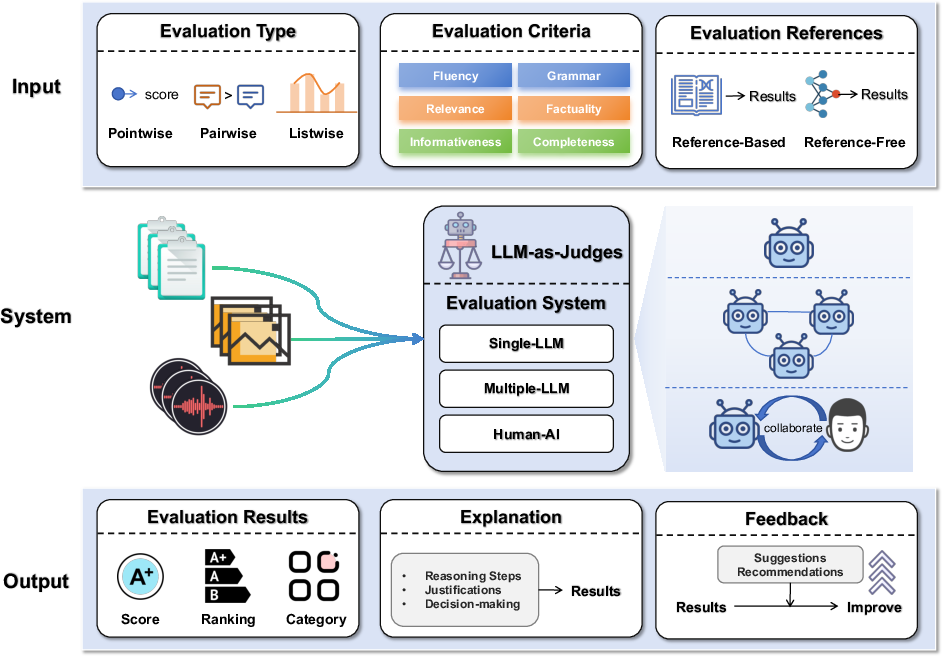
Figure 2: Overview of the LLMs-as-judges system.
The survey formalizes the LLMs-as-judges paradigm as an evaluation function E that maps a tuple of evaluation type (T), criteria (C), item (X), and optional references (R) to outputs: result (Y), explanation (E), and feedback (F). This abstraction unifies pointwise, pairwise, and listwise evaluation modes, and supports both reference-based and reference-free settings.
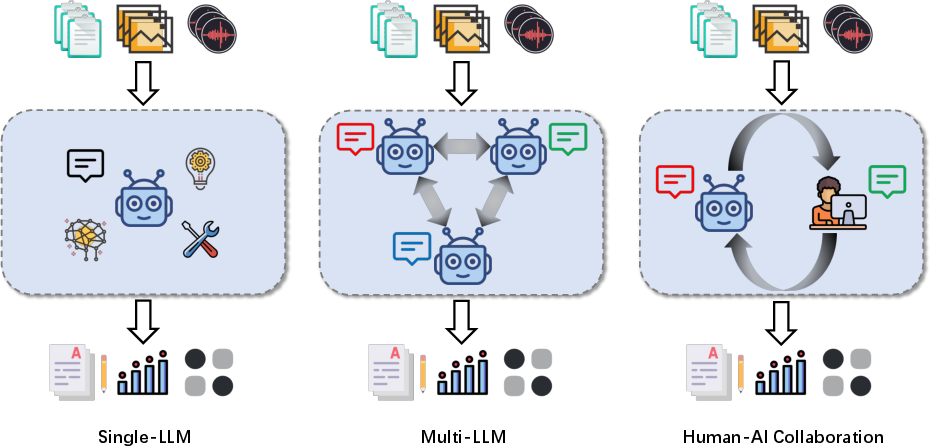
The system architectures are categorized as:
- Single-LLM systems: A single model performs evaluation, offering simplicity and scalability but limited robustness to bias and domain specificity.
- Multi-LLM systems: Multiple models interact (cooperatively or competitively) or aggregate judgments, improving robustness and coverage at higher computational cost.
- Human-AI collaboration: LLMs and humans jointly evaluate, combining scalability with human oversight for reliability and fairness.
Functionality: Why Use LLMs-as-Judges?
LLMs-as-judges serve three primary functions:
- Performance Evaluation: Assessing response quality (accuracy, relevance, fluency) and holistic model capabilities, both statically (benchmarks) and dynamically (interactive, multi-turn evaluation).
- Model Enhancement: Providing reward signals for RLHF, acting as verifiers during inference (e.g., Best-of-N, Tree/Graph of Thoughts), and supplying iterative feedback for self-refinement and debugging.
- Data Construction: Automating data annotation (text, multimodal, emotion, etc.) and synthetic data generation for instruction tuning, preference modeling, and reasoning tasks.
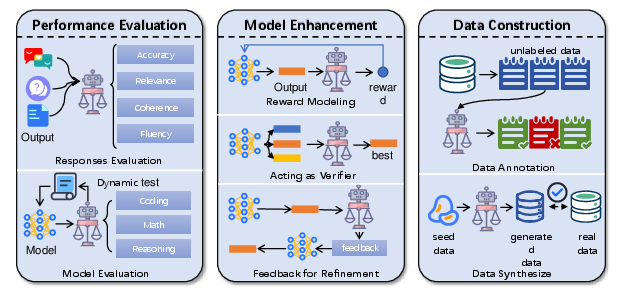
Figure 4: Overview of the Functionality of LLMs-as-judges.
Methodology: How to Use LLMs-as-Judges?
The survey delineates a rich taxonomy of methodologies:
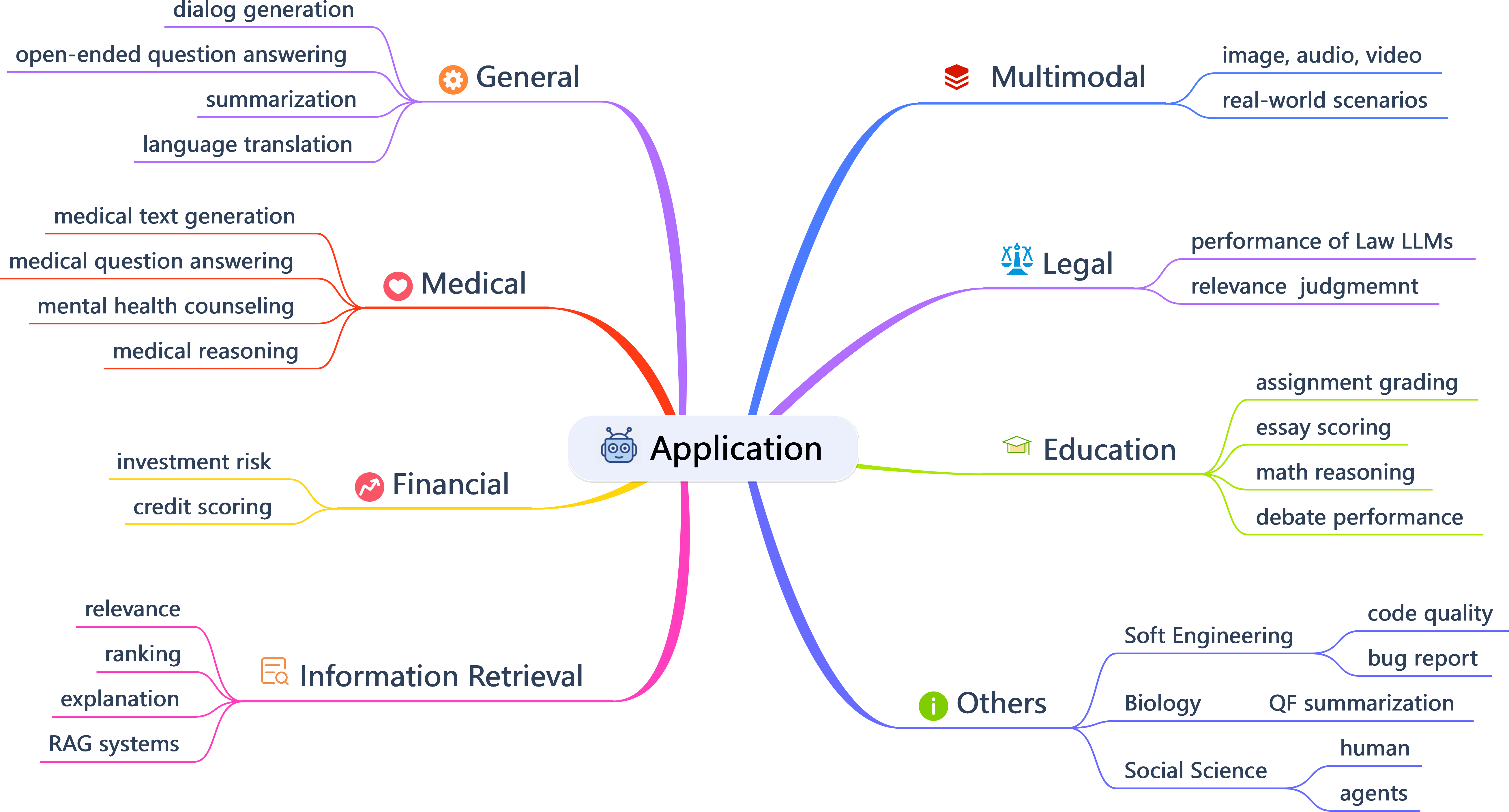
Applications: Where to Use LLMs-as-Judges?
LLMs-as-judges are deployed across a broad spectrum of domains:
Meta-evaluation is addressed via:
- Benchmarks: A comprehensive suite of 40+ datasets spanning code, translation, summarization, dialogue, story generation, value alignment, recommendation, search, and multimodal tasks. These benchmarks enable systematic comparison of LLM-judges against human annotation.
- Metrics: Agreement and correlation measures (accuracy, Pearson, Spearman, Kendall's Tau, Cohen's Kappa, ICC) are used to quantify alignment with human judgments, with rank-based metrics preferred for ordinal or preference tasks.
Limitations and Open Challenges
The survey provides a granular taxonomy of limitations:
- Biases: Presentation (position, verbosity), social (authority, bandwagon, diversity), content (sentiment, token, context), and cognitive (overconfidence, self-enhancement, distraction, fallacy-oversight). These biases can significantly distort evaluation outcomes and are not reliably mitigated by naive prompt engineering or model scaling.
- Adversarial Attacks: LLMs-as-judges are vulnerable to prompt injection, universal adversarial triggers, and optimization-based attacks, which can systematically manipulate evaluation results and undermine benchmark reliability.
- Inherent Weaknesses: Knowledge recency, hallucination, and domain-specific knowledge gaps limit the reliability of LLM-judges, especially in dynamic or specialized contexts.
Future Directions
The paper identifies several research frontiers:
- Efficiency: Automated construction of evaluation criteria, scalable and modular evaluation frameworks, and computationally efficient candidate selection and aggregation.
- Effectiveness: Integration of reasoning and judgment, collective multi-agent evaluation, enhanced domain adaptation, cross-domain/cross-lingual transfer, and multimodal integration.
- Reliability: Improved interpretability, bias mitigation, fairness constraints, and robustness to adversarial and noisy inputs.
Implications and Outlook
The LLMs-as-judges paradigm is rapidly becoming central to the evaluation of generative models, agentic systems, and complex AI workflows. Its adoption is driven by the need for scalable, flexible, and interpretable evaluation, but its limitations—especially in bias, robustness, and domain adaptation—necessitate continued methodological innovation. The survey's comprehensive taxonomy and synthesis provide a foundation for future research on automated evaluation, meta-evaluation, and the development of trustworthy AI systems.
Conclusion
This survey establishes a rigorous framework for understanding, implementing, and advancing LLMs-as-judges. It highlights both the practical utility and the unresolved challenges of LLM-based evaluation, offering a roadmap for future research in scalable, reliable, and fair AI assessment. The field will benefit from continued exploration of hybrid human-AI evaluation, robust bias mitigation, and domain-adaptive methodologies to ensure that LLMs-as-judges can be trusted in high-stakes and diverse real-world applications.