- The paper introduces SoftVQ-VAE, which employs soft categorical posteriors to enhance latent space representation and achieve high compression without losing reconstruction fidelity.
- It leverages a Vision Transformer architecture to encode and decode images into a reduced set of 1-D tokens, significantly optimizing token efficiency.
- The approach demonstrates substantial throughput improvements, achieving up to 18x speedup for 256x256 images and 55x for 512x512 images compared to baseline models.
SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
This essay provides a concise technical overview of "SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer" with emphasis on practical implementation and performance implications for advanced generative modeling tasks.
Introduction to SoftVQ-VAE
SoftVQ-VAE introduces an innovative approach to image tokenization aimed at achieving high compression ratios without sacrificing reconstruction quality. The key mechanism involves utilizing soft categorical posteriors to effectively embody multiple codewords within each latent token. This endows the model with a significantly enriched latent space, optimizing both representation capacity and token compression efficiency. The tokenizer is particularly advantageous when integrated with Transformer-based generative models, notably improving throughput and training efficiency.
Architectural Overview
SoftVQ-VAE is structured around Vision Transformer (ViT) architecture, employing it to handle encoder and decoder functions. Images are discretized into a sequence of tokens which are then employed to execute both encoding and decoding processes (Figure 1). The key distinction in SoftVQ-VAE is the refactoring of the traditional VQ-VAE, moving from discrete to continuous tokenization enabling gradient optimization directly via reconstruction loss, efficiency in alignment with semantic-rich features, and leveraging the fully differentiable nature for refined latent space representation.
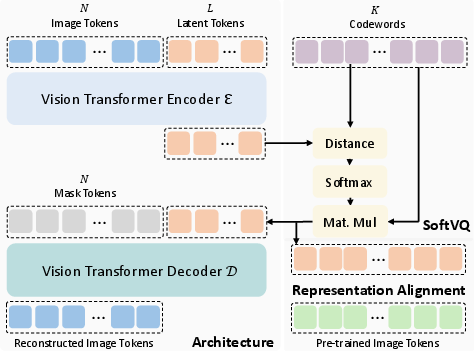
Figure 1: Illustration of SoftVQ-VAE. Left: Transformer encoder-decoder architecture with image tokens. Right: Fully-differentiable SoftVQ illustration.
Implementation Details
Encoding and Decoding Process: The encoding process begins with transforming the input image into latent representations through the ViT encoder, which supports arbitrary lengths of latent tokens. SoftVQ-VAE leverages learnable 1-D tokens that adapt image tokens through self-attention to condense information into smaller token sets.
Soft Categorical Posterior: The advancement here is the employment of a fully differentiable softmax function for posterior computation over codebook entries, thereby surpassing the non-differentiable bottleneck of traditional vector quantization (VQ). This supports a high compression ratio without undermining reconstruction fidelity, differentiating SoftVQ-VAE from predecessors.
Token Reduction and Throughput Enhancement: SoftVQ-VAE prominently reduces the number of tokens in the latent space to 32 or 64 from typical numbers like 256 or 1024 (Figure 2). This notably enhances both computational throughput and resource efficiency during inference and training phases, making it suitable for scaled applications.

Figure 2: ImageNet-1K 256x256 and 512x512 generation results using generative models trained on SoftVQ-VAE with 32 and 64 tokens.
Comparative Analysis and Results
Results highlight SoftVQ-VAE’s capabilities in achieving state-of-the-art performance metrics such as FID with substantial reductions in training iterations. The efficiency gains are backed by empirical results showing improvements up to 18 times in inference throughput for 256x256 images and a staggering 55 times for 512x512 resolutions compared to baseline models.
Implications and Future Directions
The research underscores significant implications for efficient model training and deployment. It suggests pathways for integrating the continuous tokenization strategy into future generative and multimodal AI architectures, empowering models to balance high performance with resource optimization. Future enhancements might explore adaptive codebook initialization strategies or leveraging larger pre-trained models for initialization to further enrich the latent space semantics without increasing computational heft.
Conclusion
SoftVQ-VAE presents a compelling leap forward in the field of efficient image tokenization. By bridging the gap between high compression and robust latent space representation, it sets a new standard for generating high-fidelity imagery with minimized computational requirements. This positions SoftVQ-VAE as a potential linchpin for next-generation generative models spanning a multitude of applications from computer vision to multimodal interactions.