- The paper introduces Flex-PE, a configurable SIMD multi-precision processing element that enhances AI throughput and energy efficiency.
- It employs a CORDIC-based approach to compute versatile activation functions and supports precision modes from 4-bit to 32-bit.
- Performance evaluations show up to 16× throughput gains and significant DMA read reductions, benefiting both edge-AI and HPC applications.
Flex-PE: Flexible and SIMD Multi-Precision Processing Element for AI Workloads
Introduction
The paper "Flex-PE: Flexible and SIMD Multi-Precision Processing Element for AI Workloads" presents a novel processing architecture designed to address the growing demands of AI workloads that require diverse precision and runtime configurability. The architecture introduces Flex-PE, which supports SIMD multi-precision operations and various runtime-configurable activation functions (AFs), including sigmoid, tanh, ReLU, and softmax, alongside MAC operation. The design aims to improve throughput and efficiency for both edge-AI and high-performance computing (HPC) applications. Notably, Flex-PE leads to significant reductions in DMA reads, enhancing energy efficiency and overall performance.
AI systems require a hardware architecture to maintain performance while addressing the bottlenecks related to memory and communication. Traditional solutions often lack the ability to simultaneously offer diverse precision and runtime AF reconfigurability. This paper addresses the gap by proposing Flex-PE, a multi-precision SIMD-enabled processing element that significantly enhances throughput—up to 16× for FxP4 and 8× for FxP8—through time-multiplexed hardware configurations.
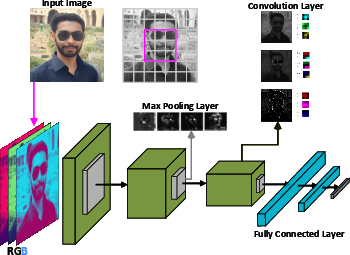
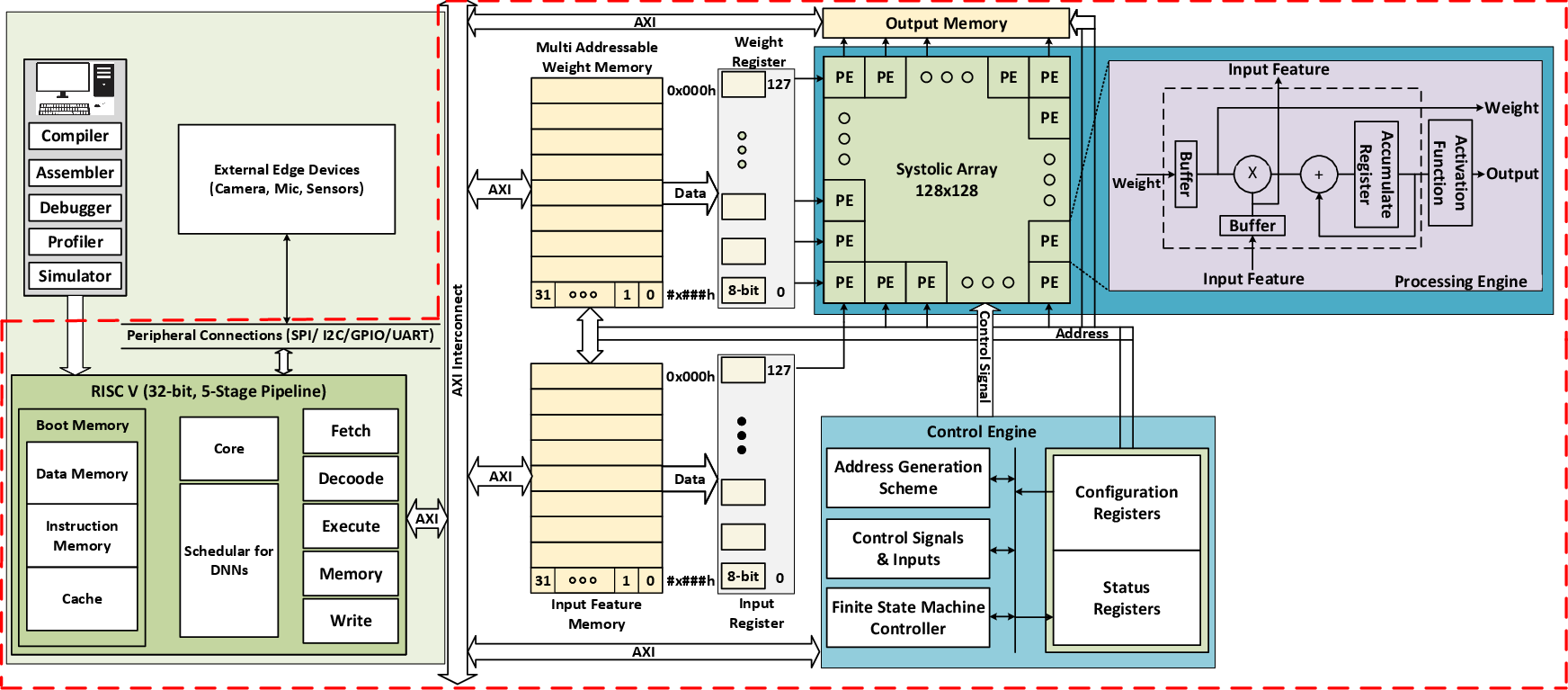
Figure 1: Typical DNN and AI SoC architecture employing a flexible, RISC-V-enabled systolic array.
Architecture and Methodology
The proposed Flex-PE architecture embraces the use of the CORDIC algorithm to enable efficient computation of activation functions across multiple precision levels. The architecture stands out for its efficiency in handling operations such as exponential functions and division required in AF computations. By incorporating both hyperbolic and linear modes within the CORDIC framework, Flex-PE facilitates diverse AFs while operating seamlessly across the precision spectrum—from edge-AI's 4-bit inference to HPC's 32-bit computations.
A critical feature of Flex-PE is its ability to adaptively switch between precision modes during runtime, allowing for optimal resource utilization and reduced energy consumption. This adaptability is achieved through a sophisticated control mechanism that dynamically selects the appropriate precision and AF based on workload requirements.
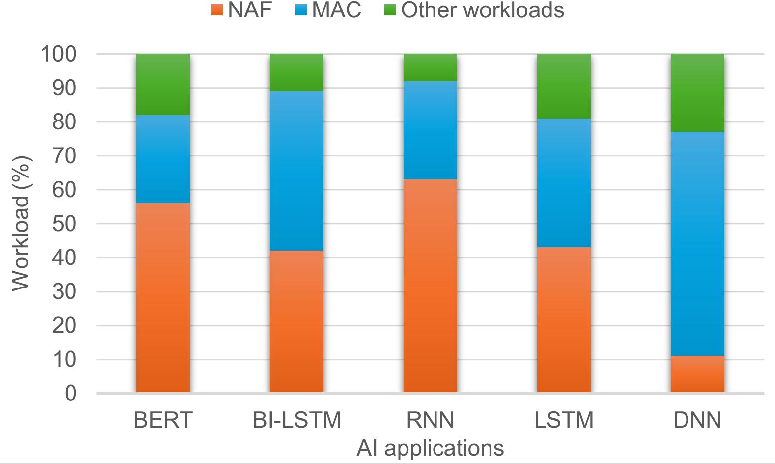
Figure 2: Workload analysis emphasizing on the growing demand for performance-enhanced non-linear activation functions.
The innovation further extends to the implementation of a SIMD-enabled systolic array architecture, which provides scalable throughput for various AI tasks through SIMD quantized operations. This scalability is crucial for AI applications ranging from real-time edge inference to large-scale cloud training, offering unparalleled flexibility and performance.
The performance evaluation of Flex-PE reveals significant gains in throughput and resource utilization compared to state-of-the-art solutions. The architecture supports emergent 4-bit computation for DL inference and boosts throughput for FxP8/16 modes prevalent in transformer and other HPC applications.
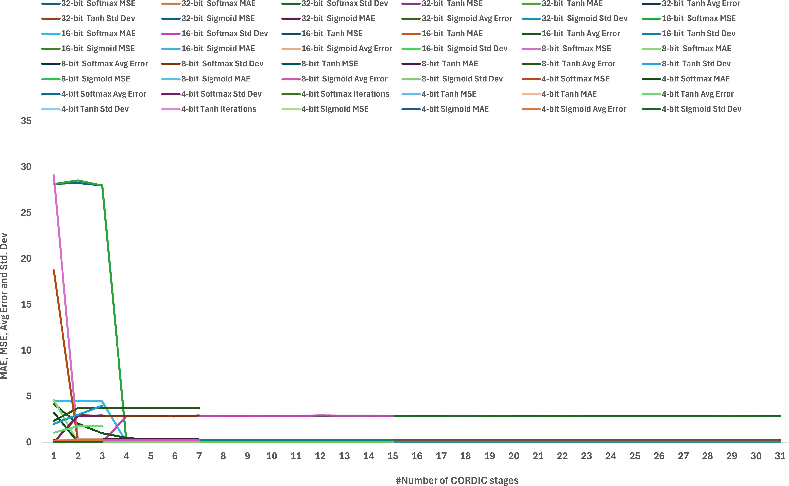
Figure 3: Pareto evaluation of error metrics for different CORDIC configurations with Flex-PE.
The proposed design demonstrated up to 62× and 371× reductions in DMA reads for input feature maps and weight filters, respectively, in VGG-16 implementations. This marks a remarkable advance in minimizing data transfer overhead while maximizing energy efficiency, achieving an impressive 8.42 GOPS/W with accuracy losses kept under 2%.
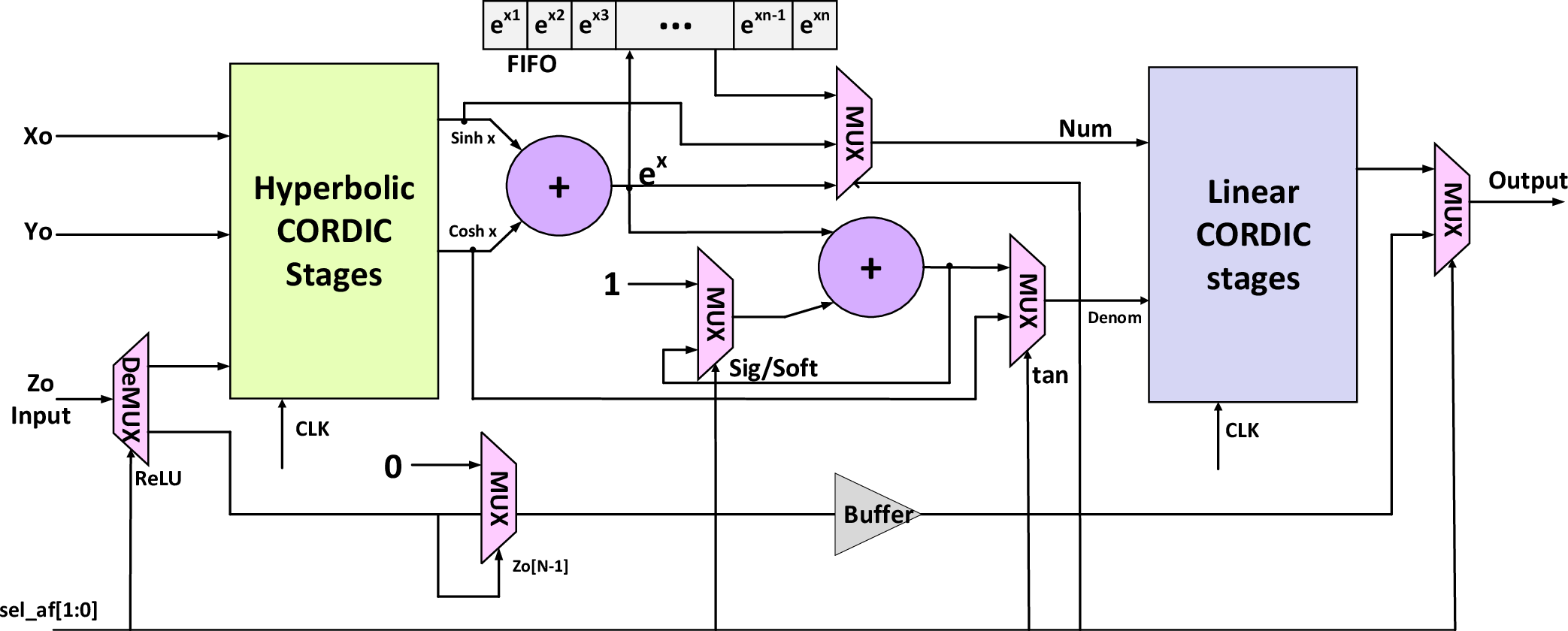
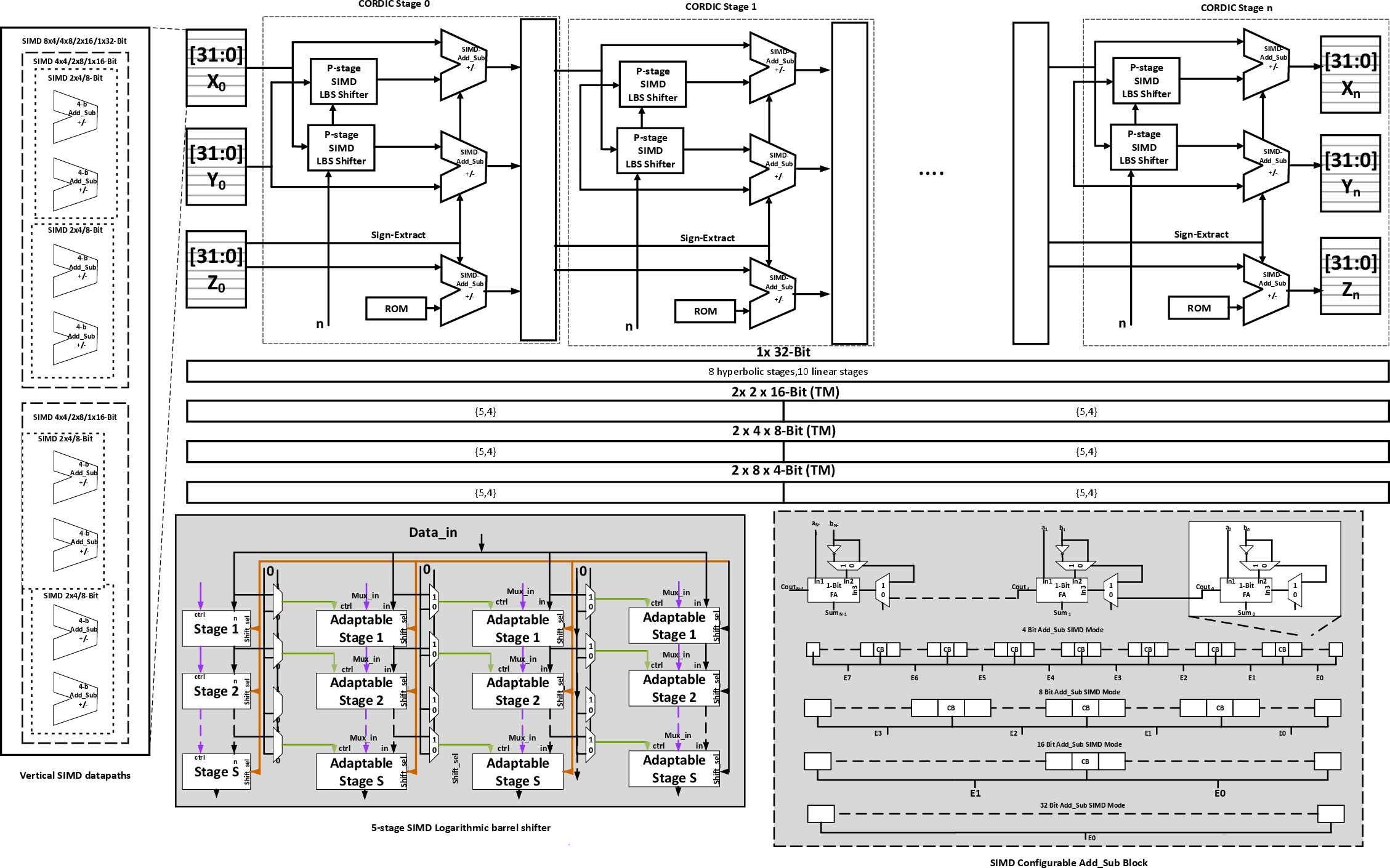
Figure 4: Detailed internal circuitry showcasing SIMD Logarithmic barrel shifter and configurable circuitry design.
Implications for AI Hardware Development
Flex-PE establishes a robust foundation for future AI hardware accelerators by efficiently leveraging SIMD and multi-precision computations. It addresses bottlenecks associated with precision variability and AF reconfigurability, thereby enhancing both edge and cloud AI deployment.
The versatile architecture supports a wide range of AI workloads, resulting in substantial performance improvements across various precision modes—ensuring quick inference on limited resources and facilitating high-precision tasks requiring detailed computation fidelity. As the industry moves towards developing more sophisticated AI models, the advancements introduced by Flex-PE provide essential groundwork for building energy-efficient and scalable AI accelerators.
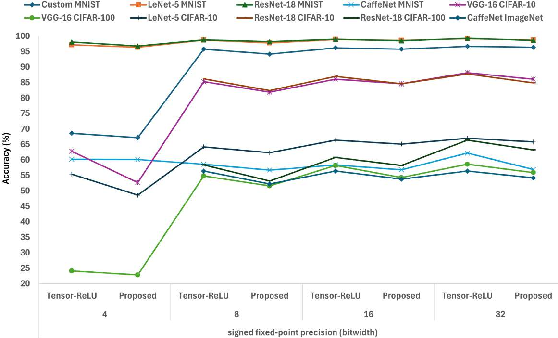
Figure 5: Evaluation of DNN accuracy showcasing effects of precision scalability on CORDIC-based SIMD processing engine.
Conclusion
In conclusion, Flex-PE represents a significant stride towards efficient AI processing architectures by providing flexible, configurable activation functions alongside SIMD multi-precision support in a single, scalable design. The paper highlights the impressive throughput gains and reductions in data movement, which translate to enhanced energy efficiency for a wide array of AI tasks. The architectural innovations introduced—such as the novel use of CORDIC for configurable AFs and precision switching—lay the groundwork for future developments in AI hardware, catering to both edge and cloud environments with increased robustness.
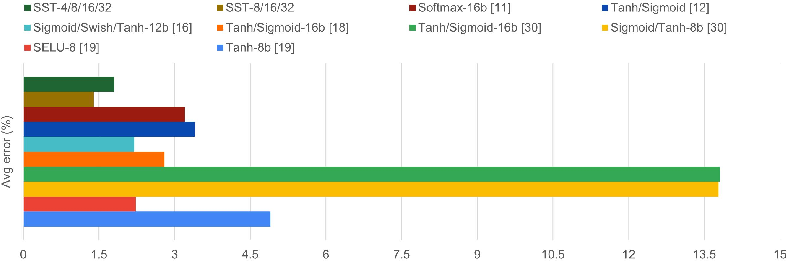
Figure 6: Comprehensive evaluation of mean error metrics for proposed pipelined and iterative config-AF against state-of-the-art works.