- The paper introduces a novel integration of energy-based models with latent diffusion processes to generate complex human motions from multiple semantic inputs.
- It presents a synergistic energy fusion approach that combines latent-aware and semantic-aware energy functions to enhance motion coherence and reduce artifacts.
- Experimental results demonstrate superior performance across benchmarks, achieving improved semantic alignment and reduced motion issues compared to existing methods.
EnergyMoGen: Compositional Human Motion Generation with Energy-Based Diffusion Model in Latent Space
Introduction and Background
The paper "EnergyMoGen: Compositional Human Motion Generation with Energy-Based Diffusion Model in Latent Space" addresses the challenge of generating complex human motion from multiple semantic concepts using latent diffusion models. Traditional approaches have struggled with effectively composing multiple semantic concepts into coherent motion sequences. EnergyMoGen introduces a novel framework combining aspects of energy-based models and latent diffusion models to tackle this issue.
The motivation for this work stems from the limitations of existing motion generation models, particularly those that rely on simple per-frame composition and lack a strong connection between latent features and physical motion representations. The authors draw inspiration from the compositional capabilities observed in human cognition, aiming to replicate this ability in a computational model.
Methodology
Energy-Based Model Integration
The core contribution of EnergyMoGen lies in its integration of energy-based models (EBMs) with diffusion processes to facilitate compositional motion generation. The key idea is to interpret the generative process of latent diffusion models as an energy combination problem, allowing for the composition of complex motions through conjunction and negation operations.
EnergyMoGen implements a dual-spectrum approach using two types of EBMs:
- Latent-Aware EBMs: This spectrum treats the diffusion model itself as an energy-based model by employing classifier-free guidance, which allows for the straightforward composition of multiple motion models in the latent space through predefined energy functions.
- Semantic-Aware EBMs: Using cross-attention mechanisms, this spectrum supports semantic composition by adjusting text embeddings with adaptive gradient descent operations. This approach leverages the energy-based interpretation of cross-attention to guide motion generation towards multi-concept text inputs.
Synergistic Energy Fusion
To address the challenges of semantic inconsistency and motion distortion inherent in these two spectra, EnergyMoGen introduces Synergistic Energy Fusion. This methodology combines multiple energy terms derived from both latent-aware and semantic-aware models, creating a robust framework capable of synthesizing high-quality, complex motion sequences.
Experimental Results
EnergyMoGen demonstrates superior performance across multiple benchmarks and tasks, including text-to-motion generation, compositional motion generation, and multi-concept motion generation. The quantitative results reveal its ability to outperform existing state-of-the-art models on diverse evaluation metrics such as R-Precision and FID.
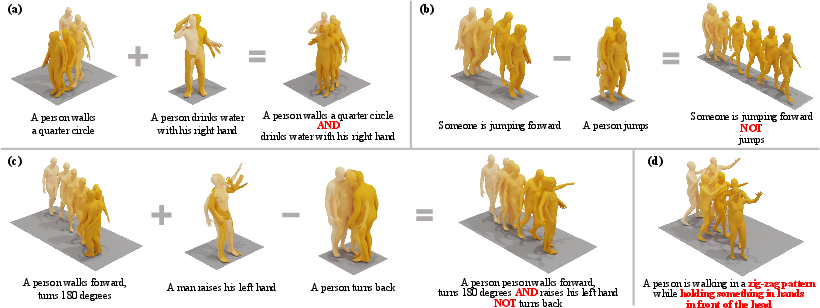
Figure 1: Compositional motion generation. Our approach can compose complex motions from simple concepts in settings of (a) concept conjunction, (b) concept negation, (c) compositional motion generation with conjunction and negation, and (d) multi-concept motion generation.
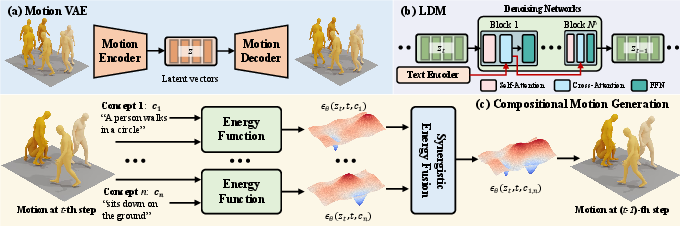
Figure 2: Overview of EnergyMoGen. (a) Motion VAE maps 3D human motion into N latent vectors. (b) Cross-attention-based transformers as the denoising network in LDM.
In practical scenarios, the model not only improves motion quality and semantic alignment but also reduces common artifacts such as foot sliding and motion jitter. Additional dataset augmentation experiments show EnergyMoGen's capability to enhance training performance when integrated with larger, composed motion sets.
Implications and Future Directions
The implications of EnergyMoGen are noteworthy both theoretically and practically. By leveraging energy-based interpretations, this approach offers a new perspective on motion composition in latent spaces, potentially inspiring a wave of future research into energy-based generative models.
Practically, this framework could enhance applications in animation, virtual reality, and robotics, where generating realistic and complex human motions is crucial. Furthermore, the potential for dataset augmentation via compositional generation could assist in addressing data scarcity issues in motion synthesis challenges.
Future research might explore extending the framework to other generative domains, refining the energy functions to accommodate even more nuanced motion nuances, or integrating the approach with larger LLMs for improved semantic comprehension.
Conclusion
EnergyMoGen stands as an exemplary fusion of latent diffusion processes and energy-based models, offering a powerful tool for compositional human motion generation. Its innovative approach to composing complex motions from simple semantic inputs not only advances the state of the art but also lays a foundation for future explorations into adaptive energy-based generative modeling.