- The paper demonstrates that MoE models exhibit significant expert specialization based on token POS, surpassing expectations from uniform routing.
- It employs a layer-wise analysis and an MLP on expert paths to quantify the impact of linguistic features on routing decisions across various models.
- Ablation studies reveal that early model layers capture crucial syntactic cues, highlighting potential improvements in model interpretability and task performance.
Part-Of-Speech Sensitivity of Routers in Mixture of Experts Models
Introduction
The paper "Part-Of-Speech Sensitivity of Routers in Mixture of Experts Models" investigates the routing behavior of tokens in Mixture of Experts (MoE) models with a focus on their linguistic features, particularly Part-of-Speech (POS) tags. The study aims to determine whether these models exhibit specialization by routing tokens with similar linguistic traits to specific experts. The experiment involves analyzing token trajectories across different MoE architectures to assess expert specialization in processing tokens based on their syntactic categories.
MoE Architecture Overview
Mixture of Experts models are designed to efficiently distribute processing across multiple sub-networks, called experts, within a Feed Forward Network (FFN) layer. A router model determines which subset of experts should process each token. The routing decision is based on a learned linear layer that maps input token representations to logits, subsequently normalized using the softmax function to determine routing probabilities. Only the top-k experts, selected based on these probabilities, are engaged in processing each token, ensuring computational efficiency.
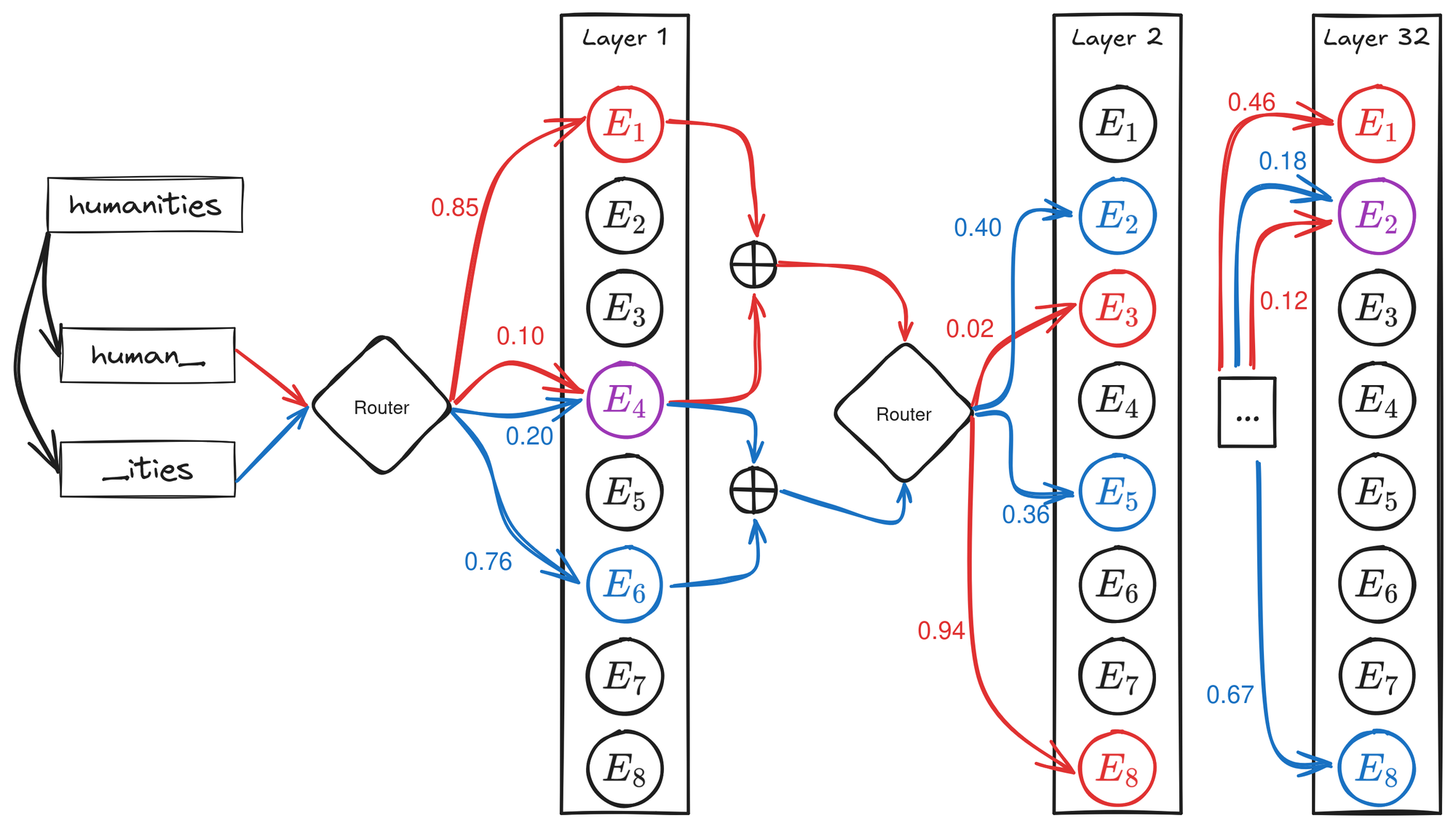
Figure 1: Example of token routing with 2 of 8 selected experts. For "human_", the path is [(1,4),(8,3),…,(1,2)]; for "_ities", it is [(6,4),(2,5),…,(2,8)].
Methodology
The paper employs model-integrated routers as probing tools to understand expert specialization better. By examining the sequence of top-k experts chosen at each layer, the study assesses how specialization emerges in response to the linguistic characteristics of tokens.
- Layer-wise Specialization Analysis: Measures expert specialization per layer and calculates average specialization scores across layers, comparing these with expected routing distributions under uniform assumptions.
- Expert Routing Paths: Routing information across layers is used to train a Multi-Layer Perceptron (MLP) to predict POS tags, exploiting the captured linguistic information in the expert paths.
Experiment and Results
The experiment involved evaluating six popular MoE models, analyzing their routing behaviors using a tokenized version of English sentences from the OntoNotes 5.0 dataset. The study utilized both path-based analysis and layer-wise specialization metrics to assess the POS-related specialization characteristics of these models.
Layer-Wise Analysis shows that all models exhibit notable expert specialization for certain POS categories, particularly for syntactic structures like nouns, verbs, and punctuation. The global specialization scores were significantly higher than expected under a uniform distribution hypothesis. Across models, the Phi-3.5-MoE-instruct and OLMoE-1B-7B showed prominent specialization.
POS Prediction Using Expert Paths: MLPs trained on expert paths demonstrated high accuracy in predicting POS tags, reinforcing that the token routing paths retain considerable syntactic information.

Figure 2: 2D-TSNE projection of token path
Ablation Study: Ablation experiments reveal more prominent POS information in early model layers, indicating that initial routing decisions capture significant syntactic cues essential for token categorization.
Conclusion
The study concludes that Mixture of Experts models inherently specialize in processing tokens based on their POS categories, with this specialization evidenced by their routing paths. These paths capture critical syntactic information, aiding in accurate POS prediction. This research provides insights into the linguistic phenomena underlying MoE models and suggests meaningful directions for enhancing model interpretability and performance on linguistically sensitive tasks. Future research could expand these results by studying generated token behavior or exploring more varied languages and domains.