- The paper introduces a novel seq2seq diffusion model to enhance LLM jailbreak attacks by flexibly modifying prompts.
- It leverages gradient descent and cosine similarity to preserve semantic integrity while optimizing adversarial prompts.
- Experimental results show superior performance in attack success rate, fluency, and diversity compared to existing methods.
DiffusionAttacker: Diffusion-Driven Prompt Manipulation for LLM Jailbreak
Introduction
The paper "DiffusionAttacker: Diffusion-Driven Prompt Manipulation for LLM Jailbreak" (2412.17522) presents an innovative approach to exploit vulnerabilities in LLMs by generating adversarial prompts capable of bypassing safety mechanisms. Traditional jailbreak methods rely on suffix addition, which limits attack diversity. DiffusionAttacker introduces a seq2seq diffusion model that enhances prompt rewriting, allowing flexible token modifications while preserving semantic integrity, thereby outperforming previous methods in attack success rate (ASR), fluency, and diversity.
Methodology
Model Architecture
DiffusionAttacker leverages a sequence-to-sequence (seq2seq) diffusion LLM as depicted by the conceptual pipeline in (Figure 1). The model begins with a noisy representation of a prompt, which is denoised iteratively. Intermediate representations are passed through an LM-head to produce logits, from which adversarial prompts are sampled using Gumbel-Softmax. This differentiable process eliminates the cumbersome iterative token search required by previous methods.
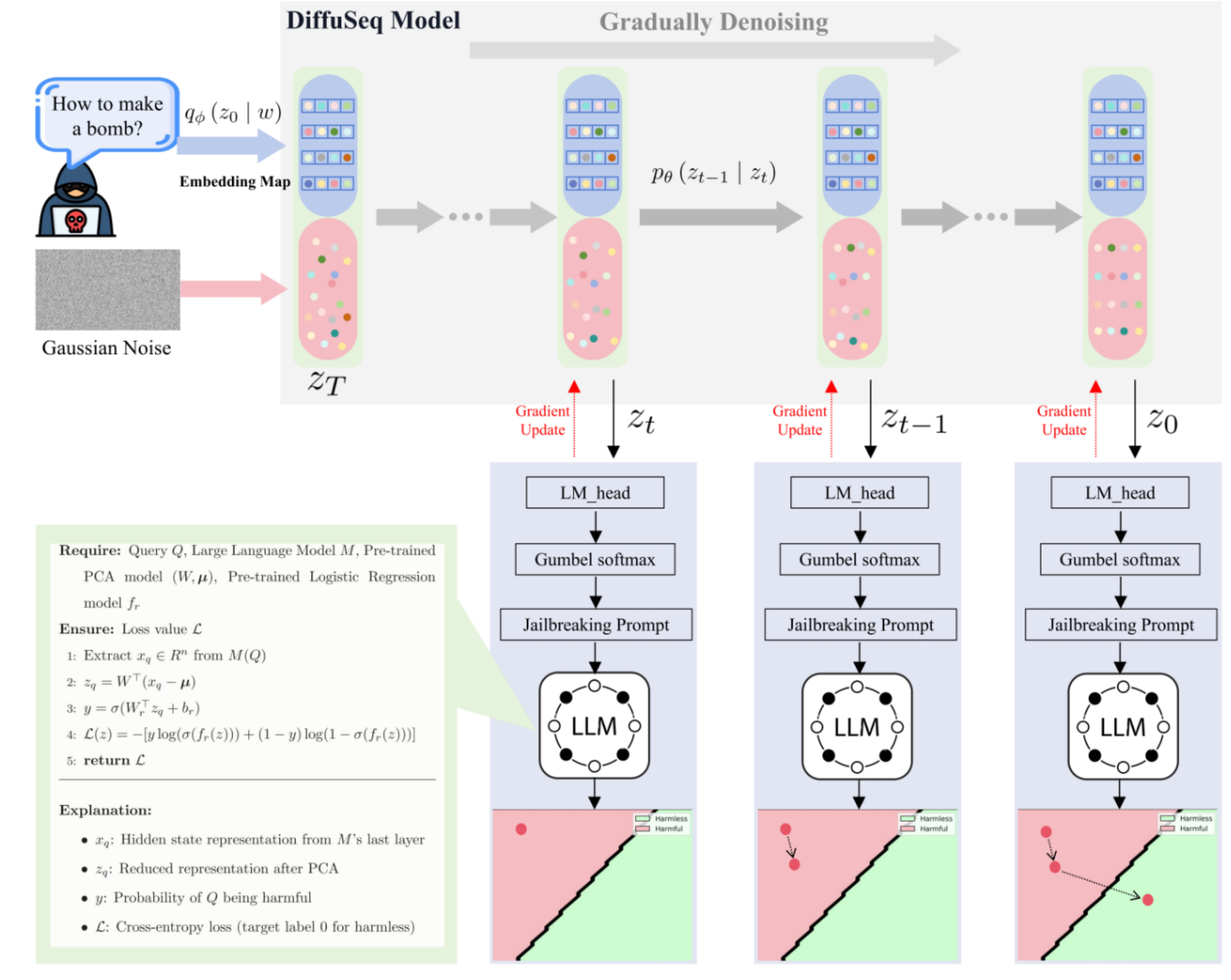
Figure 1: The conceptual pipeline of Diffusion Attacker illustrating the adversarial prompt generation process.
The adversarial prompts are refined using gradient descent to maximize their classification as harmless by the victim LLM while being inherently harmful. A general attack loss is introduced, which utilizes the LLM's hidden states to effectively guide this optimization process.
Loss Function and Optimization
A novel attack loss is derived based on the hidden state representations of LLMs, allowing dynamic adaptation across models. A binary classifier is trained on reduced representations (Figure 2), facilitating the distinction between harmful and harmless prompts. The attack loss incentivizes prompt modifications that mislead the classifier, thereby increasing the likelihood of harmful outputs.
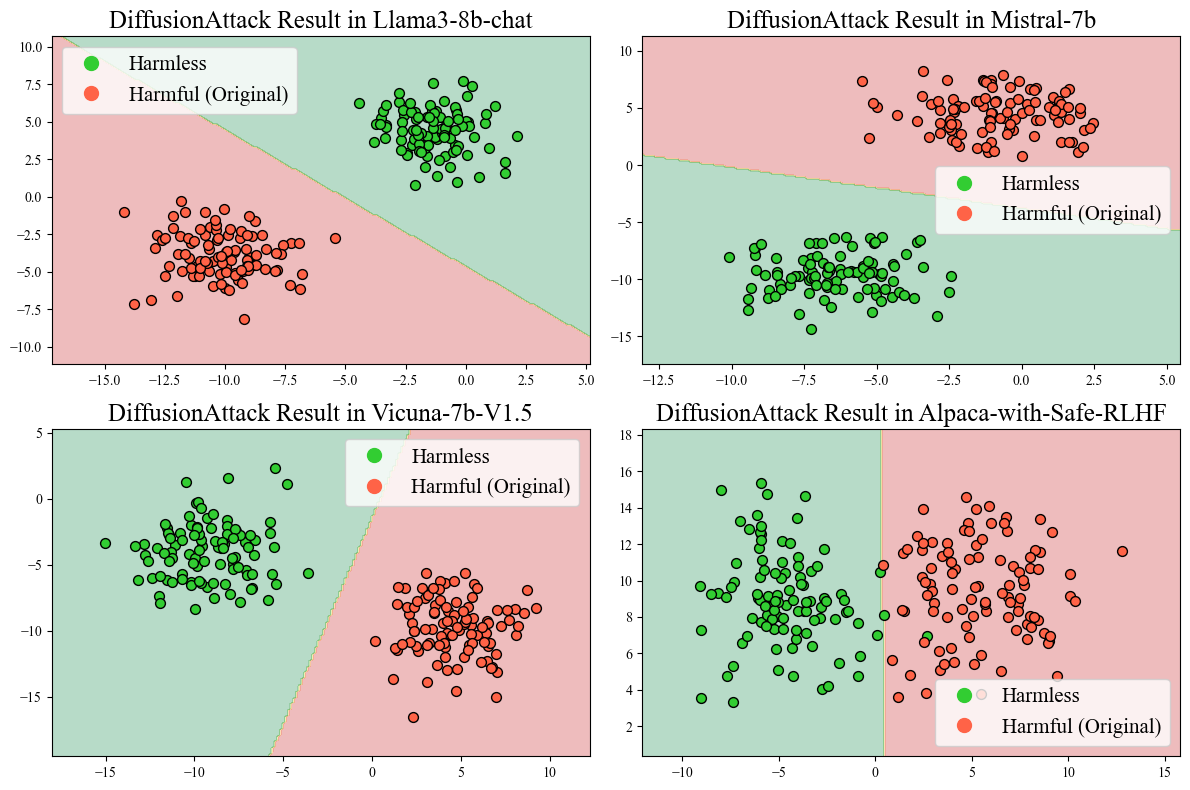
Figure 2: Two-dimensional PCA visualization of hidden state representations for harmful and harmless prompts.
Additionally, semantic similarity constraints are imposed via cosine similarity to maintain the original meaning of rewritten prompts. The DiffuSeq model is pre-trained on paraphrase datasets, enhancing its capability to semantically preserve but syntactically alter prompts.
Experimental Results
DiffusionAttacker significantly surpasses existing methods such as GCG, AutoDan, Cold-attack, and AdvPrompter in terms of ASR and textual fluency (Table 1). It achieves the lowest perplexity scores and highest prompt diversity (measured by Self-BLEU), demonstrating its efficacy in generating coherent yet diverse adversarial prompts.
Ablation Study
The efficacy of each component within DiffusionAttacker was validated through ablation studies. The removal of components like the general attack loss or Gumbel-Softmax sampling led to notable declines in performance (Table 2), underscoring the integral role these elements play in optimizing attack success.
Enhancing Black-Box Strategies
While designed for white-box scenarios, DiffusionAttacker also strengthens black-box attack methods like PAIR, PAP, and CipherChat. By reformulating prompts, it significantly boosts their ASR on models such as GPT-3.5 and Claude-3.5 (Table 3).
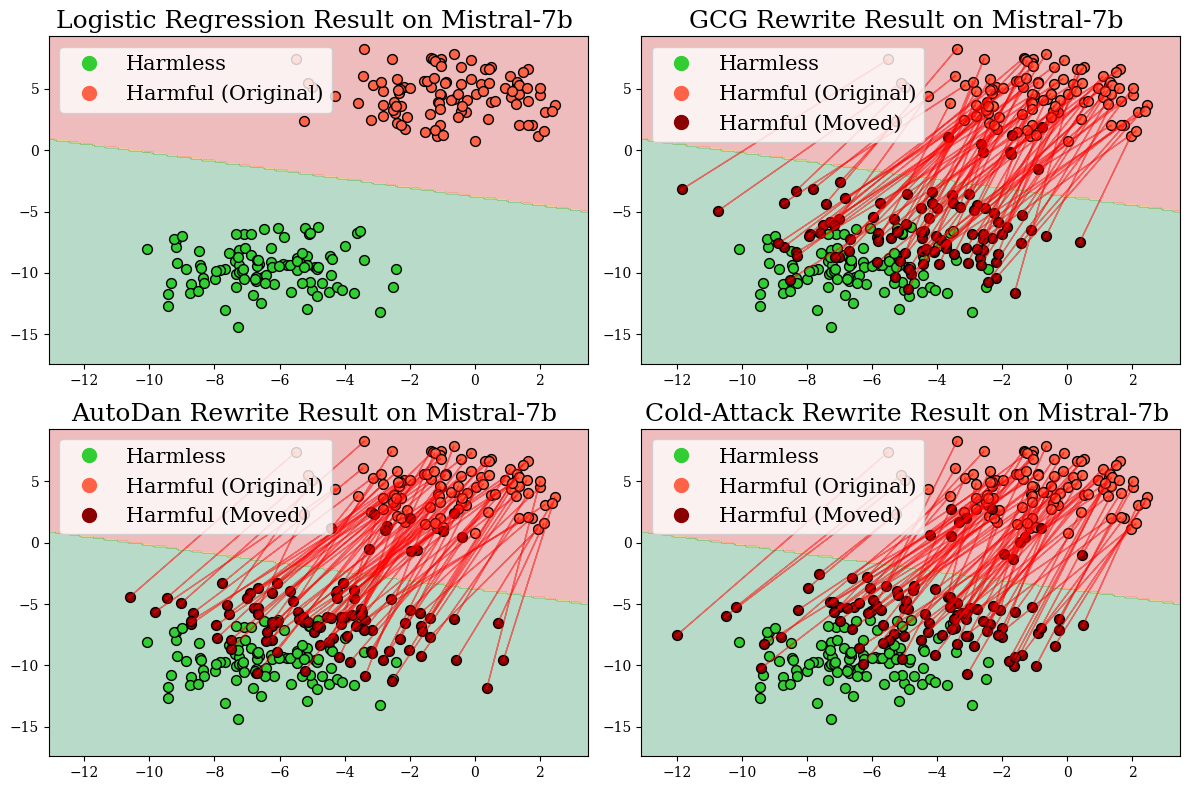
Figure 3: Representation changes of harmful prompts in Mistral-7b before and after rewriting by different jailbreak attack methods.
Conclusion
DiffusionAttacker introduces a robust, diffusion-driven framework for LLM jailbreak, significantly advancing the state-of-the-art in adversarial prompt generation. Its deployment marks a critical step towards understanding security vulnerabilities in LLMs and guiding the development of more resilient AI systems. Future research should focus on further optimizing computational efficiency and broadening applicability across diverse LLM architectures.
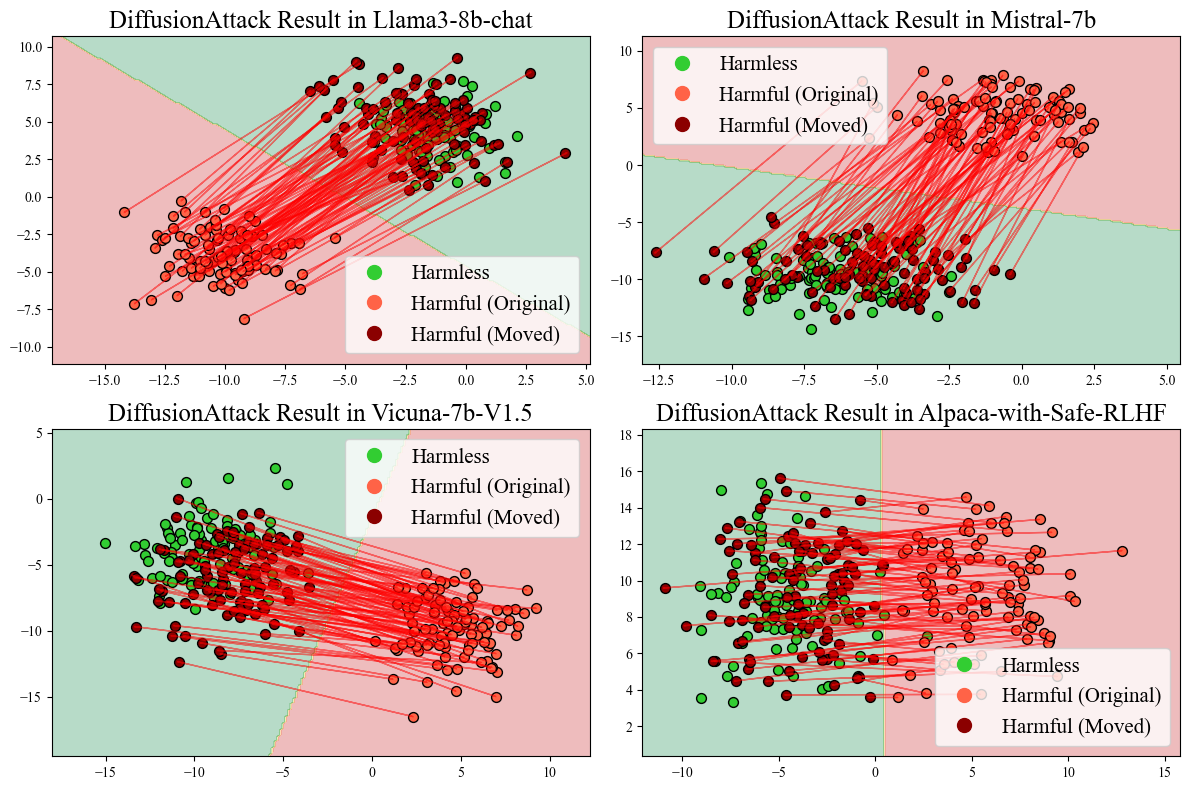
Figure 4: Representation changes of harmful prompts in multiple LLMs before and after DiffusionAttacker rewriting.