- The paper demonstrates that evaluating all multiple-choice options simultaneously, rather than separately, significantly enhances LLM performance.
- It reveals that ARC Challenge accuracy jumps from 64% to 93% when models assess all options together, questioning previous difficulty measures.
- The study advocates for evaluation frameworks that mimic human reasoning, which could bridge the performance gap between machines and humans.
Re-evaluating the ARC Challenge and Its Implications
Introduction
The paper "In Case You Missed It: ARC 'Challenge' Is Not That Challenging" explores significant discrepancies in the perceived difficulty of multiple-choice benchmarks within LLMs. Primarily, it attributes these discrepancies to the evaluation setup rather than the intrinsic complexity of the tasks themselves. The research critiques the conventional practice of evaluating each answer choice in isolation and presents compelling evidence that a simultaneous presentation of all options dramatically improves model performance, questioning previous assessments of model capabilities.
Evaluation Setup and Its Impact
Traditionally, LLM benchmarks, including ARC, MMLU, and BoolQ, utilize multiple-choice questions where each candidate answer is scored separately. This method imposes constraints that do not reflect natural reasoning processes where all options are considered in a coherent context (Figure 1). The research identifies this separation approach as a chief contributor to misjudging problem difficulty. When models are allowed to view all options simultaneously, improvements in accuracy are substantial, reducing perceived difficulty and closing the accuracy gap between ARC Challenge and ARC Easy by up to six-fold (Figure 2).
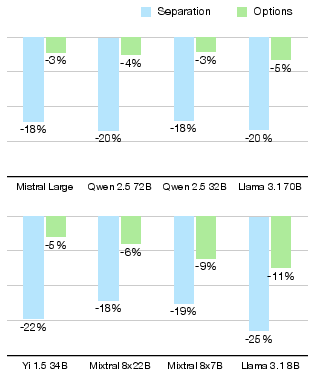
Figure 2: Difference between ARC Challenge and ARC Easy accuracies when considering each answer separately compared to seeing all options. The gap is vastly reduced, up to six times in this comparison.
Case Study: ARC Challenge
An in-depth analysis reveals that “hardly answerable in separation” questions are abundant in ARC datasets. This is evident as a significant portion of ARC questions necessitates comparative evaluation (e.g., determining the greatest mass among options). Such questions inherently demand a simultaneous evaluation setup to accurately capture the reasoning process. The model accuracy for ARC Challenge with Llama 3.1 70B leaps from 64% to 93% when transitioning to this more comprehensive evaluation context (Figure 3).
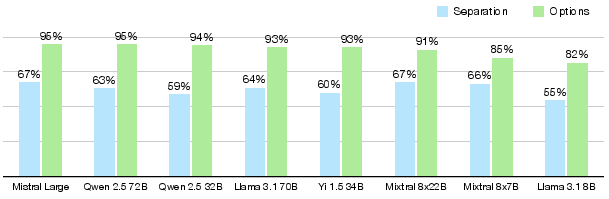
Figure 3: ARC Challenge evaluation results depending on whether the model sees other options or considers each answer separately. Differences reach up to 35%, and assumed setup impacts model rankings.
Broader Implications Beyond ARC
The ramifications of switching to an all-options methodology extend beyond the ARC dataset. For instance, OpenBookQA scores for Llama 3.1 70B rise from 48% to 89%, suggesting that many multi-choice benchmarks could be effectively "solved" by current models under an improved evaluation schema. Interestingly, OpenBookQA results show superhuman performance once all answer options are visible to models, underscoring how previous methodologies may have underestimated model capabilities (Figure 4).
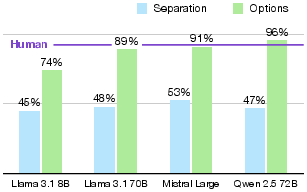
Figure 4: OpenBookQA evaluation results depending on whether the model sees other options or considers each answer separately. In a setup with options, current models outperform human test takers.
Recommendations for Evaluation Approaches
The paper urges a paradigm shift towards evaluation frameworks that reflect human-like reasoning, emphasizing the contextual coherence of answer options. Potential advantages include alignment with human evaluation methods, more authentic assessment of model capabilities, and the elimination of arbitrary methods for score normalization. However, challenges persist, such as the potential impact of option order on evaluation outcomes. Nevertheless, the benefits of this holistic approach seem to outweigh the drawbacks.
Conclusion
By revisiting the evaluation setup for multiple-choice benchmarks, this paper not only highlights the artificial nature of previously perceived task difficulty but also advocates for a more reliable assessment approach. As the community acknowledges these insights, the re-evaluation of benchmark methodologies is poised to narrow the gap between human and machine performance, promising more accurate reflections of model capabilities and setting a precedent for future AI evaluations.