DeepSeek-V3 Technical Report
Abstract: We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) LLM with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.

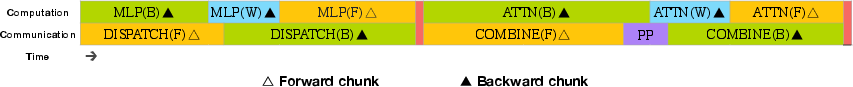


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces DeepSeek‑V3, a very large AI LLM. Think of it like a super smart writing and problem‑solving assistant. The team’s goal was to make it both powerful and affordable to train and use. They did this with clever design ideas that let the model work faster, use less memory, and cost less—without losing accuracy.
The main goals and questions
The researchers focused on a few clear goals:
- Can we build a huge open‑source model that rivals top closed models while costing much less to train?
- Can we make “mixture‑of‑experts” (a model made of many specialist mini‑models) work smoothly without wasting time or power?
- Can we train using lower‑precision numbers (FP8) to go faster and use less memory, but still keep accuracy?
- Can we teach the model to “plan ahead” by predicting several upcoming words at once to boost performance?
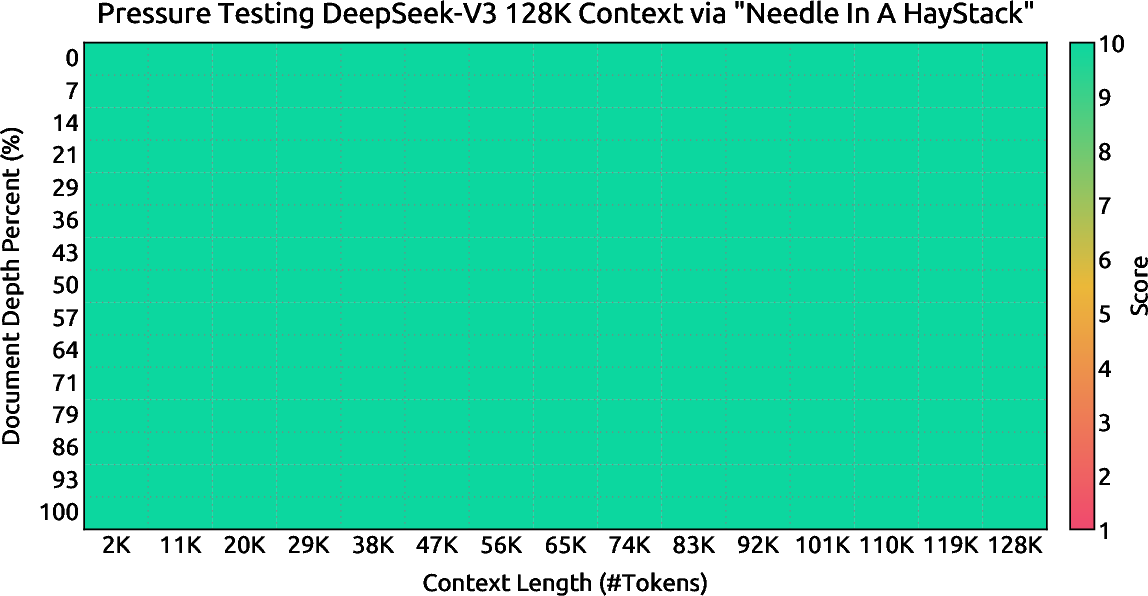
- Can we scale up training to massive data (14.8 trillion tokens) and super long inputs (up to 128,000 tokens) while keeping training stable?
How they did it (methods explained simply)
To reach those goals, they combined several ideas. Here’s what each means in everyday language:
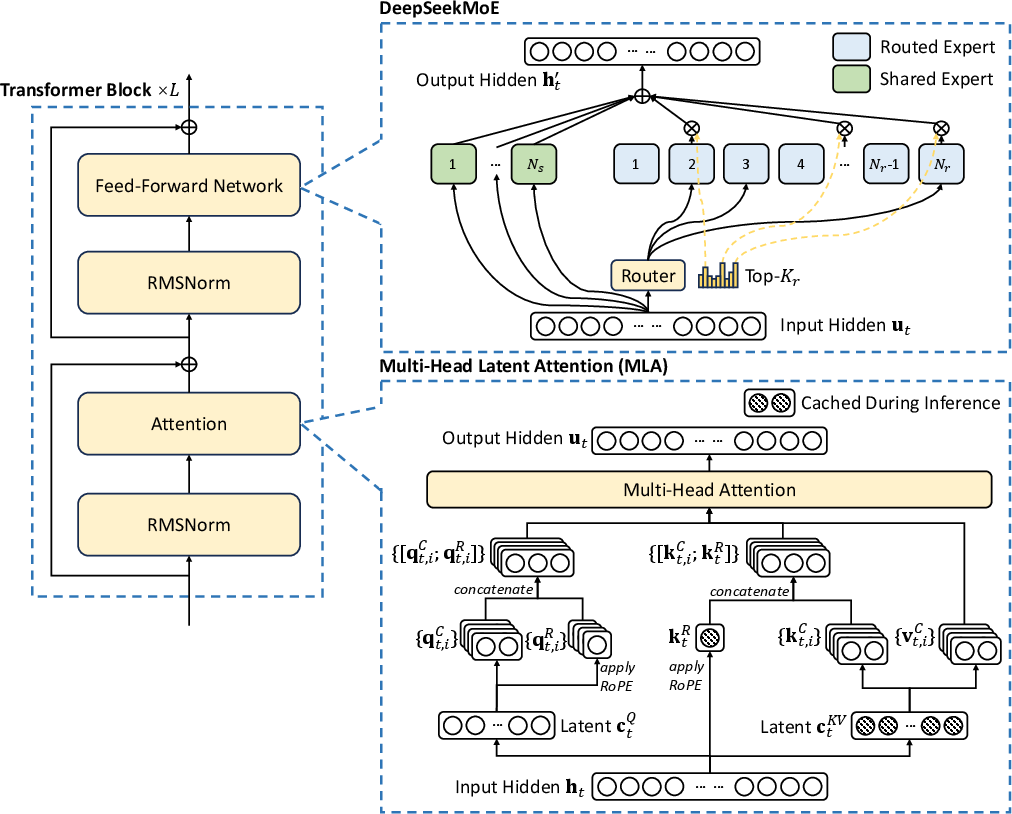
1) Mixture‑of‑Experts (MoE): a team of specialists
Instead of one giant brain doing everything, the model has many “experts,” each good at certain kinds of tasks. For every piece of text (a “token”), the system picks a few experts to handle it, like asking the right specialist for help. This saves time and makes the model smarter.
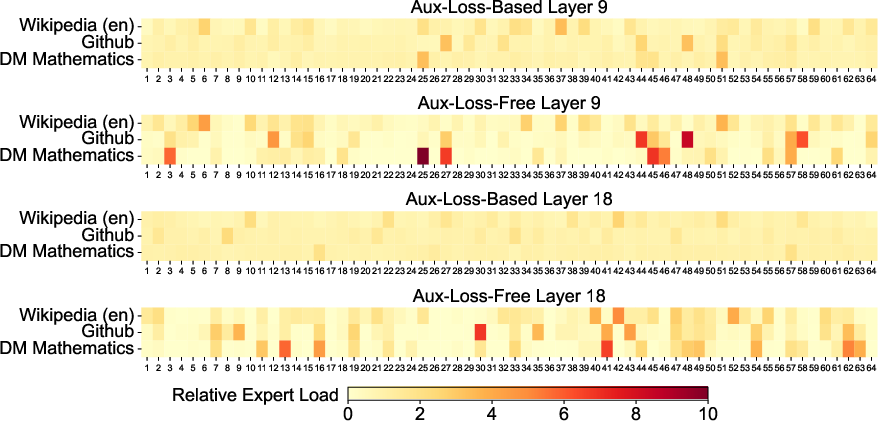
- Load balancing: They made sure no expert gets overloaded or ignored. Instead of punishing the model with extra “auxiliary losses” (which can hurt accuracy), they adjust a small “bias” for each expert to gently steer traffic where it’s needed—like a smart traffic light keeping cars moving evenly across lanes.
- Node‑limited routing: During training, tokens are allowed to travel to only a few machines (nodes). This keeps communication costs low and training fast.
- No token dropping: Because the traffic is well balanced, they don’t have to throw away tokens when things get busy.
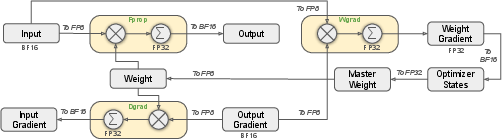
2) Multi‑head Latent Attention (MLA): keeping smaller “notes”
When the model pays attention to earlier words, it has to store “keys” and “values,” which are like notes about the past words. MLA compresses those notes so they’re much smaller—but still useful. That makes the model faster and cheaper to run, especially for long texts.
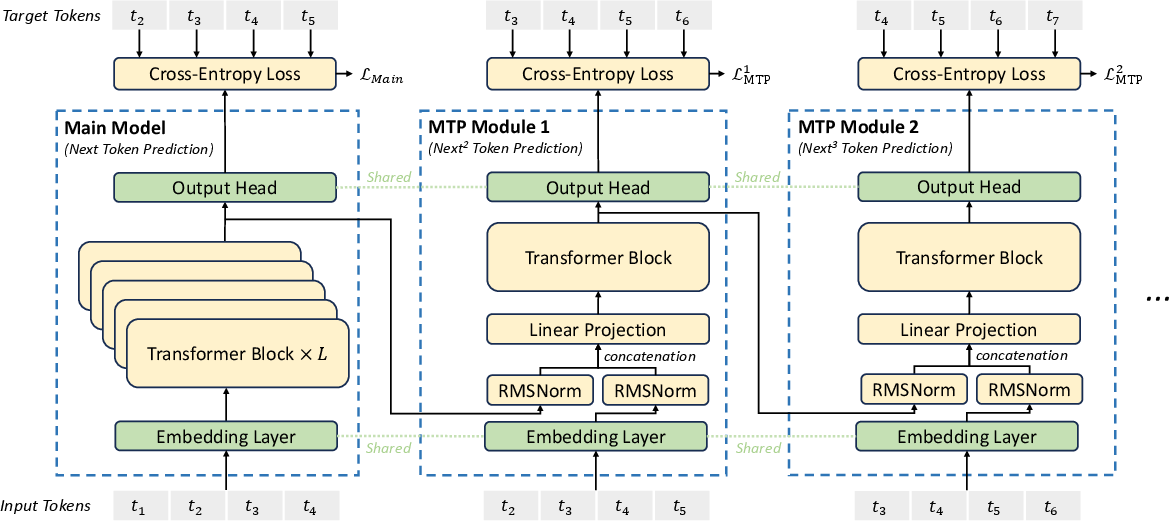
3) Multi‑Token Prediction (MTP): planning ahead
Usually, models learn to predict just the next word. This model also practices predicting the next several words in sequence. It’s like chess: don’t just think about the next move—think a few moves ahead. This gives the model stronger learning signals and can boost performance. These extra prediction modules can be turned off at runtime (or reused to speed up generation).
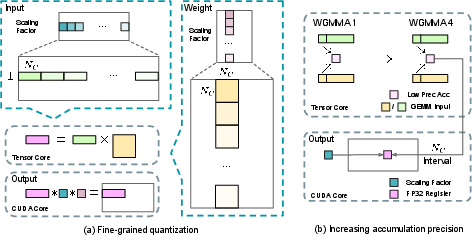
4) FP8 mixed‑precision training: lower‑resolution math, same picture
Computers store numbers with a certain number of bits. Using fewer bits (FP8) makes things faster and uses less memory—like lowering video resolution so it streams smoothly—but it can blur details. To keep the “picture” sharp:
- They use fine‑grained scaling, which treats small groups of numbers separately so outliers don’t mess things up.
- They do careful, higher‑precision “adding up” steps in the background so calculations stay accurate.
- Some sensitive parts (like the embedding layer, output head, and attention math) still use higher precision to stay stable.
5) Training at scale with smart scheduling (DualPipe)
Training a model across thousands of GPUs is like running a factory assembly line. DualPipe is their improved schedule that overlaps “thinking,” “talking to other machines,” and “learning from mistakes” so almost nothing sits idle. It hides slow communication by doing useful computing at the same time—like cooking the pasta while the sauce is simmering—so dinner is ready faster.
- They also wrote custom communication code to use their hardware’s fast connections (NVLink inside a machine and InfiniBand between machines) as efficiently as possible.
6) Data and post‑training
- They pre‑trained on 14.8 trillion tokens of high‑quality, diverse text.
- They extended the model’s memory (context length) in two steps: first to 32K tokens, then to 128K.
- After pre‑training, they did supervised fine‑tuning and reinforcement learning to better match human preferences.
- They distilled “reasoning” styles (like verify and reflect) from their DeepSeek‑R1 models into DeepSeek‑V3 without making the answers unnecessarily long.
What they found (key results and why they matter)
Here are the main takeaways:
- Strong performance: The base model is the strongest open‑source base model they tested, especially in coding and math.
- Competitive with top closed models: The chat version performs similarly to leading closed‑source models like GPT‑4o and Claude 3.5 Sonnet on many benchmarks.
- Great at knowledge tasks:
- High scores on academic tests like MMLU and MMLU‑Pro.
- Very strong factual knowledge, especially in Chinese.
- Excellent at coding and math:
- Top results on math benchmarks (even beating certain specialized models on some tests).
- Best on coding competition benchmarks like LiveCodeBench, and very strong on engineering tasks.
- Efficient and stable training:
- Full training took about 2.788 million H800 GPU hours. At $2/hour, that’s about$5.6 million—cheap for a model this size.
- Training was smooth: no big crashes or resets.
- FP8 training worked well at huge scale, with accuracy staying within normal randomness.
Why this matters (impact and what’s next)
- Cheaper, faster AI: The techniques (MLA, MoE load balancing without extra penalties, MTP, FP8 training, DualPipe scheduling) show we can train giant models more efficiently. That opens the door to more researchers and companies building powerful models without massive budgets.
- Better open‑source options: DeepSeek‑V3 narrows the gap with top closed models, giving the community strong, transparent tools for research and real‑world use.
- Smarter long‑context understanding: Handling up to 128K tokens means the model can read and reason over long documents, codebases, or transcripts more effectively.
- Practical reasoning: Distilling “verify and reflect” behaviors from a reasoning model helps V3 think more carefully without always producing very long answers.
- Hardware‑software co‑design: Their communication tricks and FP8 methods could inspire future GPU designs and training frameworks, making big models even more accessible.
In short, this paper shows how to build a huge, smart, and efficient AI model by combining many clever engineering and training ideas—making powerful AI more affordable and widely available.
Collections
Sign up for free to add this paper to one or more collections.

