- The paper introduces a Multi-Granularity Cross-Modal Alignment framework that leverages distribution, token, and instance alignment to improve multimodal emotion recognition.
- It utilizes Wav2Vec 2.0 and BERT for feature extraction and achieves state-of-the-art performance on the IEMOCAP dataset with WA of 78.87% and UA of 80.24%.
- Ablation studies demonstrate that each alignment module contributes uniquely to handling emotional ambiguity, enhancing human-computer interaction.
Enhancing Multimodal Emotion Recognition through Multi-Granularity Cross-Modal Alignment
Introduction
The domain of Multimodal Emotion Recognition (MER) integrates speech and text modalities to improve human-computer interaction. Traditional approaches in MER focus on unimodal systems, but to capture the full spectrum of emotional cues, a multimodal strategy is essential. Recent methods often fall short in aligning the diverse features from multiple modalities, typically employing a single-level alignment strategy, which limits performance. This paper introduces the Multi-Granularity Cross-Modal Alignment (MGCMA) framework, designed to address these challenges by employing distribution-based, instance-based, and token-based alignment modules.
Multi-Granularity Cross-Modal Alignment (MGCMA) Framework
The MGCMA framework enhances multimodal alignment by integrating multiple alignment strategies that operate at different levels of granularity. The framework consists of three key modules: distribution-based alignment, token-based alignment, and instance-based alignment, alongside a feature extractor.
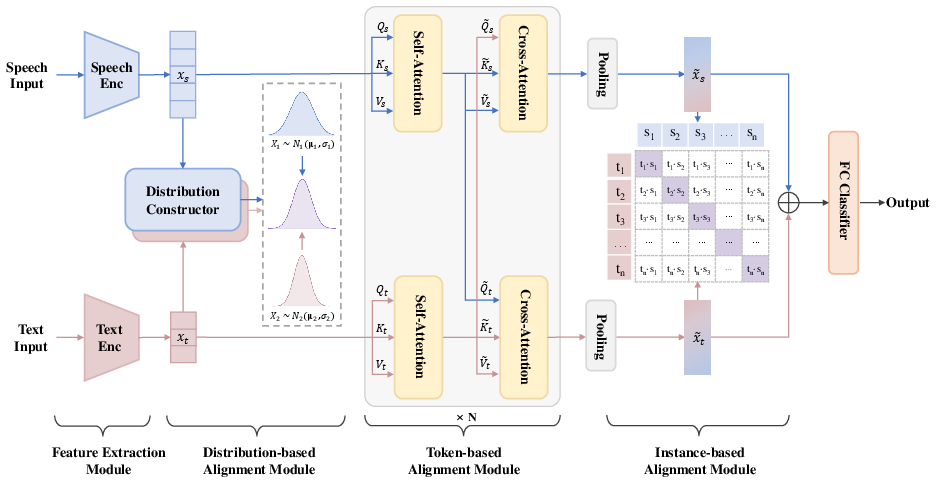
Figure 1: Overview of our proposed Multi-Granularity Cross-Modal Alignment (MGCMA) framework which comprises distribution-based, token-based, instance-based alignment modules, and a feature extractor.
High-level representations of the speech and text inputs are obtained using Wav2Vec 2.0 for audio and BERT for text sequences. These models provide a foundational encoding, critical for subsequent alignment processes.
Distribution-Based Alignment
Distribution-based alignment utilizes a constructor that forms multivariate Gaussian distributions of feature representations, thereby facilitating a higher-dimensional and coarse-grained alignment. By employing distribution-level contrastive learning, the module improves the robustness against the inherent ambiguity of emotional expressions.
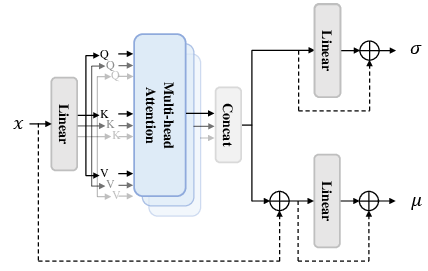
Figure 2: The structure of Distribution Constructor. Activation layers and normalization layers are omitted in the diagram.
Token-Based Alignment
Token-based alignment focuses on achieving fine-grained alignment through self-attention and cross-attention mechanisms, which allow for effective local interaction between modalities. This granularity enhances the exchange of emotional cues detected within speech and text.
Instance-Based Alignment
Instance-based alignment is implemented using contrastive learning to refine the correlation between specific speech-text pairs. This focuses on strengthening the mapping relationships after distribution and token-based alignments have been achieved, ensuring a holistic understanding across modalities.
Experimental Evaluation
The MGCMA framework was evaluated on the IEMOCAP dataset. Performance metrics include Weighted Accuracy (WA) and Unweighted Accuracy (UA).
Comparison with SOTA Methods
The proposed framework outperformed existing state-of-the-art MER methods. MGCMA achieved WA of 78.87% and UA of 80.24%, evidencing the effectiveness of the multi-level alignment approach.
Ablation Studies
A series of ablation studies highlight the individual contributions of each alignment module. Results indicate that the distribution-based alignment contributes significantly to enhancing overall performance by supporting token and instance alignment strategies.
Future Implications
This framework's ability to handle multimodal emotional ambiguity and maintain high accuracy demonstrates its potential in a wide range of practical applications in human-computer interaction systems. Future work could focus on optimizing computational efficiency without sacrificing the nuanced emotional insights provided by the multiscale alignment strategies.
Conclusion
The proposed MGCMA framework sets a new benchmark for MER by integrating distribution-based, token-based, and instance-based alignment modules to address the complexity of multimodal emotional expression. Its superior performance on the IEMOCAP dataset underscores the necessity of multi-grained alignment strategies, likely inspiring further research into adaptive, scalable emotion recognition systems.