- The paper introduces a novel LiDAR-camera fusion technique enhancing frame-to-frame consistency in video panoptic segmentation.
- It employs location-aware and time-aware queries to integrate spatial and temporal features without video-specific training.
- Experimental results show up to a five-point improvement in segmentation metrics on standard benchmarks like Cityscapes-vps.
LiDAR-Camera Fusion for Video Panoptic Segmentation without Video Training
Introduction
This paper investigates the integration of LiDAR and camera data for improving video panoptic segmentation (VPS) without relying on video-trained models. Panoptic segmentation, which combines instance and semantic segmentation tasks, is pivotal in the context of autonomous vehicles. While previous works have demonstrated the benefits of incorporating 3D data like LiDAR into image-based models, there is a dearth of research on its application to VPS. The primary contribution of this work is a feature fusion module that enhances segmentation performance through LiDAR-camera data integration. Notably, the model achieves competitive results without training on video datasets, showcasing an improvement in segmentation metrics by up to five points.
Panoptic Segmentation
Recent advances in panoptic segmentation have been driven by transformer-based approaches, such as Mask2Former, which employ object queries that offer strong discriminative properties. The model utilizes masked attention to focus on predicted segmentation regions, significantly enhancing the accuracy and efficiency of segmentation tasks over pixel-wise approaches.
Online Video Panoptic Segmentation
Most methods for VPS revolve around leveraging transformer queries to track objects across frames through bipartite matching, eschewing the need for video-specific training (1234.56789). This paper capitalizes on transformer-based techniques to build a video-free VPS model, differentiating from supervised models which often incorporate contrastive loss or memory banks for enhanced tracking performance.
LiDAR-Image Multimodal Learning
Fusing LiDAR with vision data has a long-standing history in improving object detection tasks. Research highlights the advantages of supplementing camera data with depth information to capture strong edge details, which enhances segmentation performance (2345.6789). However, prior studies primarily concentrated on semantic segmentation, thus underlining the novelty of the current work in its specific application to panoptic segmentation.
Methodology
The proposed methodology enhances both image and video panoptic segmentation by fusing LiDAR and image data. The model employs a transformer decoder to leverage object queries effectively, introducing two network modifications:
- Location-Aware Queries (LAQ): These queries employ an MLP network to predict segment positions, furnishing queries with spatial awareness to improve frame-to-frame matching.
- Time-Aware Queries (TAQ): Extends the queries from previous frames to the current frame during evaluation, improving continuity and accuracy across frames.
The model architecture and fusion strategy, as shown in Figure 1, combine image and depth features through a novel dynamic weighting mechanism. This improves segmentation by dynamically deciding the contribution of depth data relative to image features.
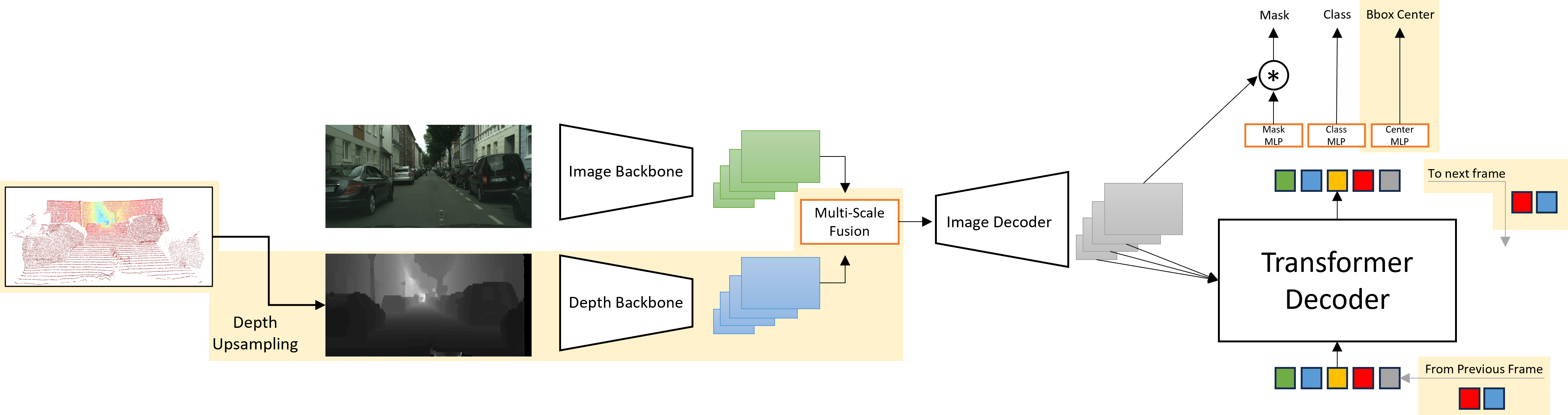
Figure 1: Overall architecture of the proposed method, which is based on Mask2Former.
Experimentation and Results
Dataset and Training
The Cityscapes dataset is used for training the model for panoptic segmentation tasks, while video segmentation is evaluated on the Cityscapes-vps [3456.7890]. The LiDAR data is simulated due to dataset limitations, and the model trains using modified depth information.
The fusion of LiDAR and image data enhances segmentation accuracy, especially in object segmentation tasks. The experiments confirm that dynamic weighting significantly outperforms simple addition of features, yielding a notable improvement in segmentation quality (Table 1).
Video Panoptic Segmentation Results
Table 2 showcases the improvements achieved by the proposed model over the baseline Mask2Former in VPS metrics. Incorporating LAQ and TAQ yields performance gains that narrow the gap between video-free and video-supervised models. Notably, the model excels in "things" segmentation, underlining its utility in applications requiring detailed object tracking.

Figure 2: Panoptic segmentation output for a video sequence. The base model (left) shows significant ID switches compared to our proposed method (right).
Conclusion
The research delivers a robust framework for LiDAR-camera integration in VPS, highlighting the feasibility of achieving high performance without the need for video-based training. Despite currently lagging behind video-supervised counterparts, the substantial improvements in segmentation accuracy underscore the model's potential for autonomous vehicle applications. Future work should explore scaling the approach for larger batches and employing advanced fusion techniques to further improve results.