- The paper introduces LLaVA-Mini, a multimodal model that compresses vision tokens into a single token with minimal performance loss.
- It utilizes a query-based compression and modality pre-fusion strategy to retain key visual features, achieving a 77% reduction in FLOPs and sub-40 ms latency.
- The model demonstrates competitive performance across 18 benchmarks, enabling real-time processing on standard GPU hardware.
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
Introduction
The paper "LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token" introduces a new approach to developing efficient large multimodal models (LMMs) that drastically reduce the computational resources required to process visual inputs. The proposed LLaVA-Mini framework compresses the information derived from vision tokens down to a single token without a significant performance drop, thus offering a major reduction in computational overhead. This model stands out for its ability to maintain high accuracy in visual understanding tasks while drastically cutting down on the number and complexity of vision tokens, which has been a persistent challenge for real-time LMM applications.
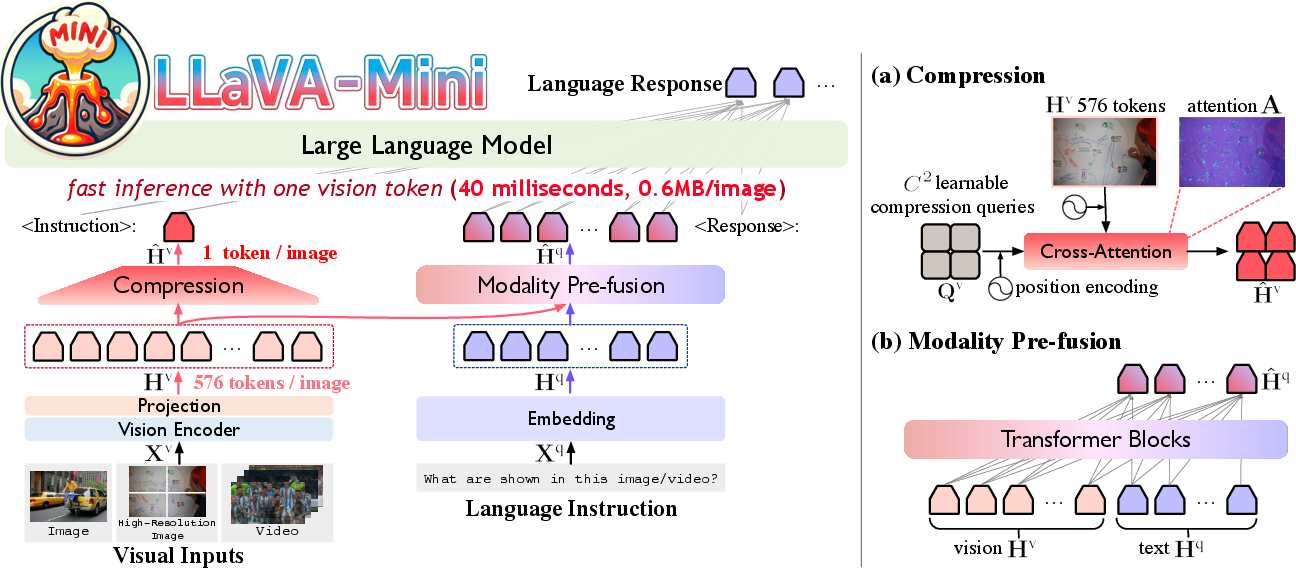
Figure 1: Architecture of LLaVA-Mini. Left: LLaVA-Mini represents each image with one vision token. Right: Detailed view of the proposed query-based compression and modality pre-fusion.
Theoretical Insights and Compression Strategy
The paper begins by examining how visual tokens are processed within LLaVA models and finds that their importance is highest during the initial stages of processing in LLMs. Consequently, most attention shifts away from vision tokens in deeper layers. To capitalize on this insight, LLaVA-Mini introduces a modality pre-fusion module that combines visual and textual data before inputting it into the LLM. This fusion allows for an extreme compression of the number of vision tokens, which are then transformed into a single, information-rich token.
The query-based compression module plays a vital role in this framework, selectively retaining critical visual features through learned queries that enable focus on essential image areas, thus minimizing the loss of significant visual data even with substantial reduction.
Conducted experiments across 18 benchmarks, including both image-based and video-based understanding tasks, reflect the efficacy of LLaVA-Mini. In comparison to its predecessor, LLaVA-v1.5, LLaVA-Mini maintains competitive performance metrics while utilizing only 0.17% of the original vision tokens count. This results in a substantial reduction in FLOPs by 77% and enhances real-time processing capabilities with a latency under 40 ms, permitting LMMs to deliver low-latency responses suitable for interactive applications.
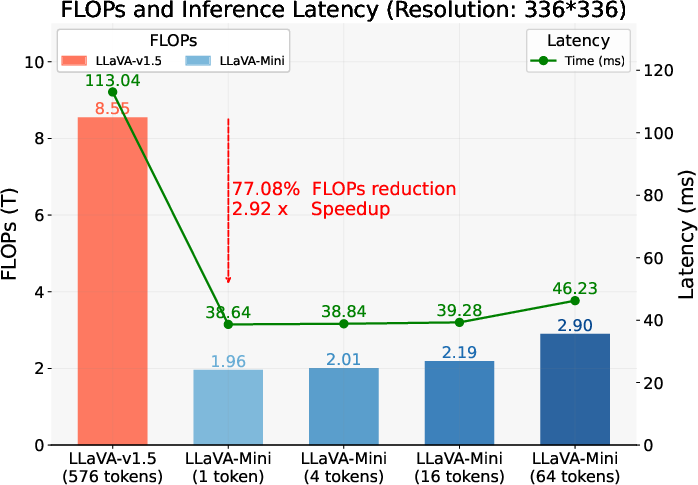
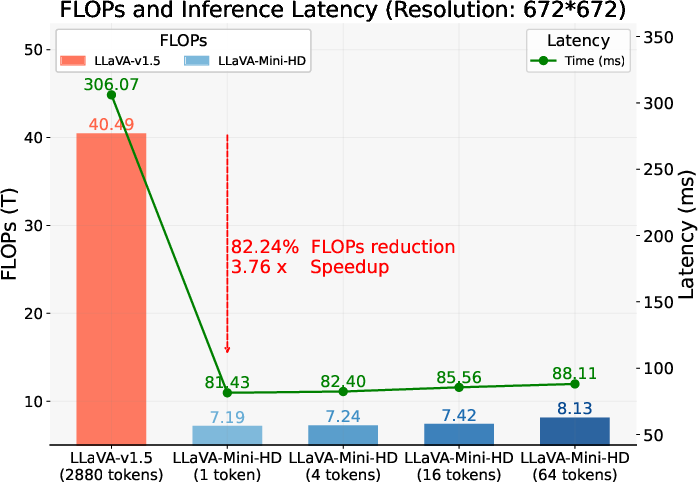
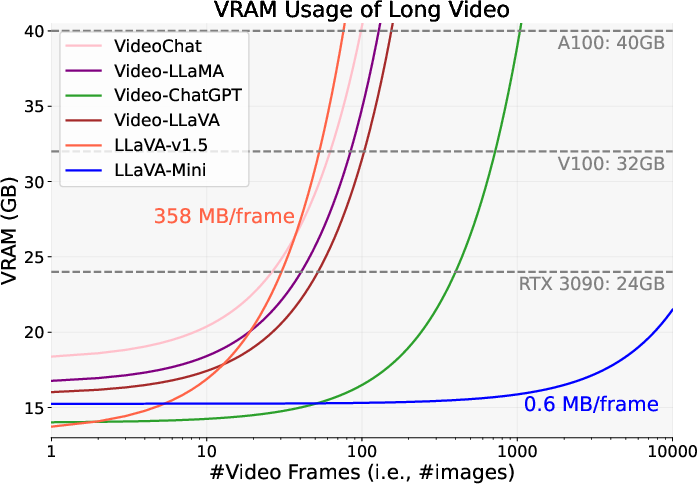
Figure 2: FLOPs and latency of LLaVA-Mini.
Significant improvements in handling high-resolution images and extended video sequences further exemplify the utility of LLaVA-Mini. By efficiently compressing and processing visual inputs, the model allows for the practical deployment of LMMs on hardware with limited computational capacity, such as standard GPU setups.
Implications and Future Directions
The implementation of LLaVA-Mini represents a significant step towards achieving efficient and scalable LMMs capable of real-time, multimodal interactions. By reducing the number of vision tokens required for visual understanding tasks, the model offers significant potential in applications spanning from automated customer service interfaces to real-time video analytics. The integration of modality pre-fusion and query-based compression provides a robust framework adaptable to future advancements in LLMs.
This work opens new avenues for research in multimodal AI, prompting further investigation into adaptive tokenization strategies and their impact on computational efficiency and model performance. Subsequent efforts could explore the dynamic tuning of token compression parameters based on varying task requirements and resource availability, thus enabling more customized and optimized models for diverse operational contexts.
Conclusion
LLaVA-Mini demonstrates that through strategic token compression and pre-fusion, it's possible to maintain high performance with significantly reduced computational costs. This advancement not only facilitates more efficient deployment of AI models in practice but also sets a precedent for future innovations focusing on maximizing efficiency without sacrificing accuracy or applicability in diverse multimodal scenarios. The research incorporates effective design principles making it a transformative contribution to the field of efficient AI model development.