- The paper introduces an FPGA accelerator that employs low-rank tensor compression to significantly reduce memory and computational demands during transformer training.
- The innovative bi-directional tensor contraction method minimizes sequential operations, enhancing parallelism and computational efficiency.
- The hardware implementation achieves a 30-51x reduction in memory usage and a fourfold decrease in energy consumption compared to GPU-based training.
Introduction
The paper presents an FPGA accelerator tailored for training transformer models using low-rank tensor compression. This work addresses the computational and memory constraints typically associated with transformer models, enabling their training on resource-constrained devices such as FPGAs. Specifically, the research introduces a bi-directional contraction flow to minimize FLOPs and intra-layer memory requirements during tensorized transformer training. Custom computing kernels and on-chip memory storage further enhance the accelerator's efficacy. The system demonstrates significant memory and energy savings compared to traditional training methods on GPUs.
The accelerator leverages the inherent structure of transformers, employing tensor decompositions to reduce the dimensionality and storage requirements of the weight matrices (Figure 1). Transformer models, primarily composed of self-attention layers and feed-forward networks, benefit from the tensor-train (TT) and tensor-train-matrix (TTM) formats to compress and store parameters efficiently. These formats replace standard matrix operations with tensor contractions, which significantly decrease both on-chip memory usage and computational costs.

Figure 1: Transformer structure for classification tasks. Inter-layer activation is represented using yellow blocks, embedding tables and linear layer weights are in purple blocks, and non-linear functions are in white blocks.
Bi-directional Contraction Scheme
The innovative bi-directional tensor-train (BTT) contraction method enhances computation efficiency by reducing the number of sequential contraction steps required in tensor operations (Figure 2). Traditional methods adopt a right-to-left contraction sequence, which limits parallelism. By employing BTT, the accelerator achieves substantial improvements in computational complexity and memory efficiency. These enhancements are achieved by concurrently contracting left and right tensors towards the middle, thus reducing the computational stages from $2d$ to d+1.
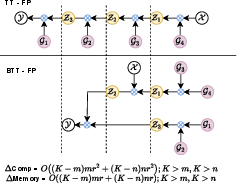
Figure 2: Comparison of the computing flow of the TT-format and our modified BTT forward propagation when d=2. Contraction operations are represented in blue multipliers. Here white nodes represent input tensor X and output tensor Y.
Key Hardware Implementation
The FPGA implementation integrates a memory management strategy that optimizes on-chip memory usage by grouping tensor cores to maximize BRAM utilization (Figure 3). The accelerator supports tensor-compressed forward and backward propagation, facilitated by the innovative dataflow and kernel execution schemes. This strategy, alongside pipelining and kernel fusion, enhances the parallelism of tensor operations and reduces overall latency.
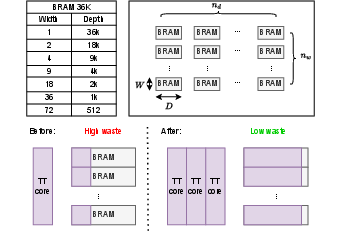
Figure 3: Configurations of BRAM 36K. Number of BRAM of one array. BRAM usage efficiency before and after tensor grouping.
Experiments demonstrate that the FPGA accelerator achieves a memory reduction factor of 30 to 51 times compared to uncompressed training on an NVIDIA RTX 3090 GPU, with a fourfold decrease in energy consumption per training epoch (Figure 4). These metrics underline the practical viability of deploying large-scale tensorized neural networks on edge devices without the prohibitive energy and memory footprints of conventional approaches.
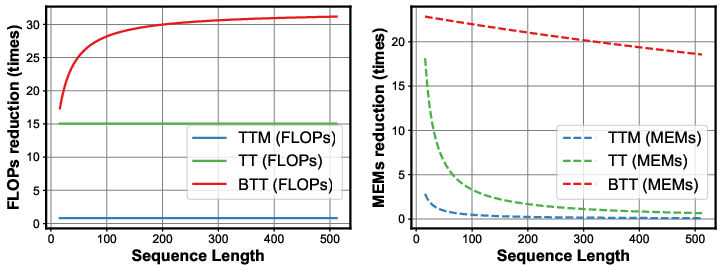
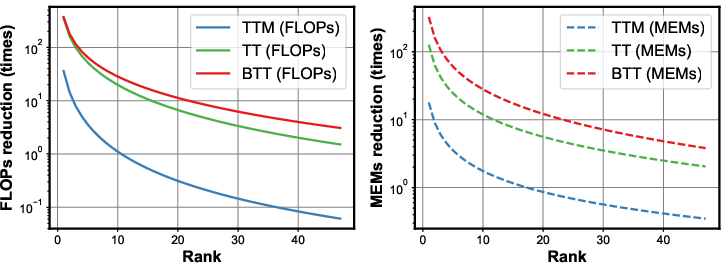
Figure 4: Computational and memory costs of TTM-based contraction, TT-based contraction and our BTT-based contraction corresponding to different sequence lengths (top) and ranks (bottom).
Conclusion
This study effectively demonstrates the potential of low-rank tensor compression for on-FPGA training of transformer models. By addressing both computational and memory constraints, the proposed accelerator bridges the gap between high-efficiency training and edge deployment, paving the way for future research in tensor-based model optimization on resource-limited platforms. The preliminary results encourage further exploration into scaling these techniques to more complex models and real-world applications.