- The paper's main contribution is the introduction of a multi-task aware prompt optimization framework that dynamically selects metrics based on task type.
- It employs evolutionary strategies with tournament selection to iteratively refine prompts, yielding superior performance over baseline methods.
- Empirical results on diverse datasets and models demonstrate TAPO's versatility and effectiveness in enhancing complex LLM tasks.
TAPO: Task-Referenced Adaptation for Prompt Optimization
The paper "TAPO: Task-Referenced Adaptation for Prompt Optimization" presents a novel framework for enhancing the performance of automated prompt optimization in LLMs. This framework addresses the shortcomings of existing prompt optimization approaches by incorporating task-specific characteristics. TAPO introduces a multitask-aware prompt optimization framework through three integrated modules that improve the adaptability of prompts across diverse tasks.
Introduction and Motivation
Prompt engineering is critical for leveraging the full potential of LLMs. Manual prompt design is labor-intensive, prompting the need for automated prompt optimization (APO). Current methods like TEMPERA and others predominantly rely on singular metrics, limiting their generalizability across various tasks. Moreover, these approaches often lack the versatility required for effective multi-task optimization. The TAPO framework seeks to address these issues by dynamically selecting task-specific metrics and automating the evaluation and optimization of prompts for enhanced performance in diverse environments.
Methodology
Framework Overview
TAPO's framework effectively integrates LLMs into its core components of task identification, metric selection, and prompt optimization. By employing a multi-objective optimization strategy, TAPO adapts to various tasks, choosing relevant metrics and refining prompts iteratively through an adaptive feedback loop (Figure 1). This flexibility ensures task-specific performance improvements through dynamic adaptation.
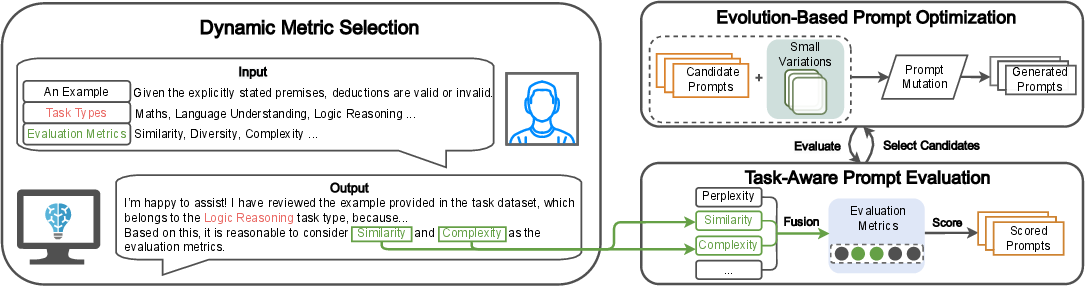
Figure 1: The framework of TAPO, showcasing Dynamic Metric Selection, Task-Aware Prompt Evaluation, and Evolution-Based Prompt Optimization.
Dynamic Metric Selection
The TAPO framework begins with classifying the task type and selecting suitable evaluation metrics and their weights. This task-aware selection process permits evaluations based on task attributes, such as similarity for factual tasks or diversity for creative tasks. Metrics including complexity and perplexity are tailored to capture the nuances of diverse task requirements.
Task-Aware Prompt Evaluation
TAPO uses a comprehensive evaluation module that combines the selected metrics into a scoring function. This function—comprising weighted metrics—evaluates prompts in terms of accuracy, fluency, and other criteria, facilitating dynamic adjustments according to task requirements:
S(P)=i=1∑nwi⋅Mi(P)
Evolution-Based Prompt Optimization
Traditional methods often falter at local optima. TAPO counters this by employing evolutionary strategies, iteratively mutating and selecting high-performing prompts for continuous improvement. Using a tournament selection mechanism, TAPO refines prompts until they meet specified performance benchmarks.
Experimentation and Results
Extensive experiments conducted on diverse datasets validate TAPO's effectiveness. TAPO demonstrated superior performance in tasks like arithmetic reasoning and multi-step problem-solving, consistently surpassing baseline approaches. It achieved significant gains in similarity scores across challenging datasets (Table 1).
Component Analysis
The ablation study indicates that each component of TAPO, such as prompt optimization and dynamic metric selection, crucially contributes to its overall performance (Table 2). Removing specific components resulted in noticeable performance declines, underscoring their importance.
Open-Source Model Applicability
TAPO was also tested on open-source LLMs like Llama3, where it significantly improved performance, demonstrating enhanced flexibility and efficacy across different architectural frameworks (Figure 2).
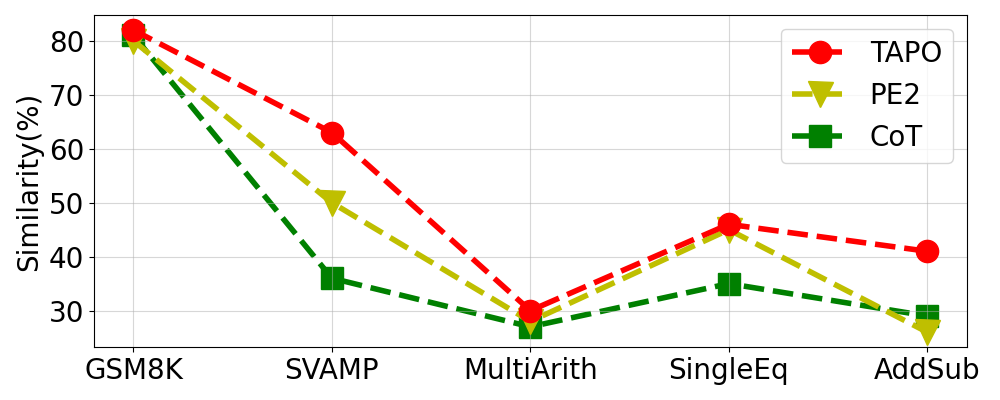
Figure 2: Performance Comparison with Llama3, illustrating TAPO's robustness across different models.
Conclusion
TAPO presents a robust framework for prompt optimization that emphasizes task adaptability and iterative enhancement. By dynamically selecting metrics and refining prompts, TAPO outperforms existing methods, broadening the generalization of LLMs across diverse tasks. This work lays groundwork for future exploration into more adaptive and dynamic APO strategies that cater to an evolving range of AI tasks and applications.